这是 CSAPP 书中的最后 1 个 Lab,上一个 Malloc Lab 我感觉刷高分比较麻烦,就先鸽了,遂先完成了这个
本实验是要求实现一个带缓存的多线程代理服务器,分为三个部分:
- Part 1:实现一个最基础的顺序代理
- Part 2:进一步优化,使代理支持多线程(生产者-消费者模型)
- Part 3:使用 LRU 策略缓存 Web 中的对象(读者-写者模型)
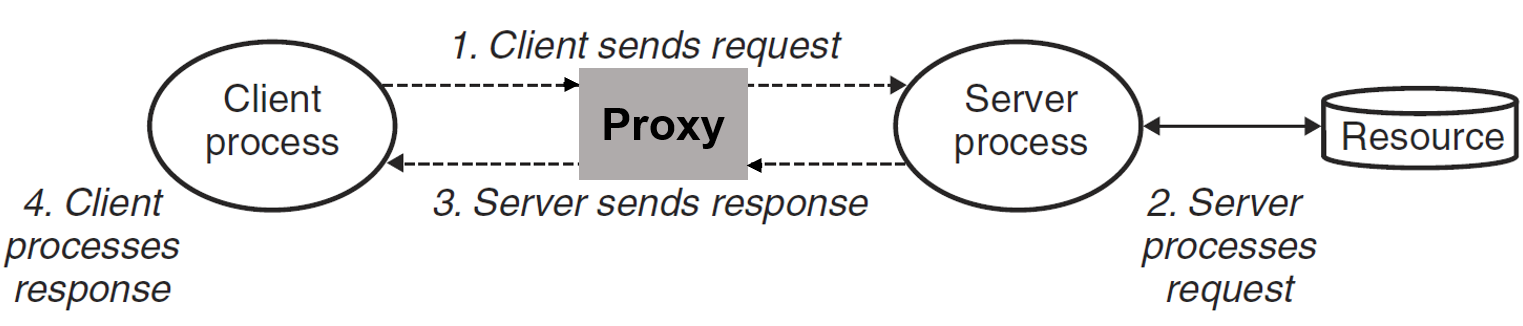
实现思路简析
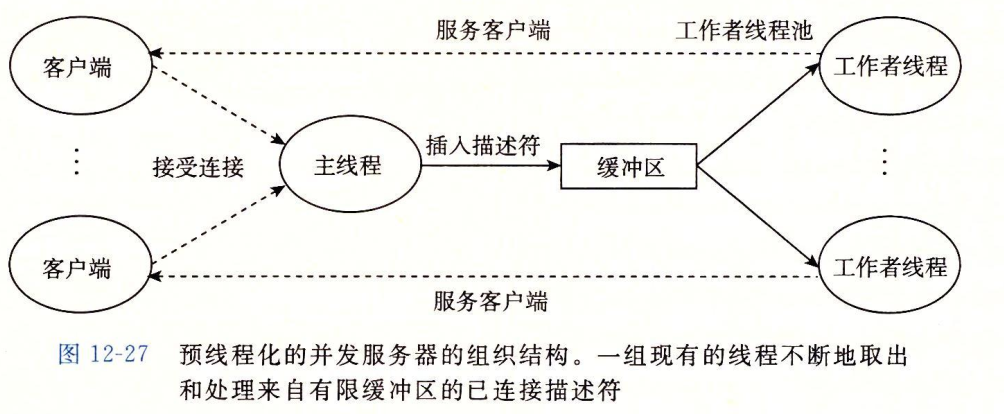
预线程化的并发服务器
一种平凡的思路是每次建立一个新连接就创建一个新线程,但反复创建和销毁线程会引起不必要的开销。因此这里我我采用 CSAPP 12.5.5 提到的基于预线程化(prethreading)的并发技术。每一个工作着线程反复地从共享缓冲区中取出描述符,为客户端服务,然后等待下一个描述符。
主函数代码如下:
// Create threads
pthread_t tid;
for (int i = 0; i < THREAD_NUM; ++i) {
Pthread_create(&tid, NULL, mythread, NULL);
}
// Infinite loop to accept connections
struct sockaddr_storage clientaddr;
socklen_t clientlen = sizeof(struct sockaddr_storage);
char host[MAXLINE], port[MAXLINE];
while (1) {
int connfd = Accept(listenfd, (struct sockaddr *)&clientaddr, &clientlen);
sbuf_insert(&sbuf, connfd);
Getnameinfo((struct sockaddr *)&clientaddr, clientlen, host, MAXLINE, port, MAXLINE, 0);
printf("Accept connection from %s:%s\n", host, port);
}线程代码如下:
Pthread_detach(Pthread_self()); 的作用是分离线程,一个分离的线程在结束时会自动释放其资源,不需要其他线程来进行回收。
// Thread routine: get request from sbuf, solve it and close connection
void *mythread(void *arg) {
Pthread_detach(Pthread_self());
while (1) {
int connfd = sbuf_remove(&sbuf);
Solve(connfd);
Close(connfd);
}
pthread_exit(NULL);
}构建 HTTP Header
根据文档的要求,我们的代理服务器会收到类似这样的请求:
GET http://www.cmu.edu/hub/index.html HTTP/1.1我们需要从 URL 中提取出 Host 字段,把 URL 转换成 URI,再统一改成 HTTP/1.0 版本,
GET /hub/index.html HTTP/1.0关于 GET 后面究竟应该是 URL 还是 URI ?ChatGPT 给出的回答如下:
在 HTTP 请求报文中,GET 方法后面应该跟的是 URI,而不是完整的 URL。这是因为 HTTP 请求报文是在已经建立的 TCP 连接上发送的,这个连接已经指定了服务器的地址和端口,所以在 HTTP 请求报文中不需要再次指定服务器的地址。需要注意的是,虽然在大多数情况下,HTTP 请求报文中使用的是相对 URI,但在某些情况下,例如在 HTTP 代理请求中,可能会使用完整的 URL。
但现在实际的 HTTP 代理中,往往会使用 CONNECT 方法,而我们这个 Lab 只要求实现 GET 方法,要想用通过这个代理服务器来浏览网页还是很难的。
另外根据文档,以下字段是固定的:
Connection: close
Proxy-Connection: close
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:10.0.3) Gecko/20120305 Firefox/10.0.3在实现过程中,使用了 C 语言字符串库函数 strcasecmp 和 strncasecmp,它们可以比较字符串是否相等(忽略大小写模式),后者可以指定比较的最大字符数量
代码如下:
// Build http header
void build_header(char *http_hdr, URL *url, rio_t *rio_p) {
static char *conn_hdr = "Connection: close\r\n";
static char *proxy_hdr = "Proxy-Connection: close\r\n";
char host_hdr[MAXLINE], method_hdr[MAXLINE], buf[MAXLINE], other_hdr[MAXLINE];
sprintf(host_hdr, "Host: %s\r\n", url->host);
sprintf(method_hdr, "GET %s HTTP/1.0\r\n", url->uri);
int cnt = 0;
while (Rio_readlineb(rio_p, buf, MAXLINE) > 0) {
if (!strcmp(buf, "\r\n")) break;
if (!strncasecmp(buf, "Host:", 5)) {
strcpy(host_hdr, buf);
} else
if (strncasecmp(buf, "Connection:", 11) && strncasecmp(buf, "Proxy-Connection:", 17) && strncasecmp(buf, "User-Agent:", 11)){
cnt += sprintf(other_hdr + cnt, "%s", buf);
}
}
sprintf(http_hdr, "%s%s%s%s%s%s\r\n", method_hdr, host_hdr, conn_hdr, proxy_hdr, user_agent_hdr, other_hdr);
}缓存设计
文档要求如果一个请求对象的大小不超过 MAX_OBJECT_SIZE(100KiB),那么代理服务器需要将请求对象缓存。总缓存大小是 MAX_CACHE_SIZE(1MiB)。采用 LRU 置换算法(最近最久未使用)。读命中和写都算一次缓存命中,更新 LRU 标记。
缓存允许多个线程同时读,但互斥写,也只允许最多 1 个线程写。这恰好是读者——写者问题,我通过 4 个函数 read_lock, read_unlock, write_lock, write_unlock 封装了读写加锁的操作,从而简化代码编写。
为了提供缓存查找的速度,我采用了简单的哈希算法。每个 (Host, Port, URI) 唯一映射到一个缓存,通过哈希 (Host, Port, URI),在缓存查找的时候先比较哈希值是否相同,不同则一定不匹配。
代码如下:
const uint32_t base = 31;
typedef struct {
char obj[MAX_OBJECT_SIZE], host[MAXLINE], port[MAXLINE], uri[MAXLINE];
uint32_t hashval, LRU, read_cnt;
int empty;
size_t size;
sem_t w, mutex;
}Cache;
Cache cache[CACHE_NUM];
sem_t t_mutex;
uint64_t timestamp;
// Initialize cache
void cache_init() {
Sem_init(&t_mutex, 0, 1);
for (int i = 0; i < CACHE_NUM; ++i) {
cache[i].empty = 1;
Sem_init(&cache[i].w, 0, 1);
Sem_init(&cache[i].mutex, 0, 1);
}
}
// Lock read lock
void read_lock(int i) {
P(&cache[i].mutex);
if (++cache[i].read_cnt == 1)
P(&cache[i].w);
V(&cache[i].mutex);
}
// Unlock read lock
void read_unlock(int i) {
P(&cache[i].mutex);
if (--cache[i].read_cnt == 0)
V(&cache[i].w);
V(&cache[i].mutex);
}
// Lock write lock
void write_lock(int i) {
P(&cache[i].w);
}
// Unlock write lock
void write_unlock(int i) {
V(&cache[i].w);
}
// Get timestamp which is used to implement LRU
uint64_t get_timestamp() {
P(&t_mutex);
int ret = ++timestamp;
if (ret == 0) {
for (int i = 0; i < CACHE_NUM; ++i) {
read_lock(i);
cache[i].LRU = 0;
read_unlock(i);
}
ret = ++timestamp;
}
V(&t_mutex);
return ret;
}
// Find in cache, return index if hit, -1 otherwise
int cache_find(URL *url) {
int ret = -1;
for (int i = 0; i < CACHE_NUM; ++i) {
read_lock(i);
if (cache[i].empty || cache[i].hashval != url->hashval) {
read_unlock(i);
continue;
}
if (!strcmp(url->host, cache[i].host) && !strcmp(url->port, cache[i].port) && !strcmp(url->uri, cache[i].uri)) {
cache[i].LRU = get_timestamp();
ret = i;
// read_unlock(i);
break;
}
read_unlock(i);
}
return ret;
}
// Insert into cache
void cache_insert(URL *url, char *cache_s, size_t size) {
uint64_t minv = UINT64_MAX; int idx = -1;
for (int i = 0; i < CACHE_NUM; ++i) {
read_lock(i);
if (cache[i].empty) {
idx = i;
read_unlock(i);
break;
}
if (cache[i].LRU < minv) {
minv = cache[i].LRU;
idx = i;
}
read_unlock(i);
}
Assert(idx != -1);
write_lock(idx);
cache[idx].empty = 0;
cache[idx].hashval = url->hashval;
strcpy(cache[idx].host, url->host);
strcpy(cache[idx].port, url->port);
strcpy(cache[idx].uri, url->uri);
memcpy(cache[idx].obj, cache_s, size);
cache[idx].size = size;
cache[idx].LRU = get_timestamp();
write_unlock(idx);
}
// Calculate hash value of url
void get_hash(URL *url) {
uint32_t hashval = 0;
int n = strlen(url->host);
for (int i = 0; i < n; ++i)
hashval = hashval * base + (uint32_t)url->host[i];
n = strlen(url->port);
for (int i = 0; i < n; ++i)
hashval = hashval * base + (uint32_t)url->port[i];
n = strlen(url->uri);
for (int i = 0; i < n; ++i)
hashval = hashval * base + (uint32_t)url->uri[i];
url->hashval = hashval;
}错误处理
感觉这是最讨厌最麻烦的东西,因为编写服务器代码需要代码有很高的健壮性,即使出现了错误,也不应该立即退出。我做的也不是很好,实在不想费劲地每一个操作后都 if 检查返回值

为此我定义了一个宏,当出错/不符合预期时立刻打印出错代码的函数和行数,并立即返回
#define Assert(expression) if (!(expression)) { printf("Assertion failure in %s, line %d\n", __FUNCTION__, __LINE__); return; }此外,为了不让出错后退出,我把 csapp.c 中的 exit(0) 均注释掉了
void unix_error(char *msg) /* Unix-style error */
{
fprintf(stderr, "%s: %s\n", msg, strerror(errno));
// exit(0);
}
/* $end unixerror */
void posix_error(int code, char *msg) /* Posix-style error */
{
fprintf(stderr, "%s: %s\n", msg, strerror(code));
// exit(0);
}
void gai_error(int code, char *msg) /* Getaddrinfo-style error */
{
fprintf(stderr, "%s: %s\n", msg, gai_strerror(code));
// exit(0);
}测试环节
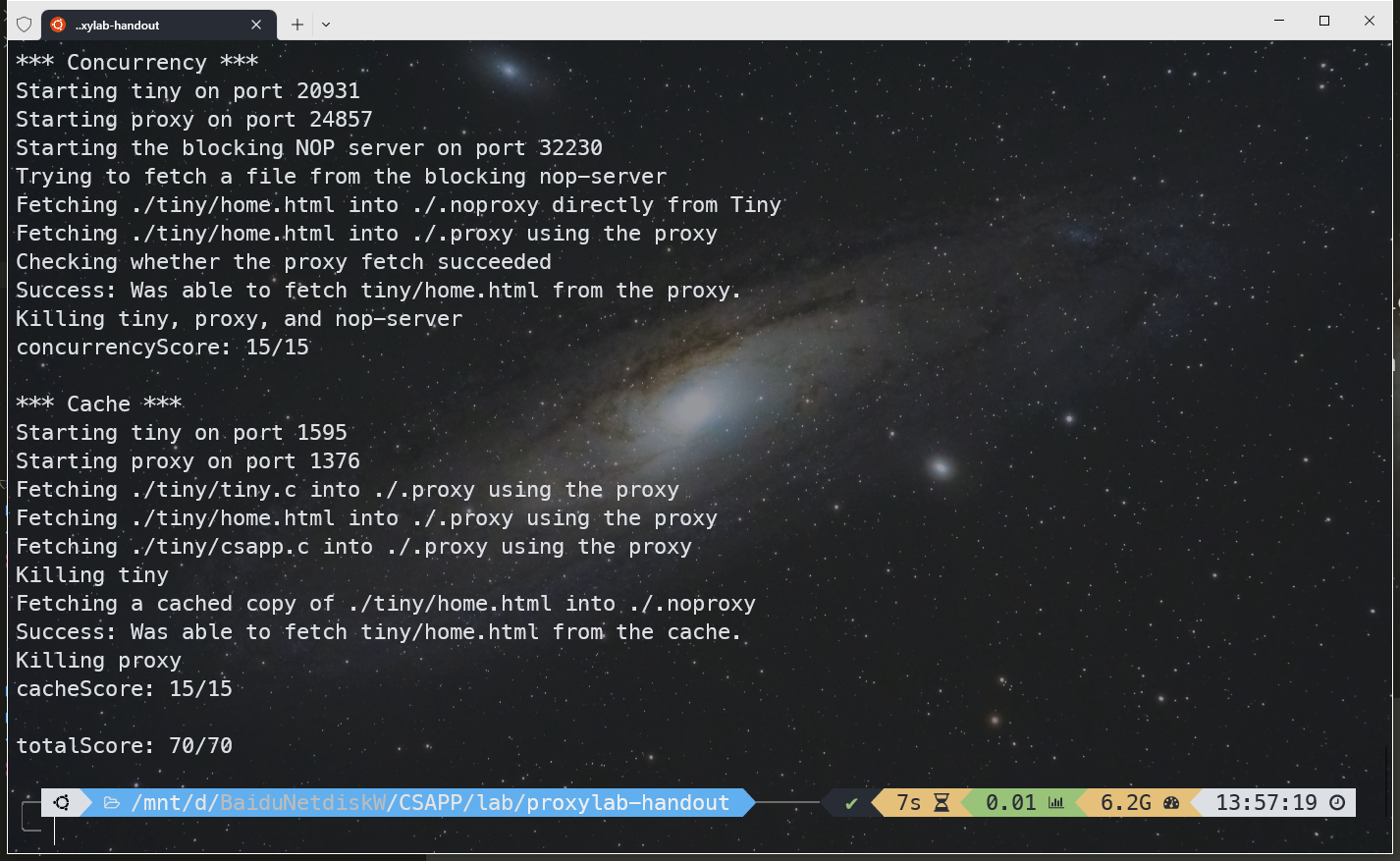
完成 Part I-II 后的实验跑分测试,成功拿到 55/70 的分数
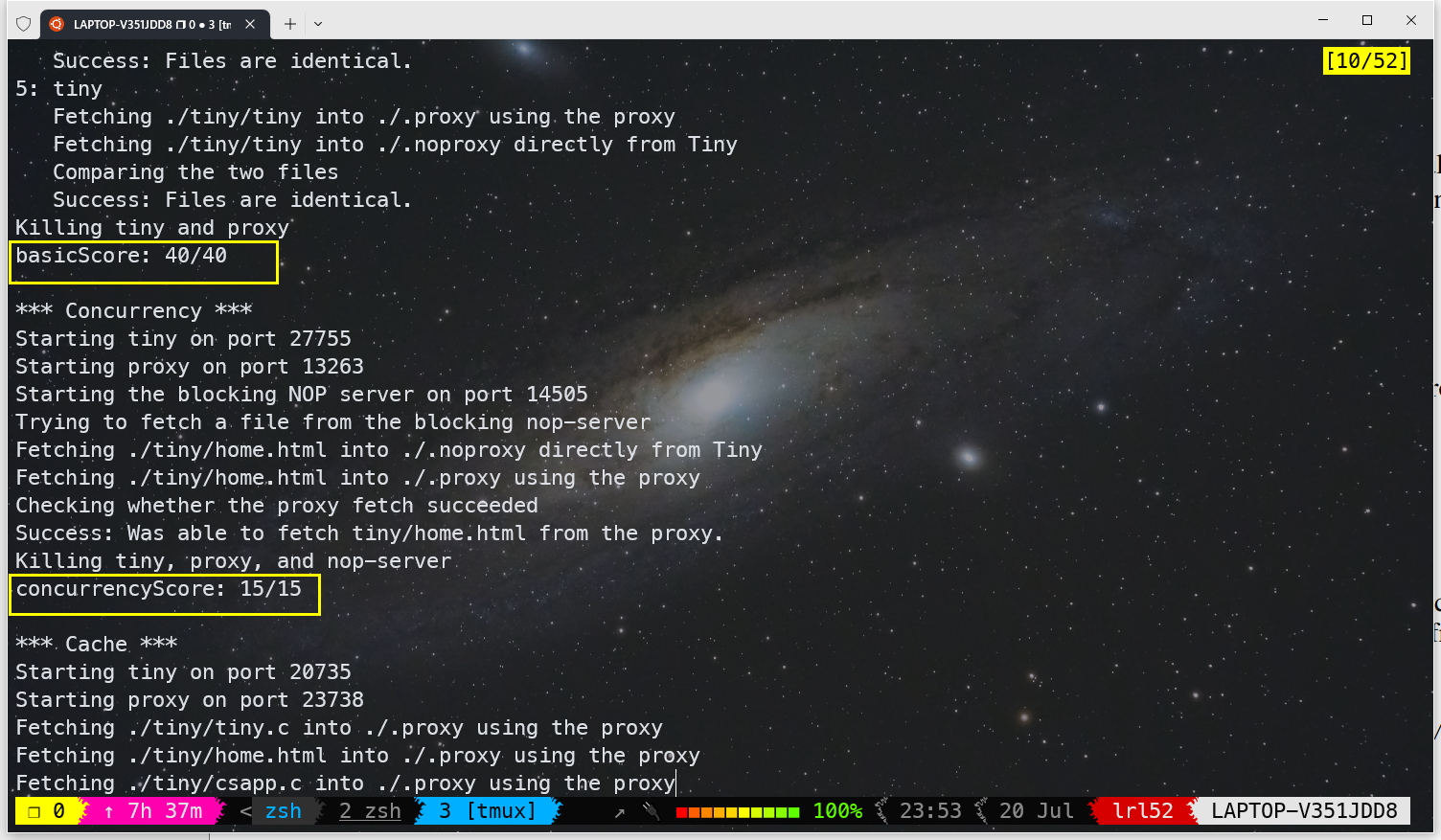
尝试通过它来访问网页,需要配置下系统代理,
会发现代理往往会使用 CONNECT 方法,而我们这个 Lab 没有实现,
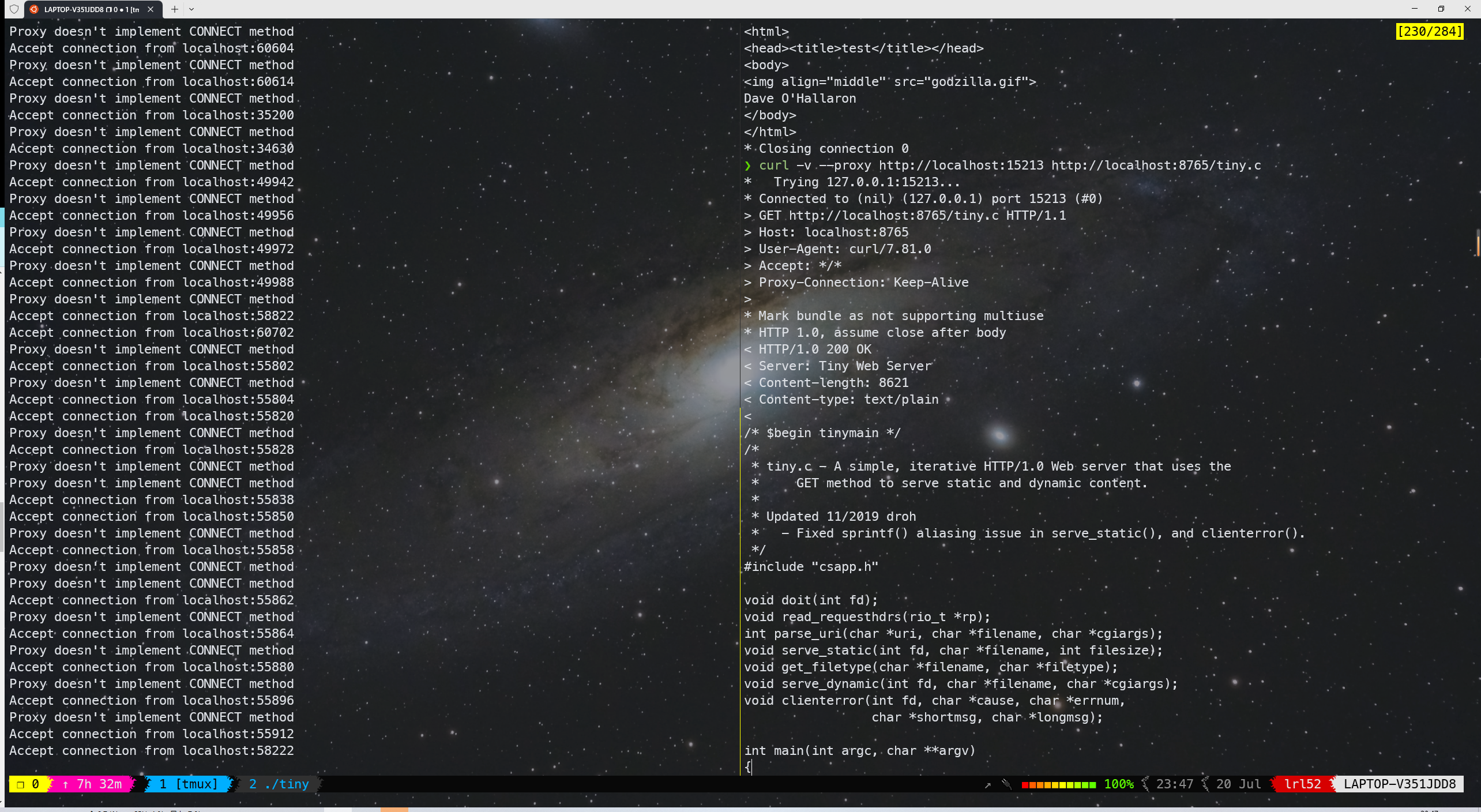
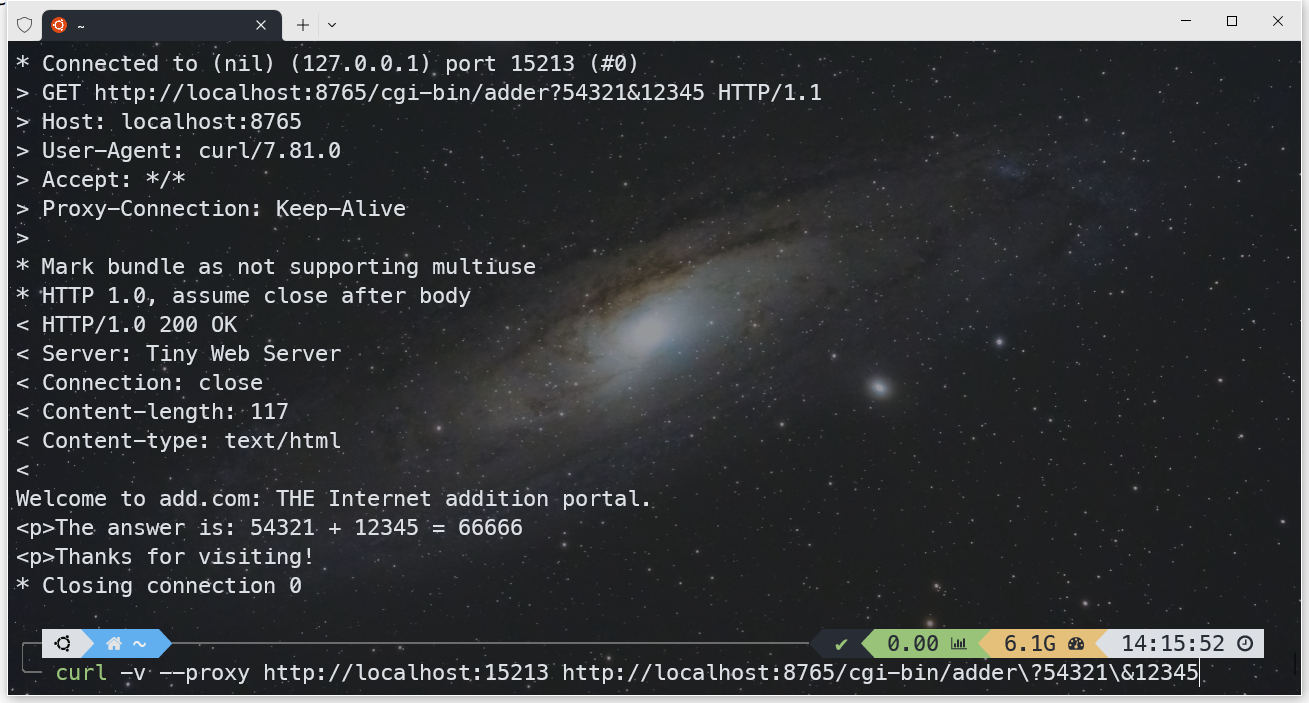
在本地运行 tiny web server ,通过 curl 的 proxy 发出 HTTP 请求来测试,tiny web server 运行在 8765 端口,proxy 运行在 15213 端口,
curl -v --proxy http://localhost:15213 http://localhost:8765从下图中可以看到请求被成功代理转发,
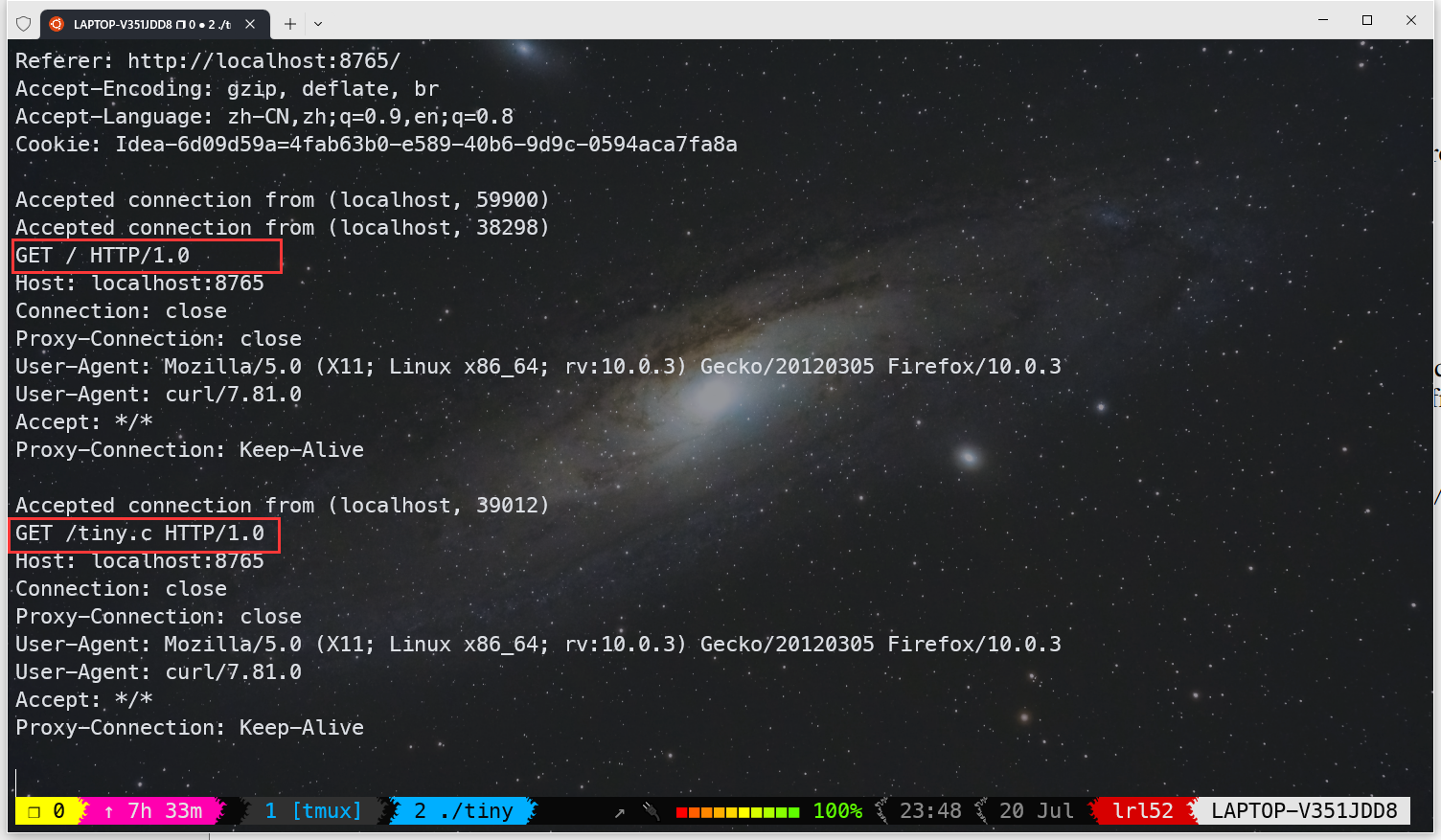
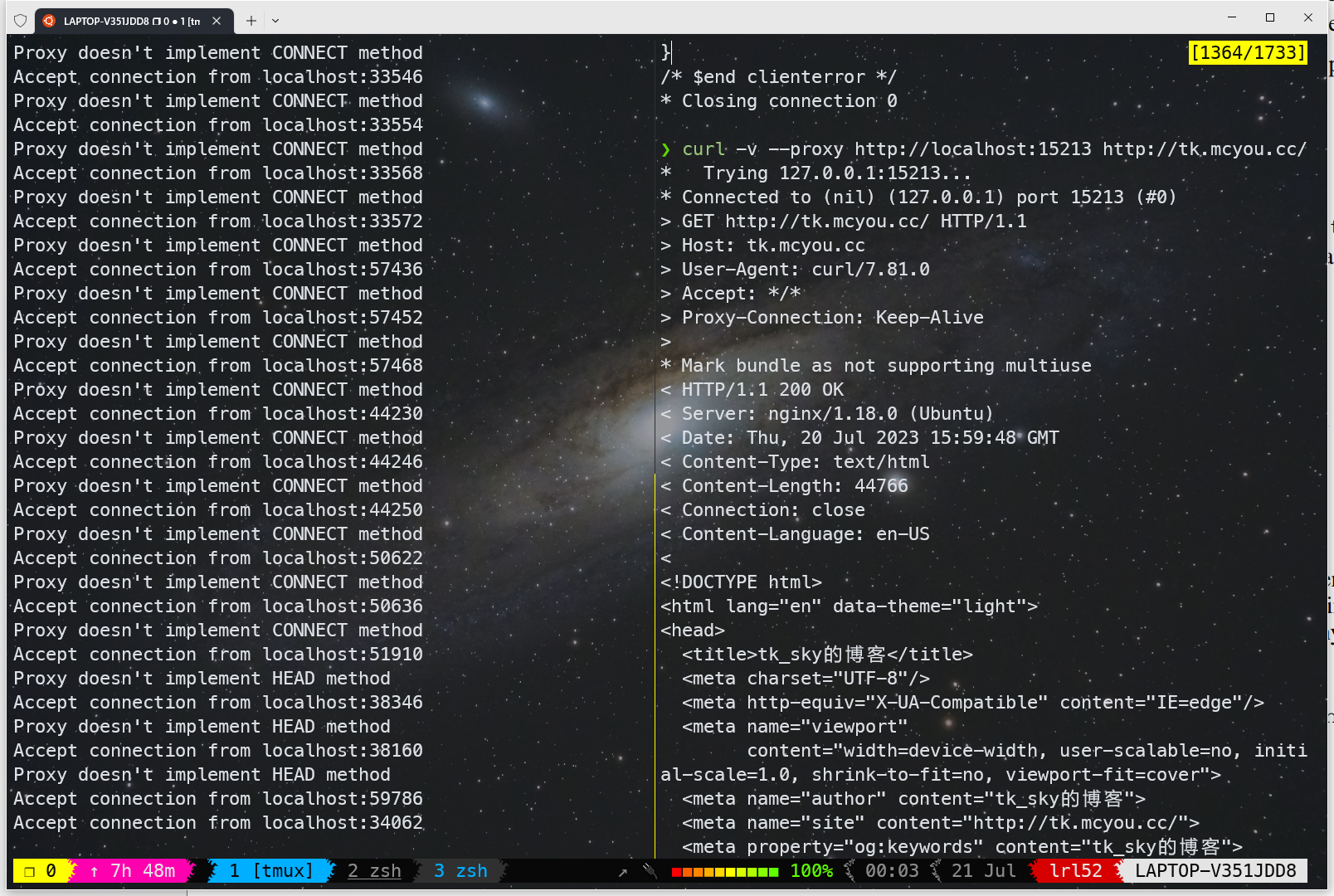
由于仅仅支持 HTTP 和 GET 方法,所以大部分网站带 HTTPS 的都无法正常访问,以下是几个不带 HTTPS 能访问的测试网站:
http://www.daileinote.com/computer/proxy/02
http://csapp.cs.cmu.edu/3e/labs.html
这里注释掉以下语句,可以勉强访问网站:
// Check method, only GET is supported
// if (strcasecmp(method, "GET")) {
// printf("Proxy doesn't implement %s method\n", method);
// return;
// }
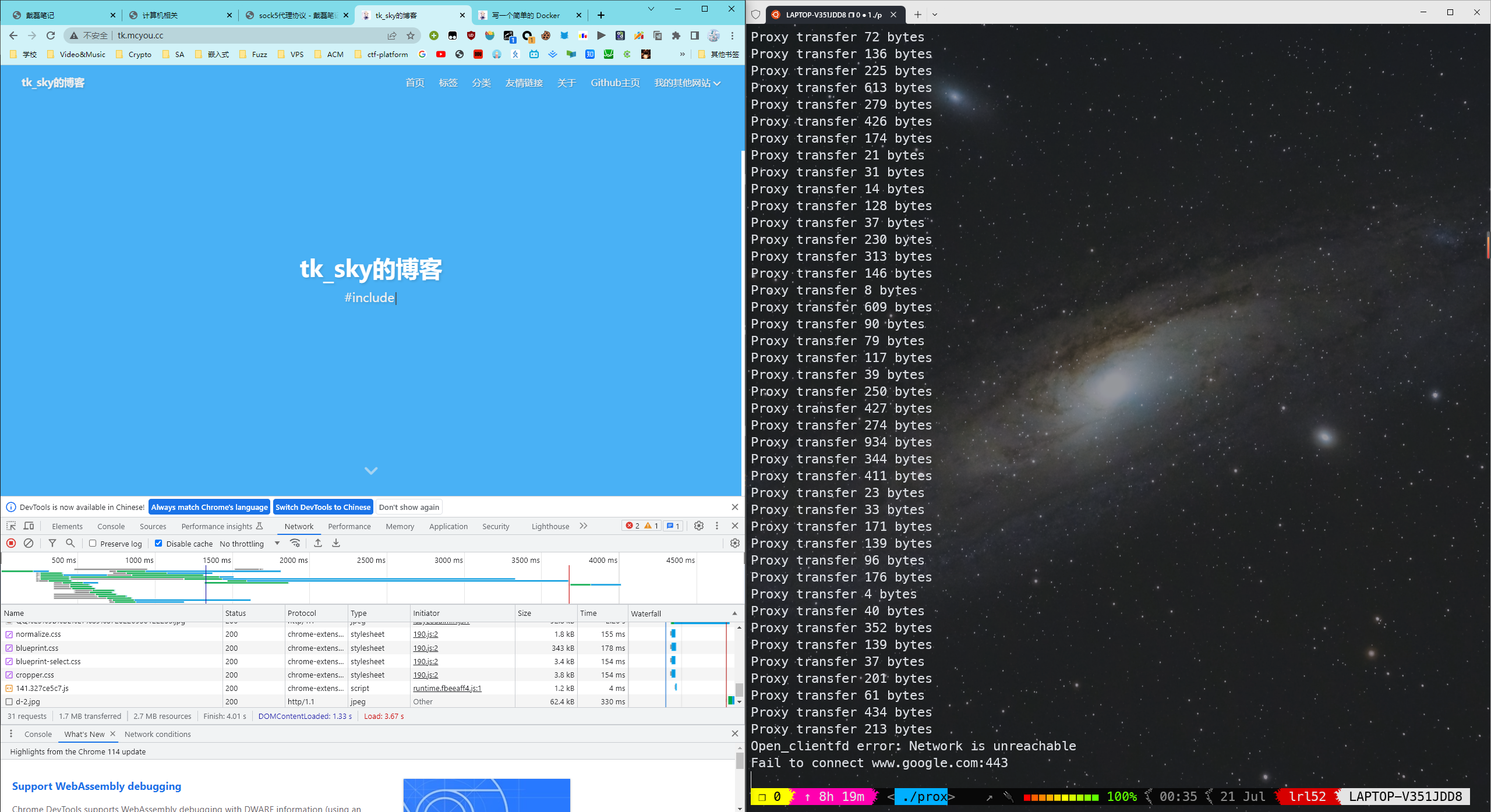
完成 cache 部分后,成功拿到了 total socre 70/70。
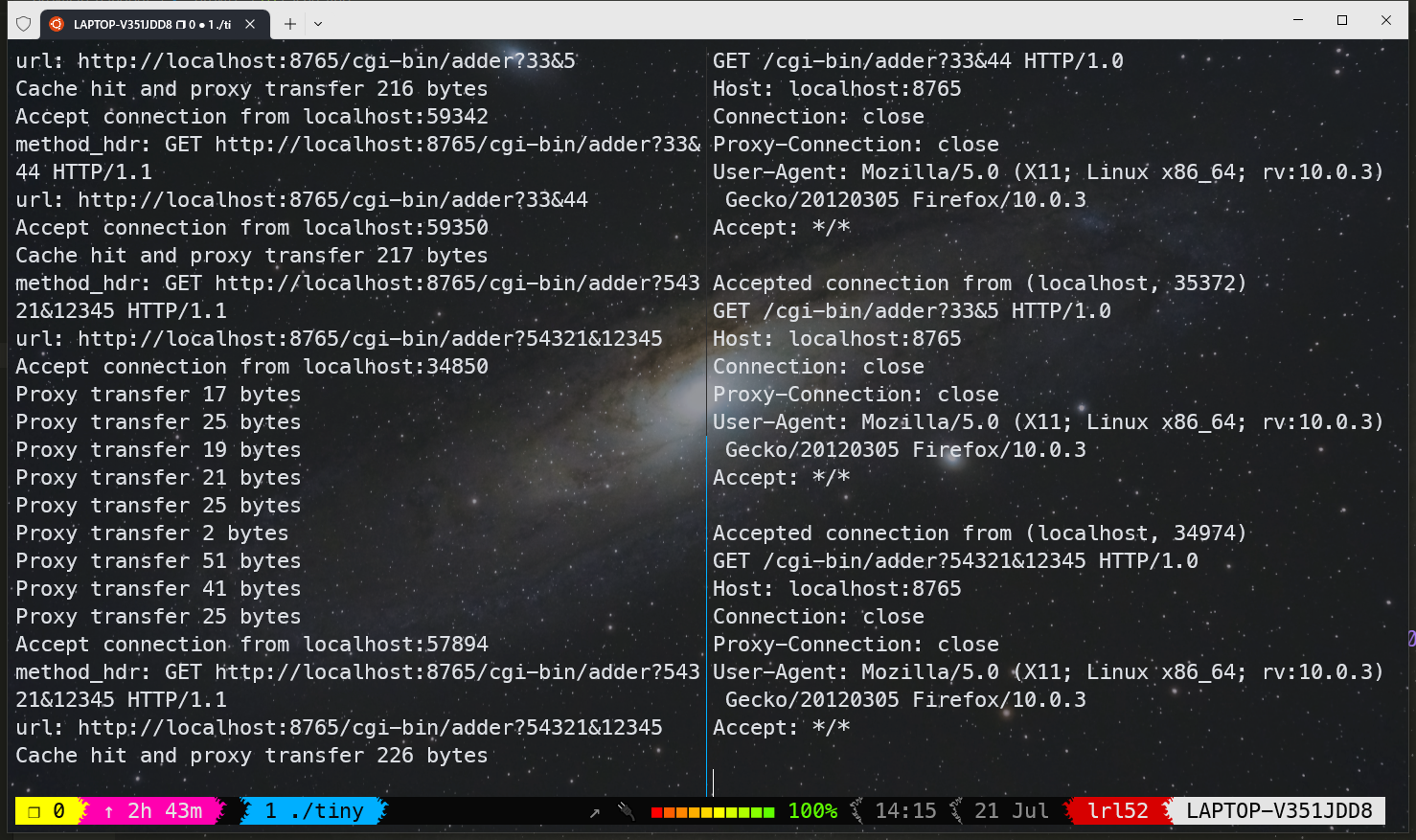
下图中可以看到 Cache hit 开头的消息则表示缓存命中,
完整代码
代码不含 csapp.c, csapp.h, sbuf.c sbuf.h,这些文件来自 CSAPP 书本代码。
全部英文注释由 Copilot 生成✅
/*
* @Author: LRL52
* @Date: 2023-07-20 19:44:48
* @LastEditTime: 2023-07-21 18:06:16
*/
#include "csapp.h"
#include "sbuf.h"
#include <bits/pthreadtypes.h>
#include <limits.h>
#include <signal.h>
#include <stddef.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <strings.h>
#include <sys/types.h>
#include <unistd.h>
/* Recommended max cache and object sizes */
#define MAX_CACHE_SIZE 1049000
#define MAX_OBJECT_SIZE 102400
#define CACHE_NUM 10
#define Assert(expression) if (!(expression)) { printf("Assertion failure in %s, line %d\n", __FUNCTION__, __LINE__); return; }
#define SBUF_SIZE 25
#define THREAD_NUM 16
/* You won't lose style points for including this long line in your code */
static const char *user_agent_hdr = "User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:10.0.3) Gecko/20120305 Firefox/10.0.3\r\n";
typedef struct {
char host[MAXLINE], port[MAXLINE], uri[MAXLINE];
uint32_t hashval;
}URL;
sbuf_t sbuf;
const uint32_t base = 31;
typedef struct {
char obj[MAX_OBJECT_SIZE], host[MAXLINE], port[MAXLINE], uri[MAXLINE];
uint32_t hashval, LRU, read_cnt;
int empty;
size_t size;
sem_t w, mutex;
}Cache;
Cache cache[CACHE_NUM];
sem_t t_mutex;
uint64_t timestamp;
// Signal handler for SIGINT
void sigint_handler(int sig) {
sbuf_deinit(&sbuf);
}
// Initialize cache
void cache_init() {
Sem_init(&t_mutex, 0, 1);
for (int i = 0; i < CACHE_NUM; ++i) {
cache[i].empty = 1;
Sem_init(&cache[i].w, 0, 1);
Sem_init(&cache[i].mutex, 0, 1);
}
}
// Lock read lock
void read_lock(int i) {
P(&cache[i].mutex);
if (++cache[i].read_cnt == 1)
P(&cache[i].w);
V(&cache[i].mutex);
}
// Unlock read lock
void read_unlock(int i) {
P(&cache[i].mutex);
if (--cache[i].read_cnt == 0)
V(&cache[i].w);
V(&cache[i].mutex);
}
// Lock write lock
void write_lock(int i) {
P(&cache[i].w);
}
// Unlock write lock
void write_unlock(int i) {
V(&cache[i].w);
}
// Get timestamp which is used to implement LRU
uint64_t get_timestamp() {
P(&t_mutex);
int ret = ++timestamp;
if (ret == 0) {
for (int i = 0; i < CACHE_NUM; ++i) {
read_lock(i);
cache[i].LRU = 0;
read_unlock(i);
}
ret = ++timestamp;
}
V(&t_mutex);
return ret;
}
// Find in cache, return index if hit, -1 otherwise
int cache_find(URL *url) {
int ret = -1;
for (int i = 0; i < CACHE_NUM; ++i) {
read_lock(i);
if (cache[i].empty || cache[i].hashval != url->hashval) {
read_unlock(i);
continue;
}
if (!strcmp(url->host, cache[i].host) && !strcmp(url->port, cache[i].port) && !strcmp(url->uri, cache[i].uri)) {
cache[i].LRU = get_timestamp();
ret = i;
// read_unlock(i);
break;
}
read_unlock(i);
}
return ret;
}
// Insert into cache
void cache_insert(URL *url, char *cache_s, size_t size) {
uint64_t minv = UINT64_MAX; int idx = -1;
for (int i = 0; i < CACHE_NUM; ++i) {
read_lock(i);
if (cache[i].empty) {
idx = i;
read_unlock(i);
break;
}
if (cache[i].LRU < minv) {
minv = cache[i].LRU;
idx = i;
}
read_unlock(i);
}
Assert(idx != -1);
write_lock(idx);
cache[idx].empty = 0;
cache[idx].hashval = url->hashval;
strcpy(cache[idx].host, url->host);
strcpy(cache[idx].port, url->port);
strcpy(cache[idx].uri, url->uri);
memcpy(cache[idx].obj, cache_s, size);
cache[idx].size = size;
cache[idx].LRU = get_timestamp();
write_unlock(idx);
}
// Calculate hash value of url
void get_hash(URL *url) {
uint32_t hashval = 0;
int n = strlen(url->host);
for (int i = 0; i < n; ++i)
hashval = hashval * base + (uint32_t)url->host[i];
n = strlen(url->port);
for (int i = 0; i < n; ++i)
hashval = hashval * base + (uint32_t)url->port[i];
n = strlen(url->uri);
for (int i = 0; i < n; ++i)
hashval = hashval * base + (uint32_t)url->uri[i];
url->hashval = hashval;
}
// Parse url into host, port and uri
void parse_url(URL *url, char *str) {
printf("url: %s\n", str);
int n = strlen(str), l = 1;
Assert(n > 1);
while ((str[l - 1] != '/' || str[l] != '/') && l + 1 < n) ++l;
// Assert(str[l - 1] == '/' && str[l] == '/');
if (!(str[l - 1] == '/' && str[l] == '/')) l = -1;
int r = l;
while (r + 1 < n && str[r + 1] != '/' && str[r + 1] != '?' && str[r + 1] != ':') ++r;
memcpy(url->host, str + l + 1, r - l);
url->host[r - l] = '\0';
l = r;
if (r + 1 < n && str[r + 1] == ':') {
l = r = r + 1;
while (r + 1 < n && str[r + 1] != '/' && str[r + 1] != '?') ++r;
memcpy(url->port, str + l + 1, r - l);
url->port[r - l] = '\0';
l = r;
} else {
strcpy(url->port, "80");
}
if (r + 1 < n) strcpy(url->uri, str + r + 1);
else strcpy(url->uri, "/");
}
// Build http header
void build_header(char *http_hdr, URL *url, rio_t *rio_p) {
static char *conn_hdr = "Connection: close\r\n";
static char *proxy_hdr = "Proxy-Connection: close\r\n";
char host_hdr[MAXLINE], method_hdr[MAXLINE], buf[MAXLINE], other_hdr[MAXLINE];
sprintf(host_hdr, "Host: %s\r\n", url->host);
sprintf(method_hdr, "GET %s HTTP/1.0\r\n", url->uri);
int cnt = 0;
while (Rio_readlineb(rio_p, buf, MAXLINE) > 0) {
if (!strcmp(buf, "\r\n")) break;
if (!strncasecmp(buf, "Host:", 5)) {
strcpy(host_hdr, buf);
} else
if (strncasecmp(buf, "Connection:", 11) && strncasecmp(buf, "Proxy-Connection:", 17) && strncasecmp(buf, "User-Agent:", 11)){
cnt += sprintf(other_hdr + cnt, "%s", buf);
}
}
sprintf(http_hdr, "%s%s%s%s%s%s\r\n", method_hdr, host_hdr, conn_hdr, proxy_hdr, user_agent_hdr, other_hdr);
}
// Solve request from connfd and write response to connfd
void Solve(int connfd) {
char buf[MAXLINE], method[MAXLINE], url_s[MAXLINE], version[MAXLINE], http_hdr[MAXLINE], cache_s[MAX_OBJECT_SIZE];
rio_t rio, host_rio;
// Read request line and headers
Rio_readinitb(&rio, connfd);
int ret = Rio_readlineb(&rio, buf, MAXLINE);
Assert(ret > 0);
printf("method_hdr: %s", buf);
sscanf(buf, "%s%s%s", method, url_s, version);
// Check method, only GET is supported
// if (strcasecmp(method, "GET")) {
// printf("Proxy doesn't implement %s method\n", method);
// return;
// }
// Parse url and calculate hash value
URL url;
parse_url(&url, url_s);
get_hash(&url);
// Try to find in cache first, and if hit, write to connfd and return
int idx = cache_find(&url);
if (idx != - 1) {
Rio_writen(connfd, cache[idx].obj, cache[idx].size);
read_unlock(idx);
printf("Cache hit and proxy transfer %zu bytes\n", cache[idx].size);
return;
}
// Build http header
build_header(http_hdr, &url, &rio);
// Connect to host
int hostfd = Open_clientfd(url.host, url.port);
if (hostfd < 0) {
printf("Fail to connect %s:%s\n", url.host, url.port);
return;
}
// Write http header to host
Rio_readinitb(&host_rio, hostfd);
Rio_writen(hostfd, http_hdr, strlen(http_hdr));
// Read response from host and write to connfd
int n = 0; size_t tot = 0;
while ((n = Rio_readlineb(&host_rio, buf, MAXLINE)) > 0) {
Rio_writen(connfd, buf, n);
printf("Proxy transfer %d bytes\n", n);
if (tot + n <= MAX_OBJECT_SIZE)
memcpy(cache_s + tot, buf, n);
tot += n;
}
Close(hostfd);
// Insert into cache if size of object less or equal to MAX_OBJECT_SIZE
if (tot > 0 && tot <= MAX_OBJECT_SIZE)
cache_insert(&url, cache_s, tot);
}
// Thread routine: get request from sbuf, solve it and close connection
void *mythread(void *arg) {
Pthread_detach(Pthread_self());
while (1) {
int connfd = sbuf_remove(&sbuf);
Solve(connfd);
Close(connfd);
}
pthread_exit(NULL);
}
int main(int argc, char *argv[]) {
// Check command line args
if (argc != 2) {
fprintf(stderr, "Usage: %s <port>\n", argv[0]);
exit(EXIT_FAILURE);
}
// Ignore SIGPIPE, handle SIGINT
struct sigaction sa;
memset(&sa, 0, sizeof(sa));
sa.sa_handler = sigint_handler;
sa.sa_flags = 0;
sigemptyset(&sa.sa_mask);
sigaction(SIGINT, &sa, NULL);
signal(SIGPIPE, SIG_IGN);
// Initialize sbuf and cache
sbuf_init(&sbuf, SBUF_SIZE);
cache_init();
// Listen to port
int listenfd = Open_listenfd(argv[1]);
printf("Proxy server is running on port %s ...\n", argv[1]);
// Create threads
pthread_t tid;
for (int i = 0; i < THREAD_NUM; ++i) {
Pthread_create(&tid, NULL, mythread, NULL);
}
// Infinite loop to accept connections
struct sockaddr_storage clientaddr;
socklen_t clientlen = sizeof(struct sockaddr_storage);
char host[MAXLINE], port[MAXLINE];
while (1) {
int connfd = Accept(listenfd, (struct sockaddr *)&clientaddr, &clientlen);
sbuf_insert(&sbuf, connfd);
Getnameinfo((struct sockaddr *)&clientaddr, clientlen, host, MAXLINE, port, MAXLINE, 0);
printf("Accept connection from %s:%s\n", host, port);
}
return 0;
}
