MEMTIS 配置
Kernel 编译配置
编译 MEMTIS kernel 需要打开在 .config 中启用 CONFIG_HTMM=y,即 Enable hugepage-aware tiered memory management。
...
CONFIG_HTMM=y
...
Linux 的 Transparent Huge Pages(THP)是一种内存管理特性,旨在提高大内存页使用的性能,通过减少页表的数量来降低 TLB(Translation Lookaside Buffer,页表缓存)缺失的可能性,从而提高系统的性能。这一特性是从 Linux 内核 2.6.38 版本开始引入的。
THP 是巨页支持的一个进一步的发展,它旨在使得使用巨页变得更加“透明”,无需应用程序的特定支持。在 THP 启用的系统中,内核会自动尝试为合适的内存区域分配巨页,而不需要应用程序进行特殊的内存分配调用或修改。
此外 MEMTIS 仓库的 scripts 在测试时可以更改 Intel Uncore 的频率,如需使用该功能,需要编译 intel-uncore-frequency 模块,需要在 menuconfig 中 Device Drivers -> X86 Platform Specific Device Drivers 中的 INTEL_UNCORE_FREQ_CONTROL 选项启用。下文的测试中未启用 Intel Uncore。
uncore一词,是英特尔用来描述CPU中,功能上为非处理器核心(Core)所负担,但是对处理器性能的发挥和维持有必不可少的作用的组成部分。[1]处理器核心包含的处理器组件都涉及处理器指令的执行,包括算术逻辑单元(ALU)、浮点运算单元(FPU)、一级缓存(L1 Cache)、二级缓存(L2 Cache)。Uncore的功能包括QPI控制器、三级缓存(L3 Cache)、高速PCI Express控制器、DMI控制器、存储器控制器,以及QPI控制器。[2]至于其余的I/O总线控制器,像是USB、LPC等,则属于PCH芯片组。
Intel Uncore Frequency Scaling
对于 MEMTIS,它支持通过 cgroup v2 的接口来限制 fast tier 的内存,因此我们需要启用 cgroup v2。开启办法如下:
编辑/etc/default/grub 文件,在 GRUB_CMDLINE_LINUX 行,移除 cgroup.memory=nokmem 参数,添加 systemd.unified_cgroup_hierarchy=1 参数。
由于笔者使用的是 RHEL 衍生系统,grub.cfg 文件位于 /boot/efi/EFI/alinux/grub.cfg,执行如下指令生成新的GRUB配置。
grub2-mkconfig -o /boot/efi/EFI/alinux/grub.cfg
重启系统以应用更改。可以通过运行mount | grep cgroup2来检查 cgroup v2 是否正确启用,如果系统已启用cgroup v2,可以看到相应的挂载信息。下文的测试均通过 cgroup v2 来限制 workload 的 CPU 和 Memory。
用户态配置
根据 MEMTIS 仓库的配置脚本,如果需要手动启用 MEMTIS,需要设置如下内核参数,笔者这里总结了一份单独的配置脚本:
#!/bin/bash
echo "Preparing benchmark start..."
sudo sysctl kernel.perf_event_max_sample_rate=100000
# disable automatic numa balancing
sudo echo 0 > /proc/sys/kernel/numa_balancing
echo 199 | tee /sys/kernel/mm/htmm/htmm_sample_period
echo 100007 | tee /sys/kernel/mm/htmm/htmm_inst_sample_period
echo 1 | tee /sys/kernel/mm/htmm/htmm_thres_hot
echo 2 | tee /sys/kernel/mm/htmm/htmm_split_period
echo 100000 | tee /sys/kernel/mm/htmm/htmm_adaptation_period
echo 2000000 | tee /sys/kernel/mm/htmm/htmm_cooling_period
echo 2 | tee /sys/kernel/mm/htmm/htmm_mode
echo 500 | tee /sys/kernel/mm/htmm/htmm_demotion_period_in_ms
echo 500 | tee /sys/kernel/mm/htmm/htmm_promotion_period_in_ms
echo 4 | tee /sys/kernel/mm/htmm/htmm_gamma
### cpu cap (per mille) for ksampled
echo 30 | tee /sys/kernel/mm/htmm/ksampled_soft_cpu_quota
echo 1 | tee /sys/kernel/mm/htmm/htmm_thres_split
echo 0 | tee /sys/kernel/mm/htmm/htmm_nowarm
echo "disabled" | tee /sys/kernel/mm/htmm/htmm_cxl_mode
echo "always" | tee /sys/kernel/mm/transparent_hugepage/enabled
echo "always" | tee /sys/kernel/mm/transparent_hugepage/defrag
cgroup v2 配置
根据作者原文“To control the size of the fast tier, we used a memory,cgroup interface for Memtis and Nimble.”MEMTIS 支持通过 cgroup v2 来限制内存,这为后面的 workload 测试带来了方便。(因为如果使用传统 memory offline 技术,总会有很多 memory 由于已经被占用,一时无法安全地 offload)
创建一个新的 cgroup,命名为 htmm,
sudo mkdir -p /sys/fs/cgroup/htmm
添加 memory 控制,
echo "+memory" | sudo tee /sys/fs/cgroup/cgroup.subtree_control
echo "enabled" | sudo tee /sys/fs/cgroup/memory.htmm_enabled
添加需要被控制的进程组 PID,
echo <pid> | sudo tee /sys/fs/cgroup/htmm/cgroup.procs
添加内存限制,下面以 node 0 为例,限制内存为 2GB = 2147483648B,
echo 2147483648 | sudo tee /sys/fs/cgroup/htmm/memory.max_at_node0
这个 cgroup 接口在 linux 上我是没查到,可能是 memtis 内核的私货。不过现在这么限制倒还挺方便的。(下图中是限制的 3.6GB 内存)

比如下面就是 1:8 的内存配置:

MEMTIS kthread
MEMTIS 有两类 kthread,一类是 ksampled 内核线程(注:实际名为 ksamplingd) ,用于在后台进行 HW-based 采样,MEMTIS 动态调整其采样频率,避免 CPU overhead 超过单核性能的 3%。还有一类是 kmigrated 内核线程(注:实际名为 kmigraterd{NODE_ID}),每个 node 上都有一个 delicated 的 kmigrated 内核线程,专门负责该 node 的搬运,以避免延长 critical path。
由于是内核线程,无法直接通过 pidof 获取到进程 ID。这里可以通过如下办法来获取进程 ID 以及 CPU overhead,图中的百分比是对应单核性能的百分比,如果一个进程并行使用了多核,例如 20 核,那么会显示 2000%:
很奇怪的一件事就是,这两类线程它不是一直存在的,只有 cgroup 创建并启用的时候才存在,我也不太懂作者是怎么设计的。
后面的测试中,均是每间隔 1s 记录一次 CPU overhead。由于笔者在测试时是 bind 到 node 0 上运行的,因此 kmigraterd1 线程的 CPU overhead 经过观察一直恒为 0,故在后面的测试图中不会出现 kmigraterd1。
Workload 实测
注:Baseline 为纯 local memory,1 : x 代表 local memory 和 remote memory 的比例,特别地,1 : 0 代表纯 local memory。
YCSB-Redis
RSS(Resident Set Size) 大约为 18GB,总共 $10^7$ 条 record,每个 workload 运行 $2\times 10^7$ 次 operation,16 线程。
YCSB 总共有 6 种 workload,根据官方指导建议,首先 Load 插入数据,然后依次运行 A、B、C、F、D 这 5 个 workload。(没有 E 是因为根据官方建议,E 需要在 D 之后 Reload 数据库后再运行,由于 Load 时间比较长,遂放弃这个性价比不高的 workload)下面是 5 个 worklaod 的介绍:
Workload A: Update heavy workload:该工作负载具有 50/50 的读写混合。一个应用示例是记录最近操作的会话存储。这个工作负载中的更新不假设您首先读取原始记录。假设是所有更新写操作包含已经存在的记录的字段;往往只写入该记录的部分字段。一些数据存储需要读取底层记录以便协调最终记录应该是什么样子,但并非所有的数据存储都需要这样做。
Workload B: Read mostly workload:这个工作负载有 95/5 的读/写混合比。应用示例:照片标记;添加标记是一个更新操作,但大多数操作是读取标记。与工作负载 A 一样,这些写操作不假设您在写入之前读取原始记录。
Workload C: Read only:这个工作负载是 100% 的读取。应用示例:用户配置文件缓存,配置文件在其他地方构建(例如,Hadoop)。
Workload D: Read latest workload:在这个工作负载中,新记录被插入,最近插入的记录最受欢迎。应用示例:用户状态更新;人们想要读取最新的状态。
Workload F: Read-modify-write:在这个工作负载中,客户端将读取一条记录,修改它,然后写回更改。应用示例:用户数据库,其中用户记录由用户读取和修改,或用于记录用户活动。这个工作负载强制在写入更新的字段集之前从底层数据存储中读取记录。这实际上强制所有数据存储在接受对其写入之前先读取底层记录。目前我们使用随机增量进行写入,而不是从当前记录中派生的一些值(比如增加一个计数器)。这可能使得工作负载有点难以跟随,因为起始读取看似不必要。
Throughput:
| Throughput (%) (normalized to Baseline) | Load | Workload A | Workload B | Workload C | Workload F | Workload D |
|---|---|---|---|---|---|---|
| 1 : 8 | 90.7 | 89.2 | 87.5 | 86.0 | 89.3 | 89.0 |
| 1 : 4 | 92.5 | 90.2 | 87.8 | 86.5 | 89.9 | 89.3 |
| 1 : 2 | 94.4 | 92.0 | 88.8 | 88.7 | 91.0 | 89.6 |
| 1 : 1 | 102.1 | 97.9 | 96.5 | 94.3 | 98.3 | 94.9 |
| 1 : 0 | 100 | 100 | 100 | 100 | 100 | 100 |
AverageLatency-1:
| Average Latency Increase (%) (relative to Baseline) | Load(Insert) | Workload A(Read) | Workload A(Update) | Workload B(Read) | Workload B(Update) | Workload C(Read) |
|---|---|---|---|---|---|---|
| 1 : 8 | 10.4 | 12.4 | 12.3 | 14.4 | 13.5 | 16.5 |
| 1 : 4 | 8.3 | 11.0 | 11.2 | 14.0 | 13.0 | 15.9 |
| 1 : 2 | 6.0 | 8.8 | 8.8 | 12.9 | 12.8 | 12.9 |
| 1 : 1 | -2.0 | 2.4 | 1.9 | 3.9 | 1.2 | 6.3 |
| 1 : 0 | 0 | 0 | 0 | 0 | 0 | 0 |
AverageLatency-2:
| Average Latency Increase (%) (relative to Baseline) | Workload F(Read) | Workload F(Read-Modify-Write) | Workload F(Update) | Workload D(Read) | Workload D(Insert) |
|---|---|---|---|---|---|
| 1 : 8 | 12.3 | 11.9 | 11.6 | 12.4 | 12.6 |
| 1 : 4 | 11.7 | 11.2 | 10.8 | 12.1 | 11.8 |
| 1 : 2 | 10.2 | 9.9 | 9.6 | 11.7 | 11.1 |
| 1 : 1 | 2.1 | 1.6 | 1.3 | 5.9 | 2.7 |
| 1 : 0 | 0 | 0 | 0 | 0 | 0 |
P95 Latency-1:
| P95 Latency Increase (%) (relative to Baseline) | Load(Insert) | Workload A(Read) | Workload A(Update) | Workload B(Read) | Workload B(Update) | Workload C(Read) |
|---|---|---|---|---|---|---|
| 1 : 8 | 16.3 | 17.4 | 16.6 | 20.9 | 13.3 | 21.4 |
| 1 : 4 | 13.6 | 13.7 | 14.6 | 20.3 | 12.3 | 20.2 |
| 1 : 2 | 11.6 | 13.0 | 12.7 | 17.4 | 11.8 | 18.5 |
| 1 : 1 | 3.6 | 10.6 | 7.0 | 15.1 | 1.0 | 17.3 |
| 1 : 0 | 0 | 0 | 0 | 0 | 0 | 0 |
P95 Latency-2:
| P95 Latency Increase (%) (relative to Baseline) | Workload F(Read) | Workload F(Read-Modify-Write) | Workload F(Update) | Workload D(Read) | Workload D(Insert) |
|---|---|---|---|---|---|
| 1 : 8 | 16.8 | 11.9 | 11.6 | 15.8 | 13.0 |
| 1 : 4 | 16.8 | 11.9 | 9.9 | 16.4 | 12.5 |
| 1 : 2 | 14.2 | 10.2 | 9.9 | 17.0 | 11.9 |
| 1 : 1 | 8.4 | 3.5 | 2.3 | 15.8 | 0.0 |
| 1 : 0 | 0 | 0 | 0 | 0 | 0 |
P99 Latency-1:
| P99 Latency Increase (%) (relative to Baseline) | Load(Insert) | Workload A(Read) | Workload A(Update) | Workload B(Read) | Workload B(Update) | Workload C(Read) |
|---|---|---|---|---|---|---|
| 1 : 8 | 7.6 | 12.8 | 12.6 | 15.5 | 14.8 | 16.5 |
| 1 : 4 | 4.7 | 11.3 | 11.1 | 15.0 | 13.9 | 15.5 |
| 1 : 2 | 3.8 | 9.7 | 9.5 | 13.0 | 13.4 | 13.6 |
| 1 : 1 | -3.8 | 2.6 | 2.1 | 4.8 | 1.9 | 7.3 |
| 1 : 0 | 0 | 0 | 0 | 0 | 0 | 0 |
P99 Latency-2:
| P99 Latency Increase (%) (relative to Baseline) | Workload F(Read) | Workload F(Read-Modify-Write) | Workload F(Update) | Workload D(Read) | Workload D(Insert) |
|---|---|---|---|---|---|
| 1 : 8 | 11.5 | 12.9 | 12.7 | 12.7 | 13.4 |
| 1 : 4 | 12.0 | 13.2 | 11.6 | 13.7 | 12.9 |
| 1 : 2 | 9.9 | 10.8 | 10.6 | 13.7 | 12.4 |
| 1 : 1 | 1.6 | 3.0 | 2.1 | 8.1 | 5.2 |
| 1 : 0 | 0 | 0 | 0 | 0 | 0 |
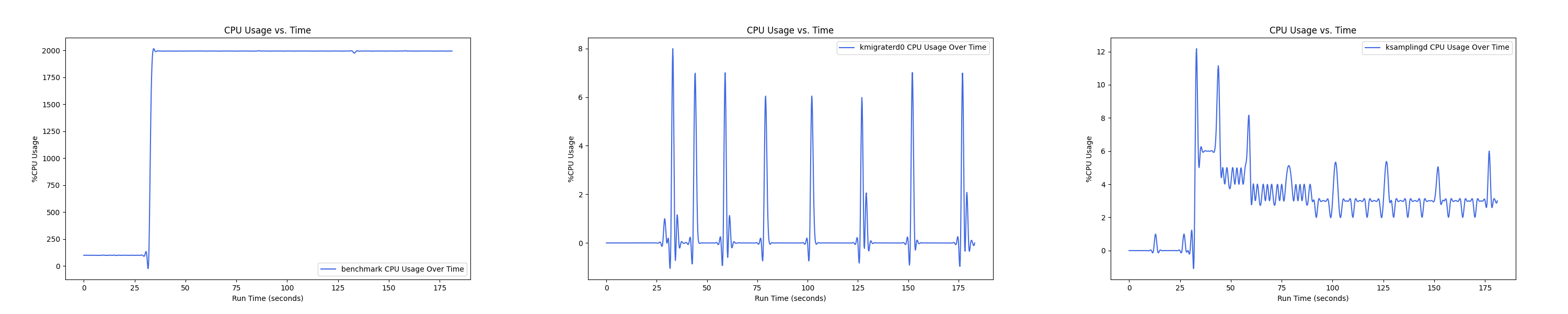
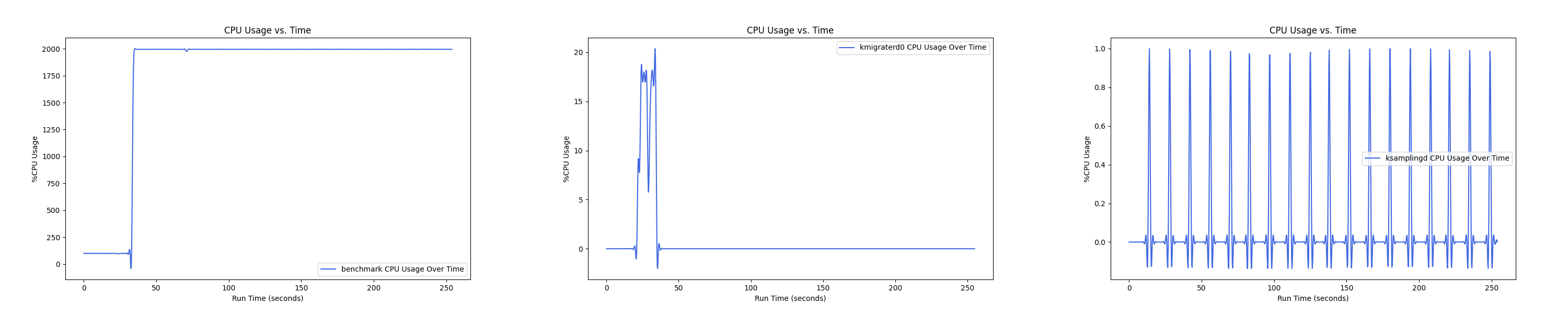
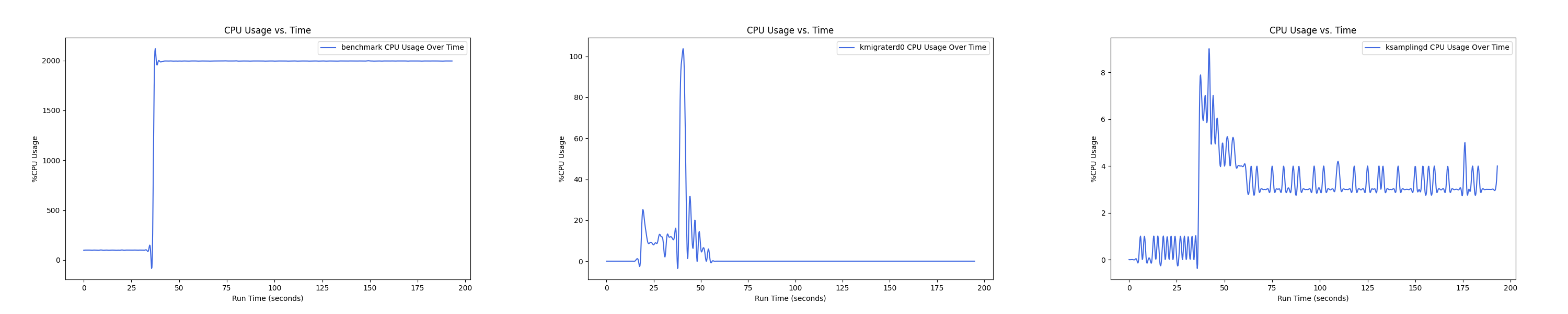
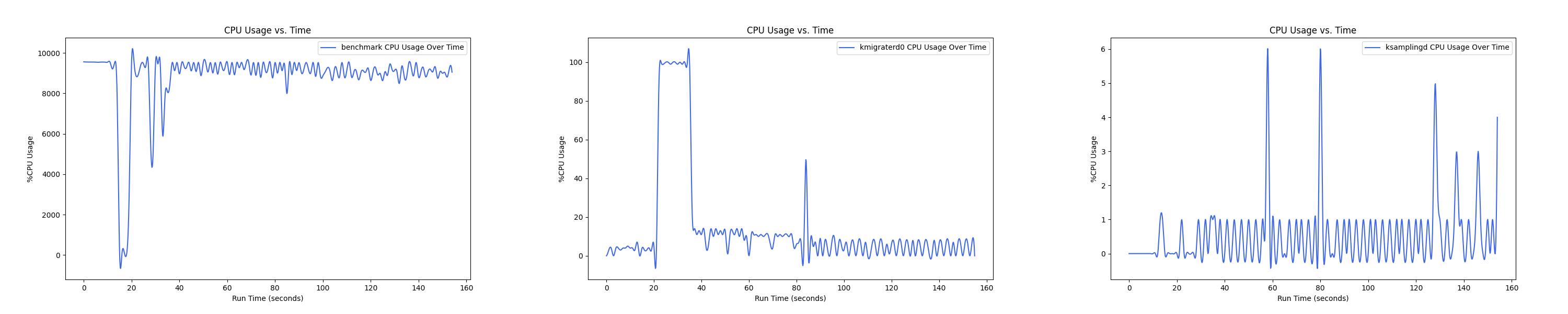
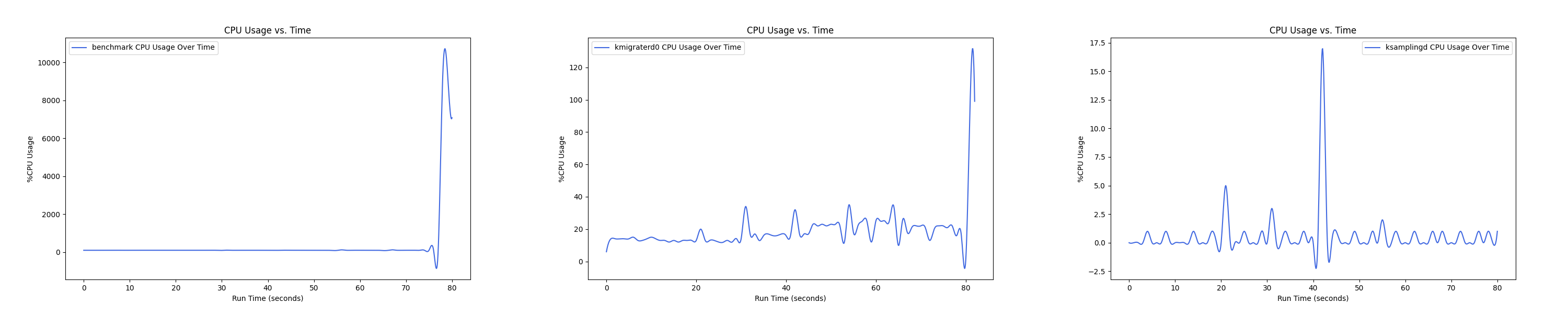
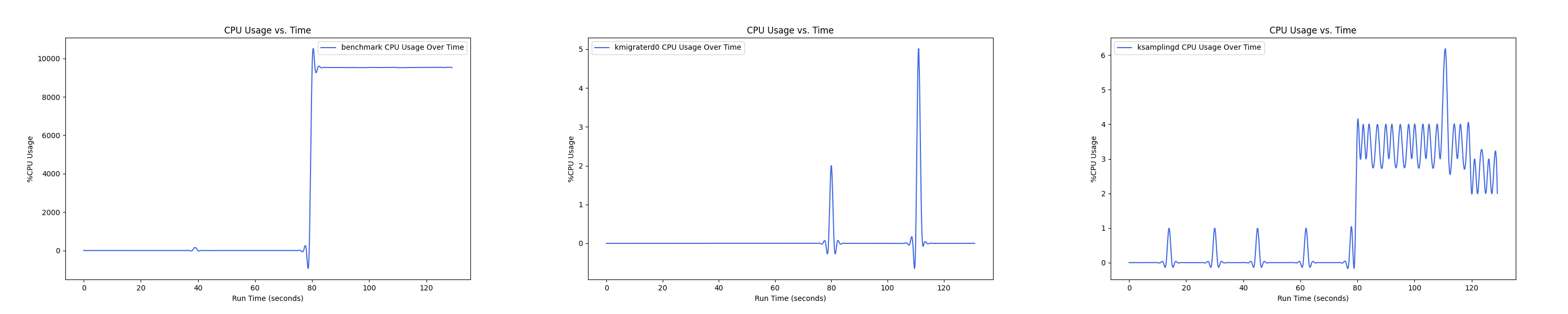
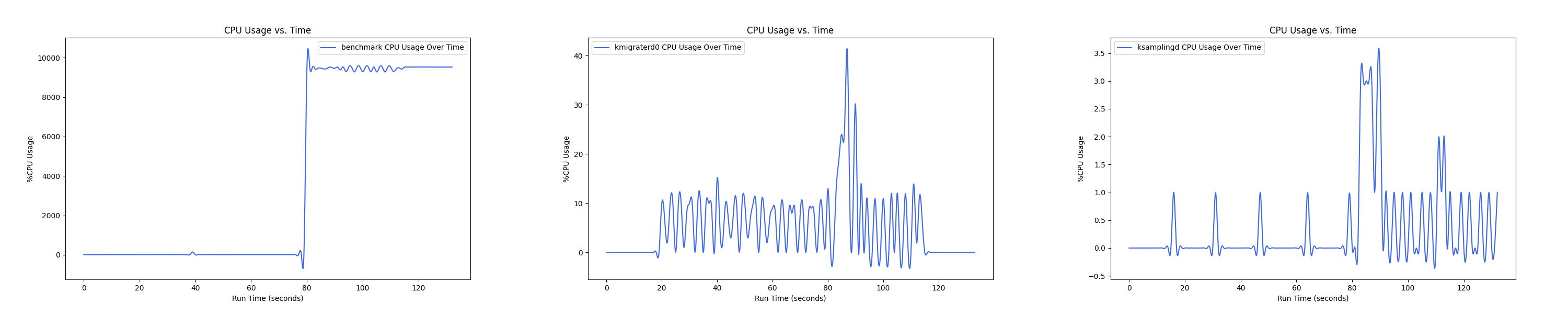
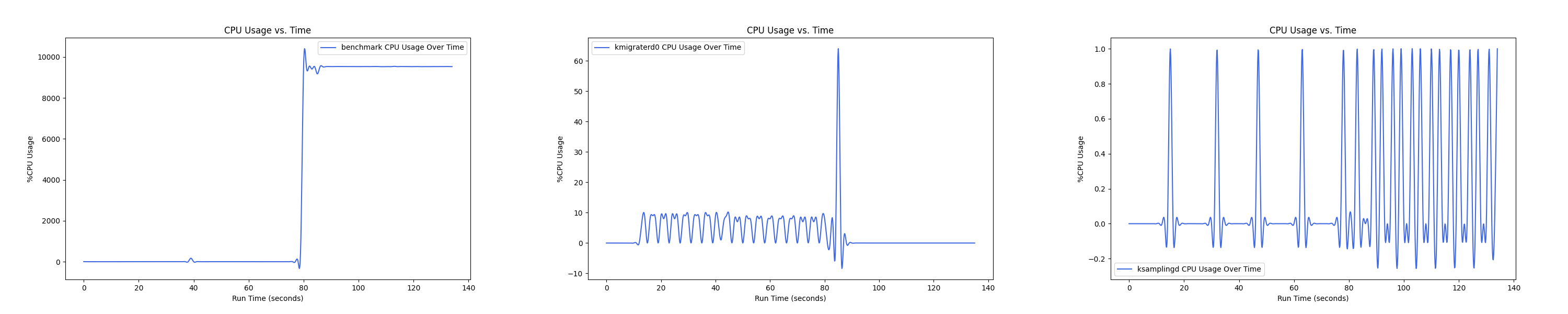
MEMTIS kthreads and benchmark CPU usage:
每张图都包含连续运行的 5 个 workload,依次是 Load、A、B、C、F、D。分界点可以从 benchmark 图里面的低谷区别。
- 1 : 0 配置:



- 1 : 1 配置:



- 1 : 2 配置:



- 1 : 4 配置:



- 1 : 8 配置:



- 1 : 16 配置:



Insight:随着本地内存越来越少, 线程的 CPU overhead 反而在减小,说明在本地内存严重不足的情况下,识别热页的难度更大,搬运热页所来的收益更小,kmigraterd0 的策略更加谨慎,避免 ping-pong 现象带来的额外开销。
XSBench
XSBench 是一个小型应用程序,代表了蒙特卡罗中子输运算法的一个关键计算核心。具体来说,XSBench 代表了连续能量宏观中子截面查找核心。XSBench 作为像 OpenMC 这样的完整中子输运应用程序的轻量级代理,并且是在高性能计算架构上进行性能分析的有用工具。
XSBench 有多种不同语言实现,这里测试采用 XSBench 的“默认”版本,适用于串行和多核 CPU 架构。并行方法是通过 OpenMP 线程模型实现的。
RSS(Resident Set Size) 大约为 64GB,20 线程。每个核素的网格点数量(Gridpoints per Nuclide)为 130000,粒子历史(Particle Histories)的数量为 30000000。(不知道为啥结果总是 WARNING - INVALID CHECKSUM,不过应该对性能测试影响不大吧)
Lookups/s:
| Memory Config (local : remote) | Lookups/s (%) (normalized to Baseline) |
|---|---|
| 1 : 16 | 67.3 |
| 1 : 8 | 66.5 |
| 1 : 4 | 66.1 |
| 1 : 2 | 65.9 |
| 1 : 1 | 96.3 |
| 1 : 0 | 100 |
MEMTIS kthreads and benchmark CPU usage:
- 1 : 0 配置:
- 1 : 1 配置:
- 1 : 2 配置:
- 1 : 4 配置:
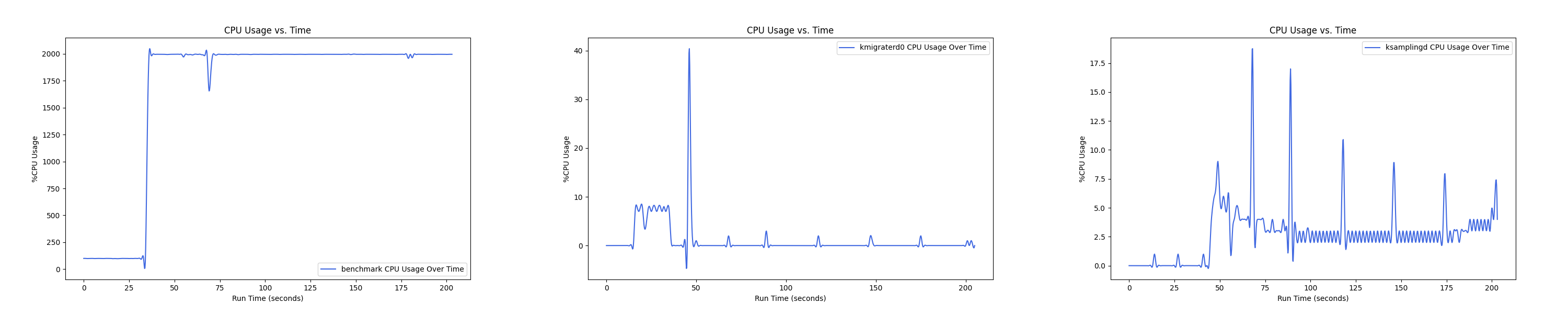
- 1 : 8 配置:
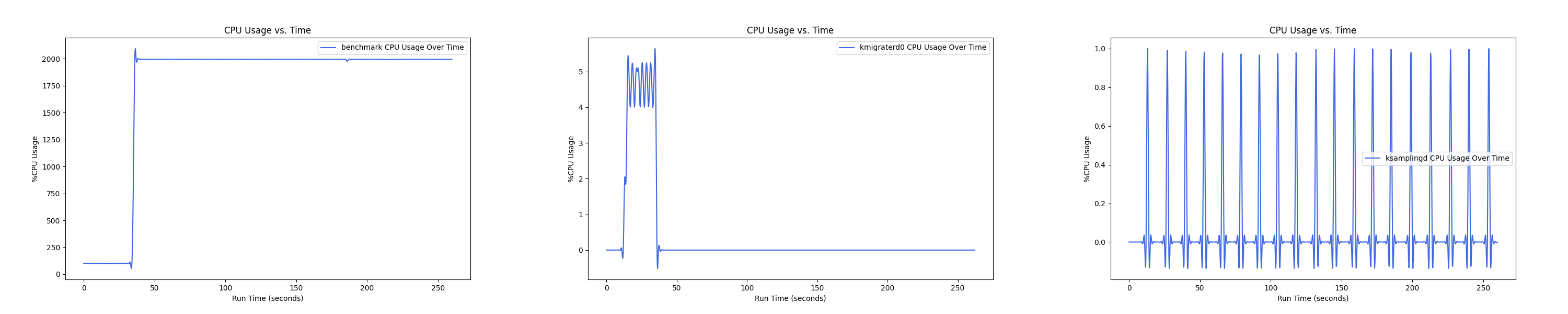
- 1 : 16 配置:
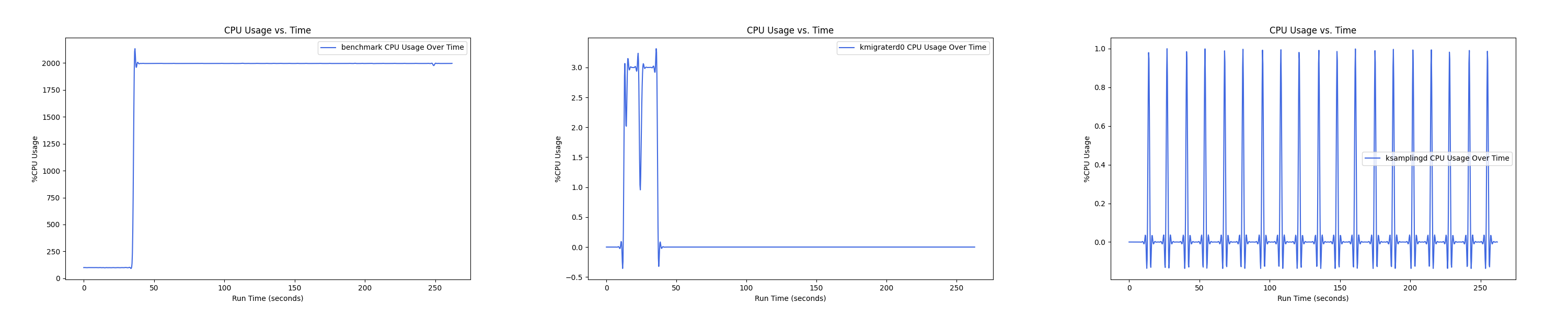
Graph500
Graph500 是一个超级计算机系统的评级,专注于数据密集型负载。该项目于 2010 年 6 月的国际超级计算机会议上宣布。第一份榜单于 2010 年 11 月的 ACM/IEEE 超级计算会议上发布。榜单每年更新两次。用于对超级计算机进行排名的主要性能指标是 GTEPS(每秒遍历的千万边)。
Graph500 使用的基准测试强调了系统的通信子系统,而不是计算双精度浮点数。它基于在一个大型无向图(平均度为 16 的克罗内克图模型)中进行广度优先搜索。该基准测试包含三个计算核心:第一个核心是生成图并将其压缩成 CSR 或 CSC(压缩稀疏行/列)的稀疏结构;第二个核心执行某些随机顶点(每次运行 64 次搜索迭代)的并行 BFS 搜索;第三个核心执行单源最短路径(SSSP)计算。定义了六种可能的图大小(规模):玩具级(226顶点;17GB RAM)、迷你级(229;137GB)、小型(232;1.1TB)、中型(236;17.6TB)、大型(239;140TB)和巨型(242;1.1PB RAM)。
测试时使用 omp-csr/omp-csr(OpenMP compressed-sparse-row implementation)版本,R-MAT scale 为 27,R-MAT edge factor 为 15。
RSS(Resident Set Size) 大约为 64GB。
| Traversed Edges Per Second (%) (relative to Baseline) | min_TEPS | firstquartile_TEPS | median_TEPS | thirdquartile_TEPS | max_TEPS | harmonicmean_TEPS |
|---|---|---|---|---|---|---|
| 1 : 16 | 49.1 | 78.4 | 71.5 | 87.7 | 87.0 | 63.0 |
| 1 : 8 | 52.8 | 83.1 | 89.4 | 95.9 | 97.2 | 67.9 |
| 1 : 4 | 52.1 | 80.0 | 81.1 | 85.2 | 90.6 | 74.1 |
| 1 : 2 | 51.2 | 79.7 | 84.6 | 88.5 | 90.4 | 71.6 |
| 1 : 1 | 55.0 | 81.3 | 82.9 | 86.7 | 98.5 | 81.7 |
| 1 : 0 | 100 | 100 | 100 | 100 | 100 | 100 |
MEMTIS kthreads and benchmark CPU usage:
- 1 : 0 配置:
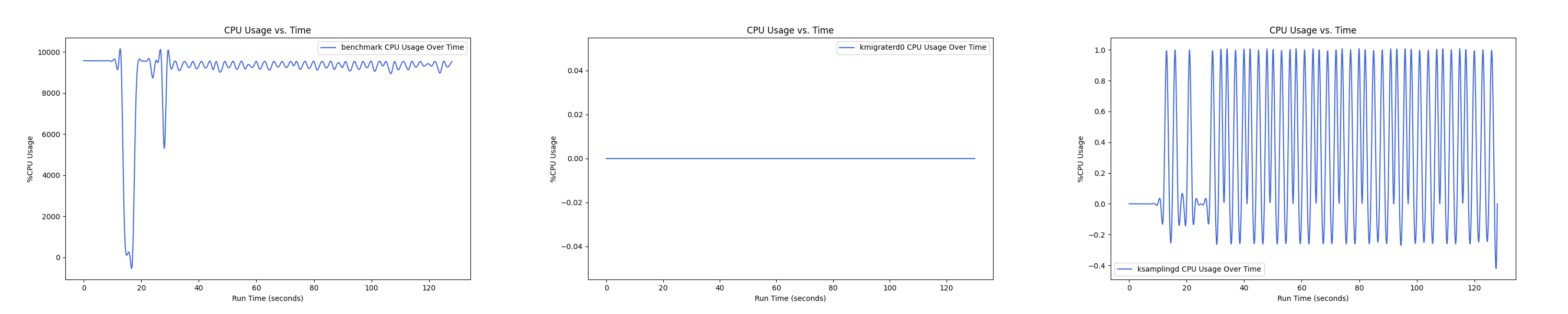
- 1 : 1 配置:
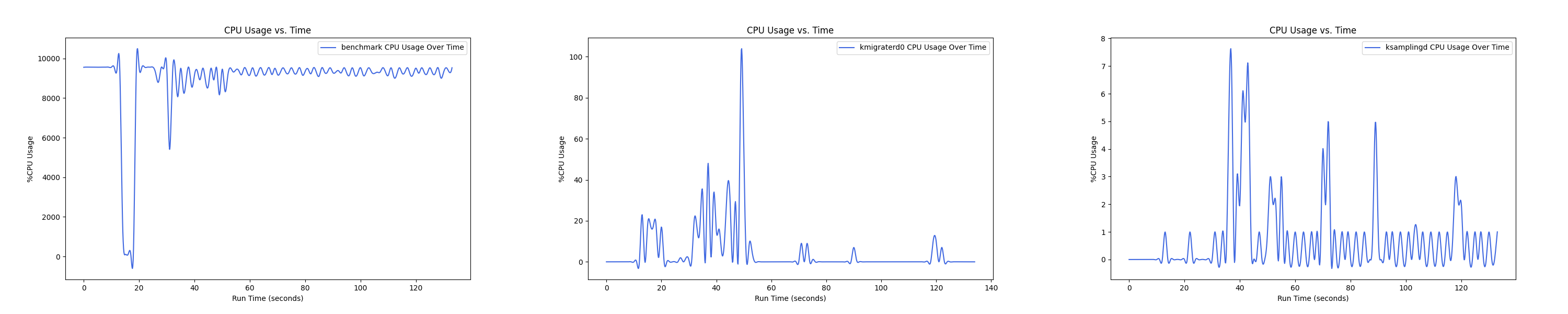
- 1 : 2 配置:
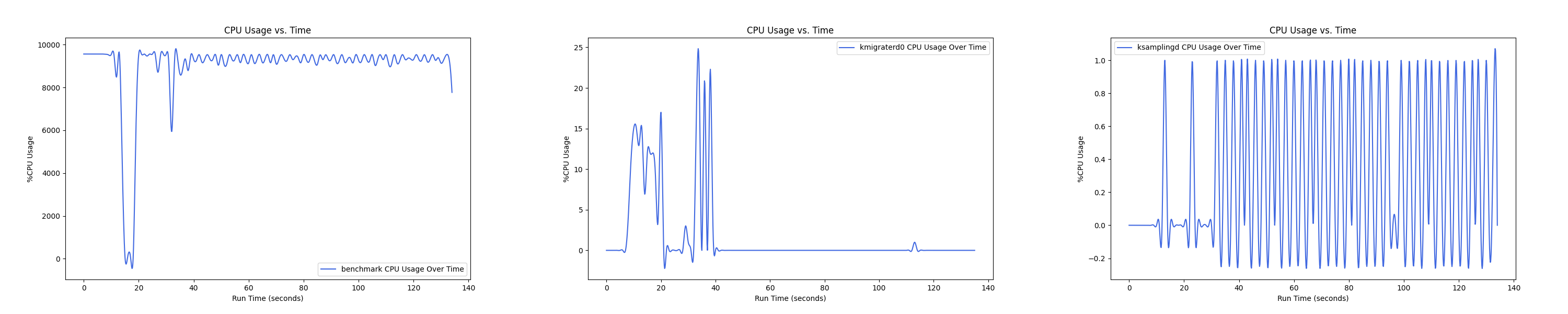
- 1 : 4 配置:
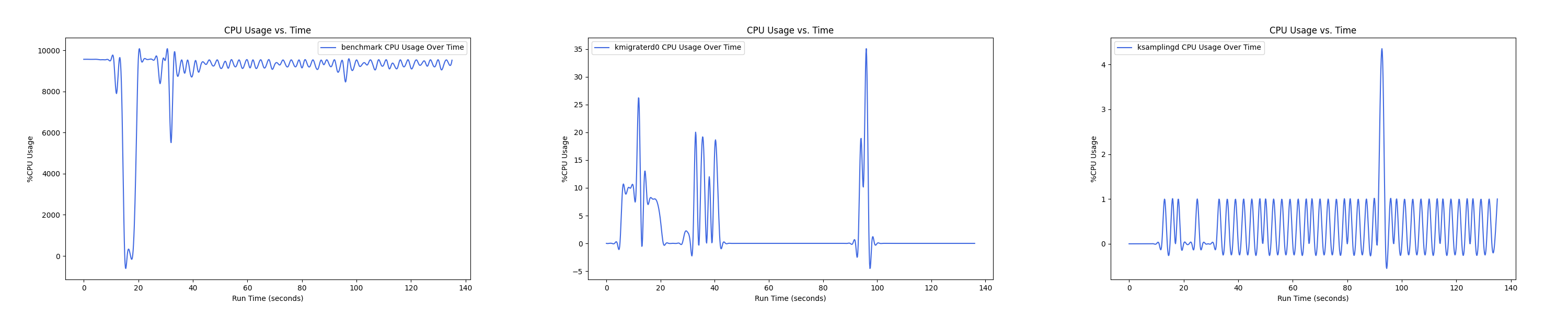
- 1 : 8 配置:
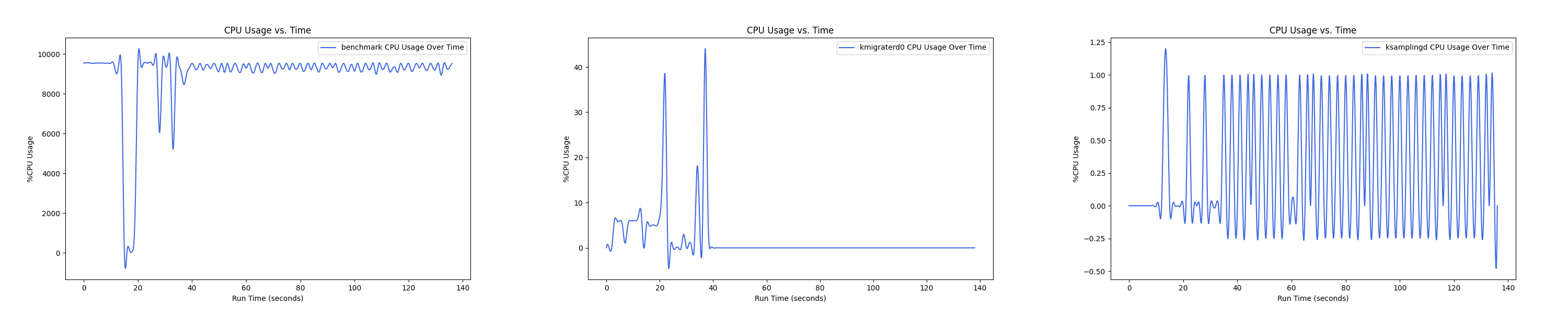
- 1 : 16 配置:
Graph500-192GB
测试时使用 omp-csr/omp-csr(OpenMP compressed-sparse-row implementation)版本,R-MAT scale 为 28,R-MAT edge factor 为 23。
RSS(Resident Set Size) 大约为 192GB。
| Traversed Edges Per Second (%) (relative to Baseline) | min_TEPS | firstquartile_TEPS | median_TEPS | thirdquartile_TEPS | max_TEPS | harmonicmean_TEPS |
|---|---|---|---|---|---|---|
| 1 : 16 | 53.4 | 84.1 | 86.3 | 86.8 | 85.6 | 84.1 |
| 1 : 8 | 86.1 | 83.6 | 84.1 | 87.1 | 87.7 | 85.7 |
| 1 : 4 | 52.5 | 94.1 | 93.8 | 98.0 | 98.7 | 94.3 |
| 1 : 2 | 64.1 | 90.1 | 92.3 | 96.6 | 96.1 | 89.4 |
| 1 : 1 | 55.8 | 91.3 | 96.3 | 98.9 | 100.0 | 93.1 |
| 1 : 0 | 100 | 100 | 100 | 100 | 100 | 100 |
MEMTIS kthreads and benchmark CPU usage:
- 1 : 0 配置:
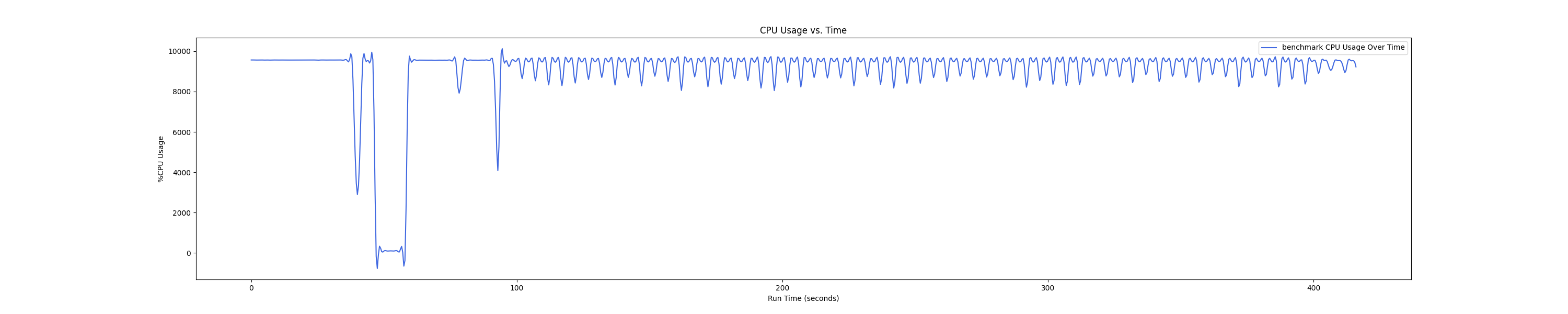
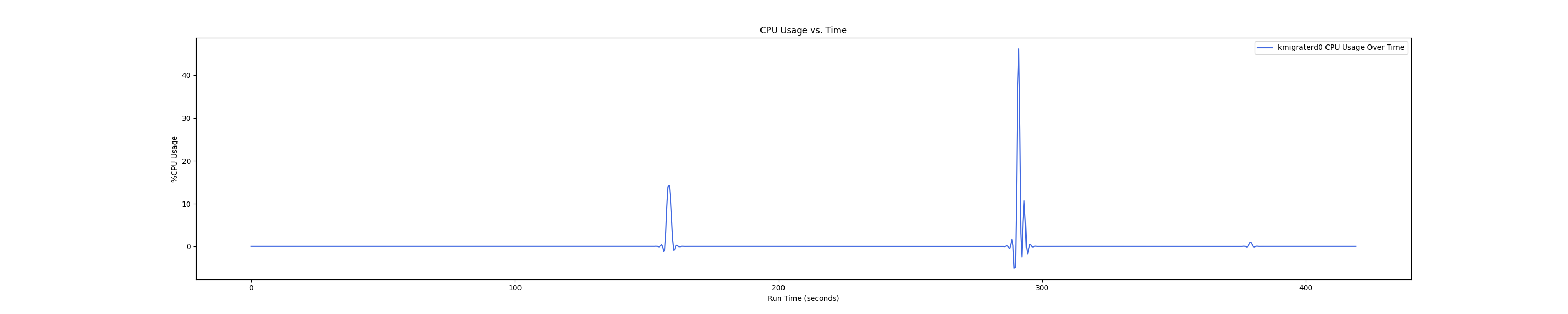
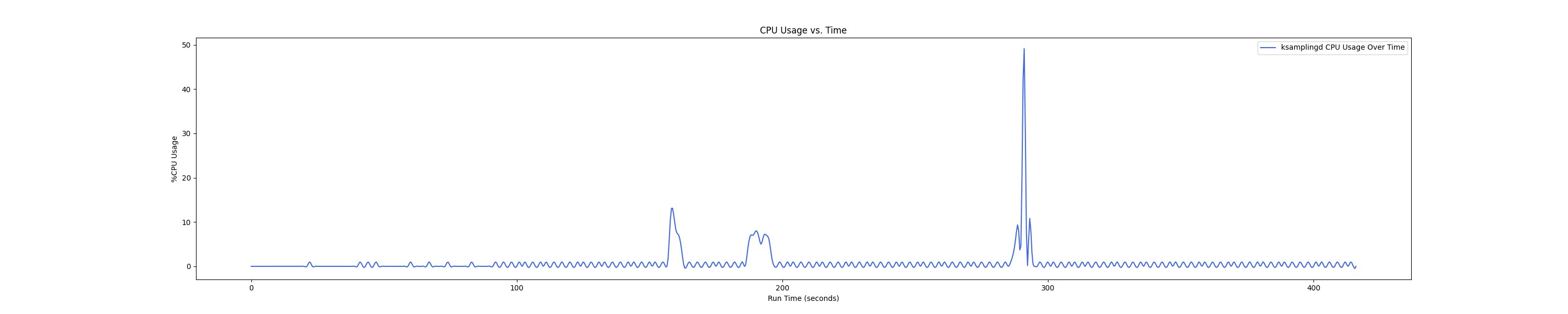
- 1 : 1 配置:
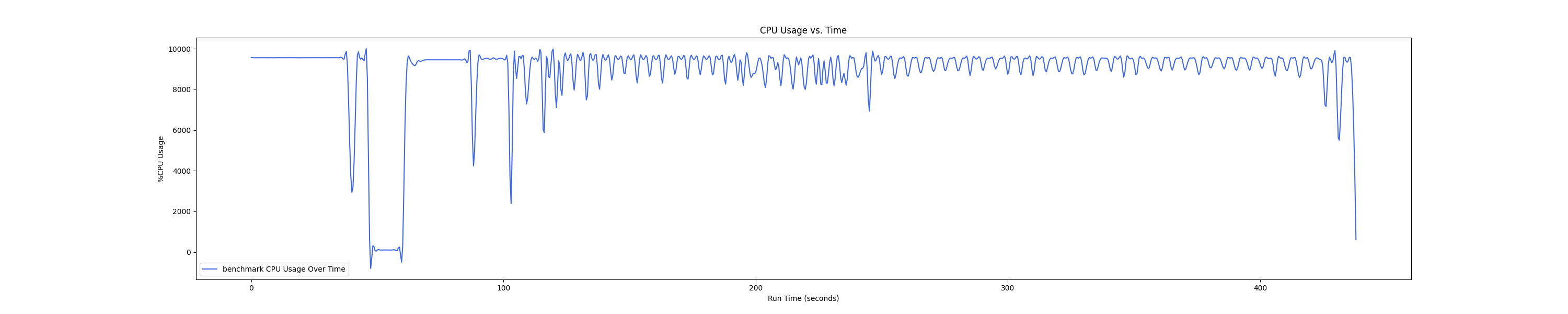
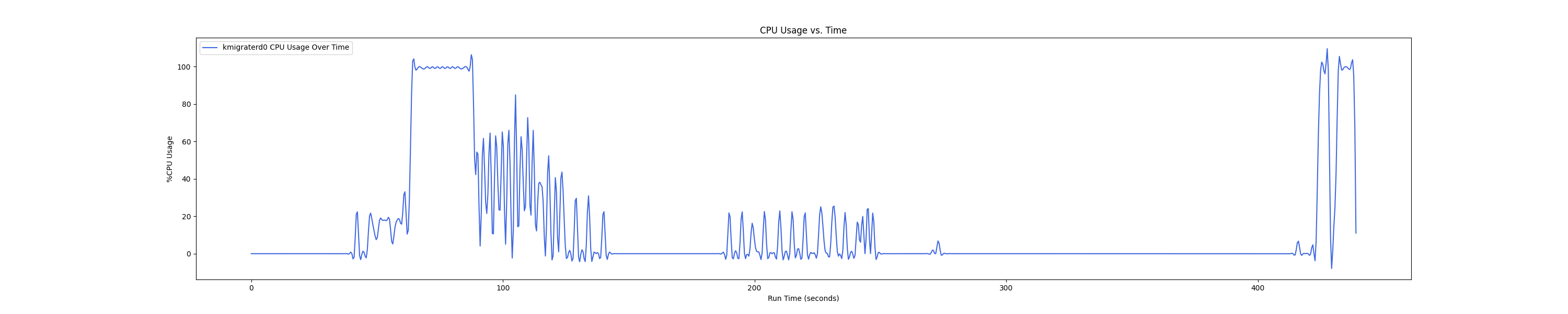
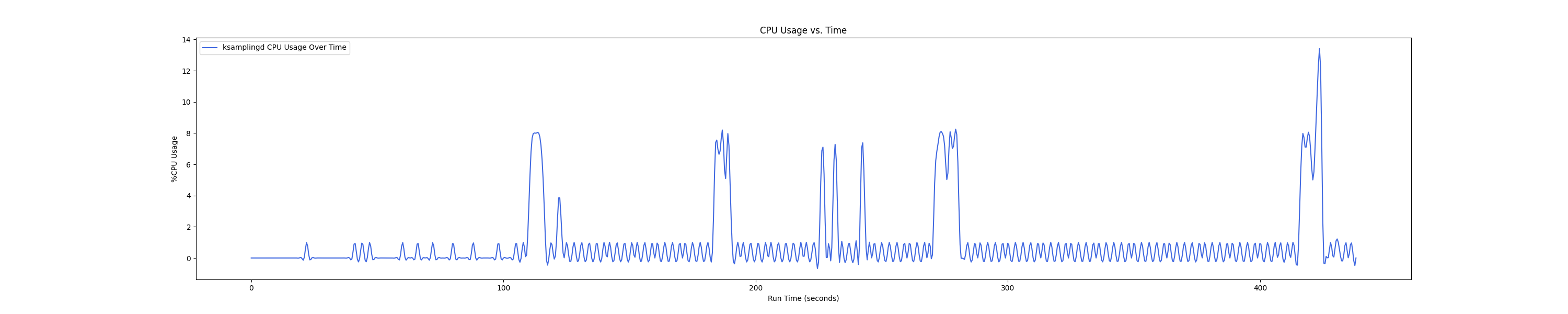
- 1 : 2 配置:
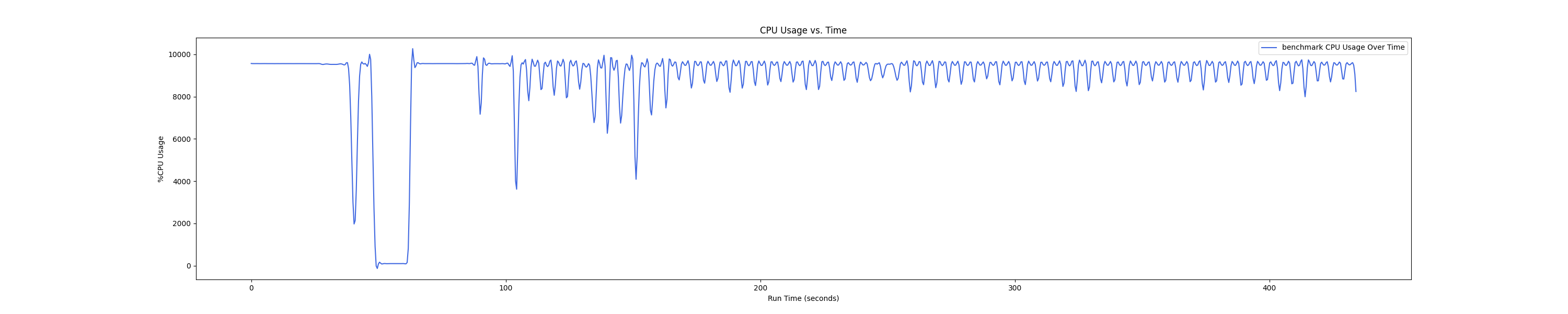
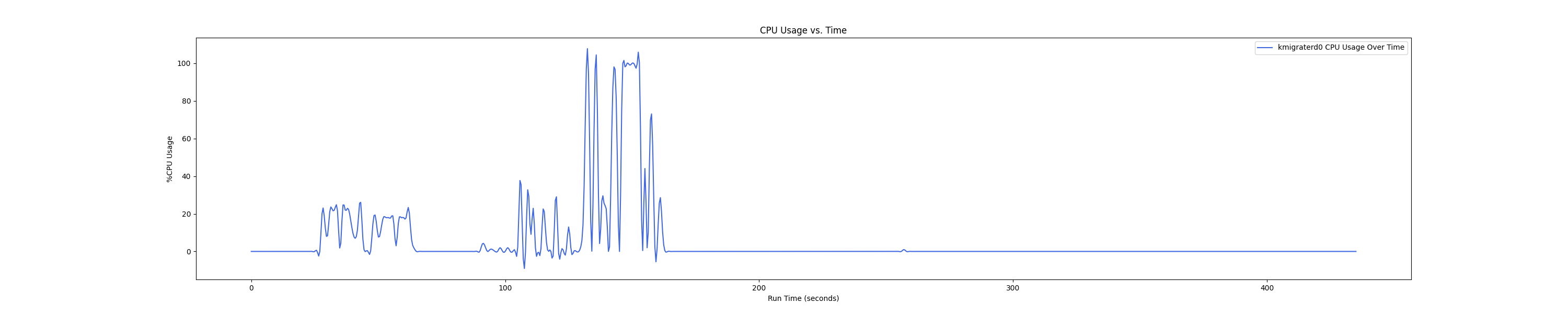
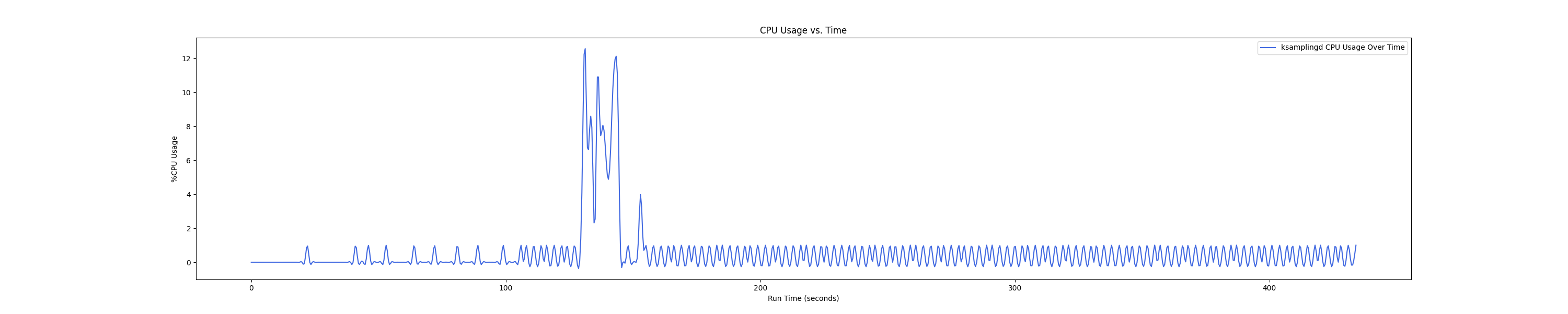
- 1 : 4 配置:
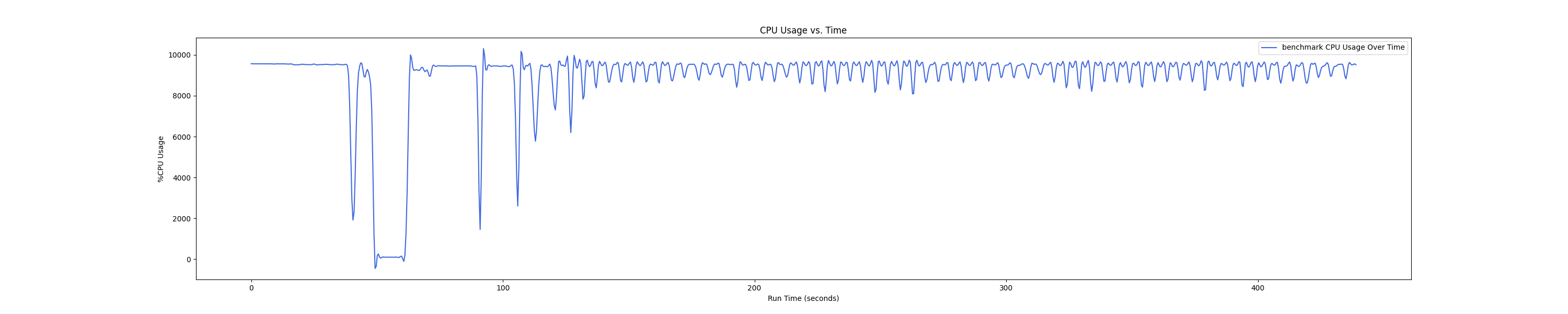
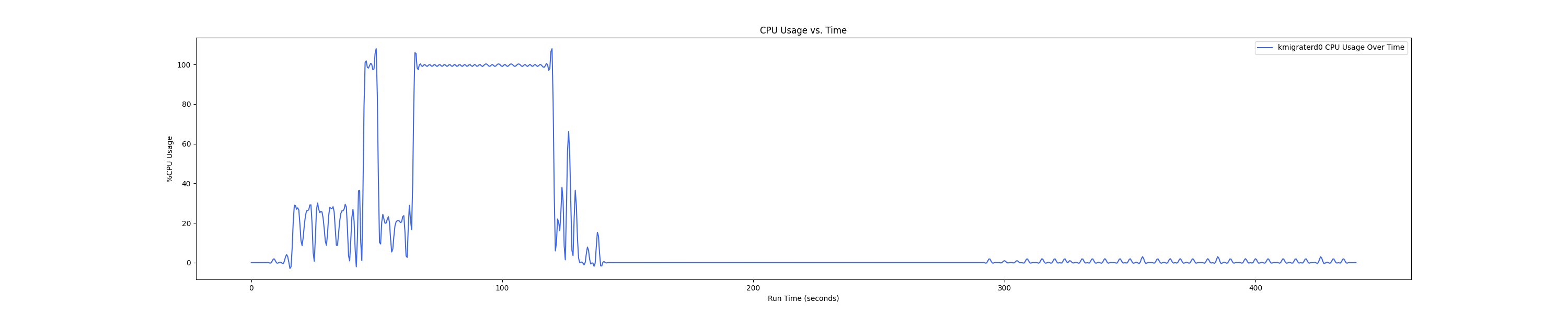
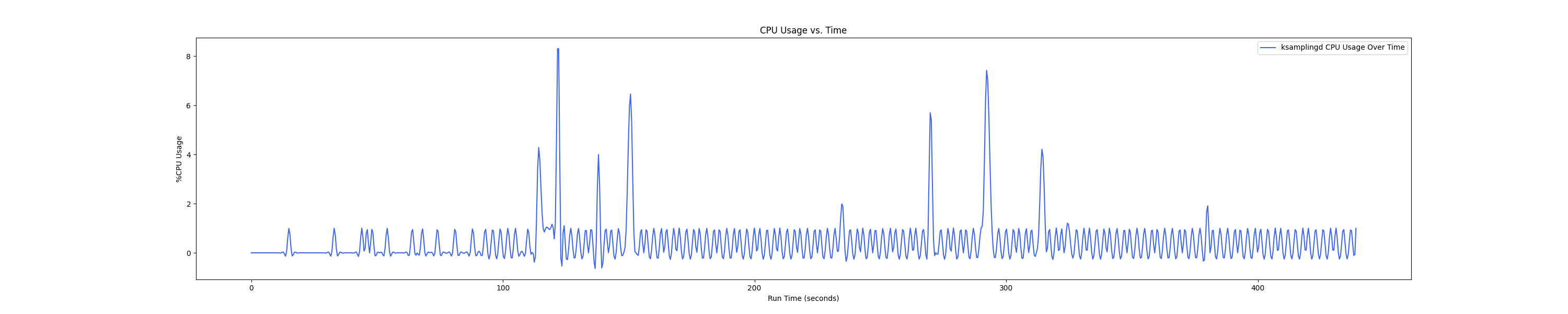
- 1 : 8 配置:
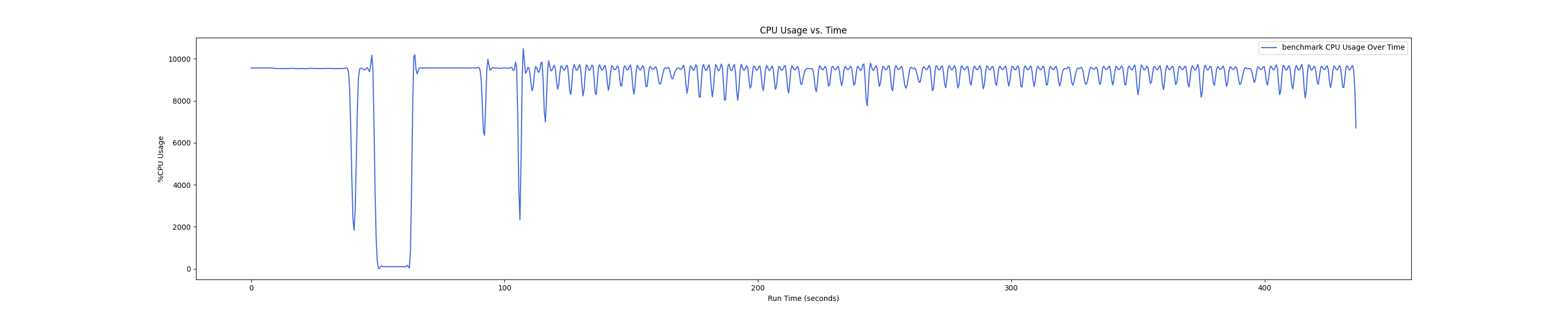
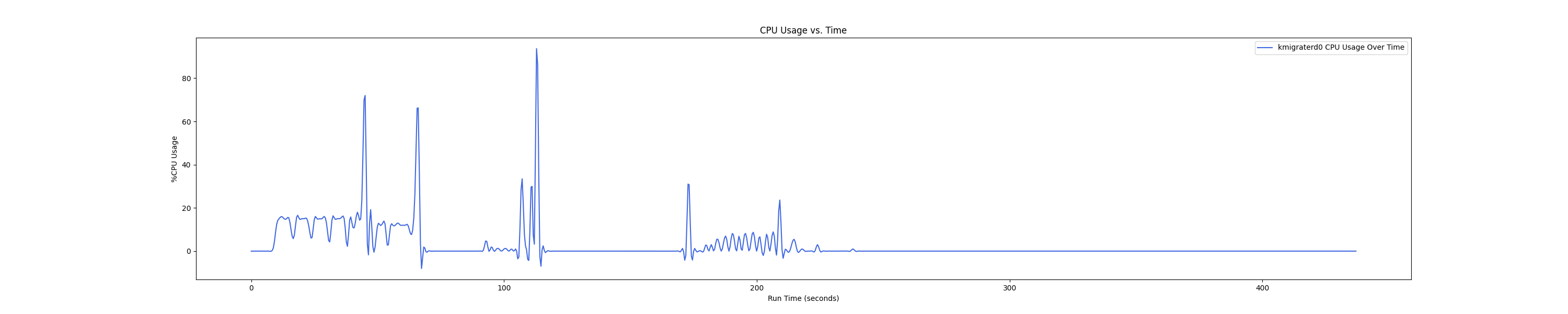
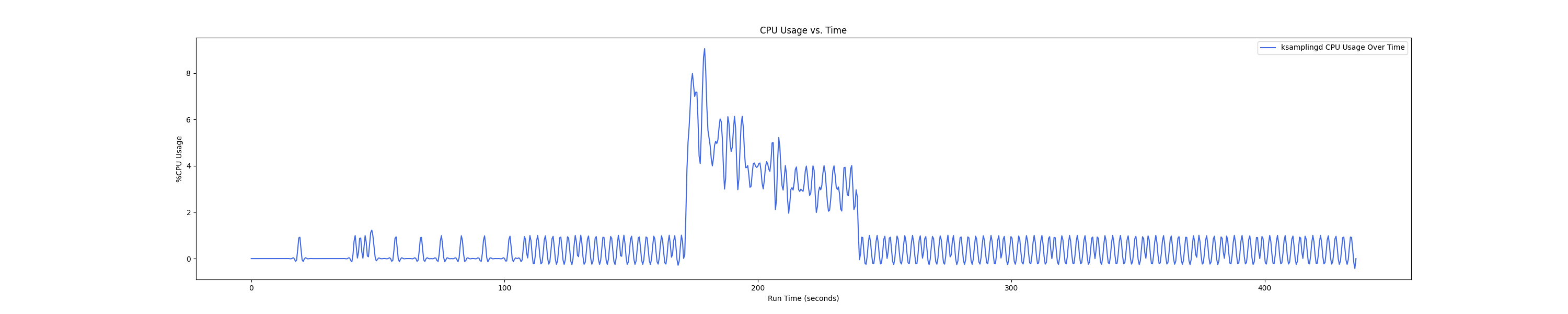
- 1 : 16 配置:
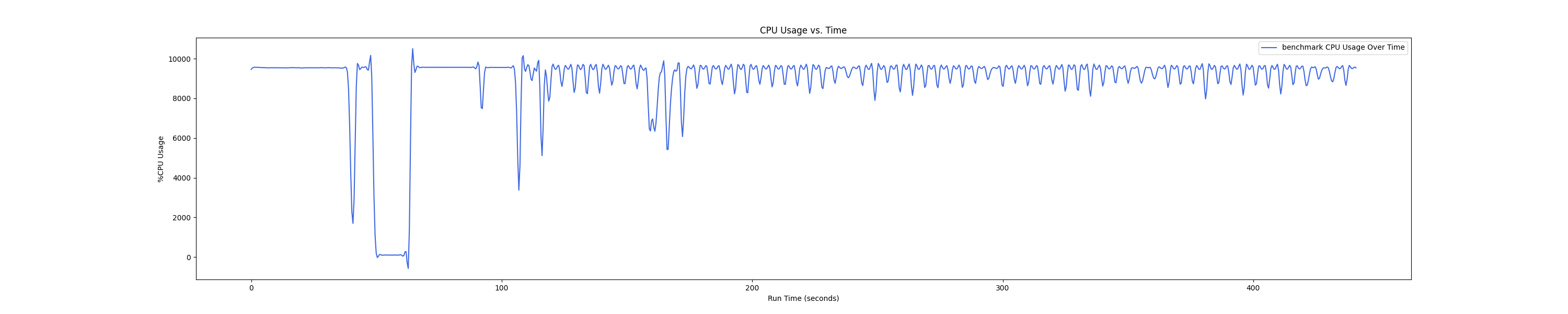
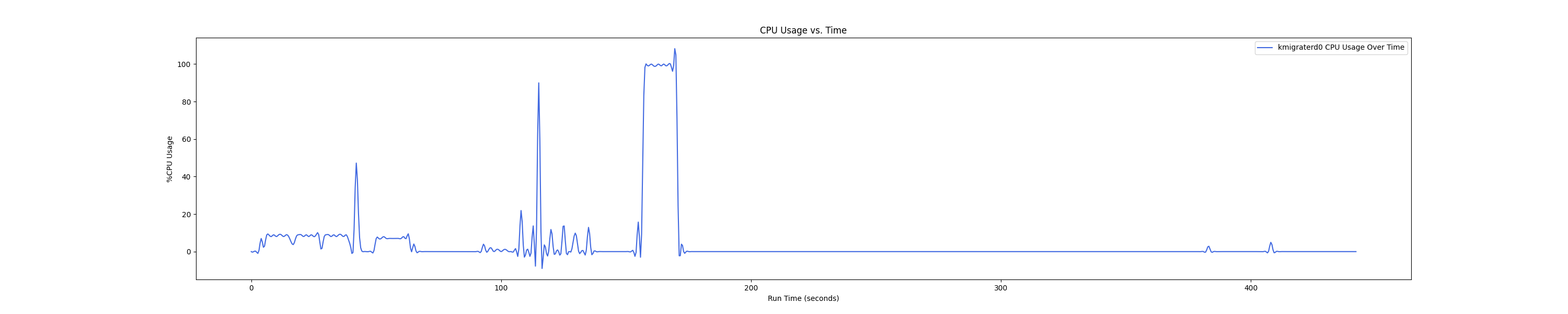
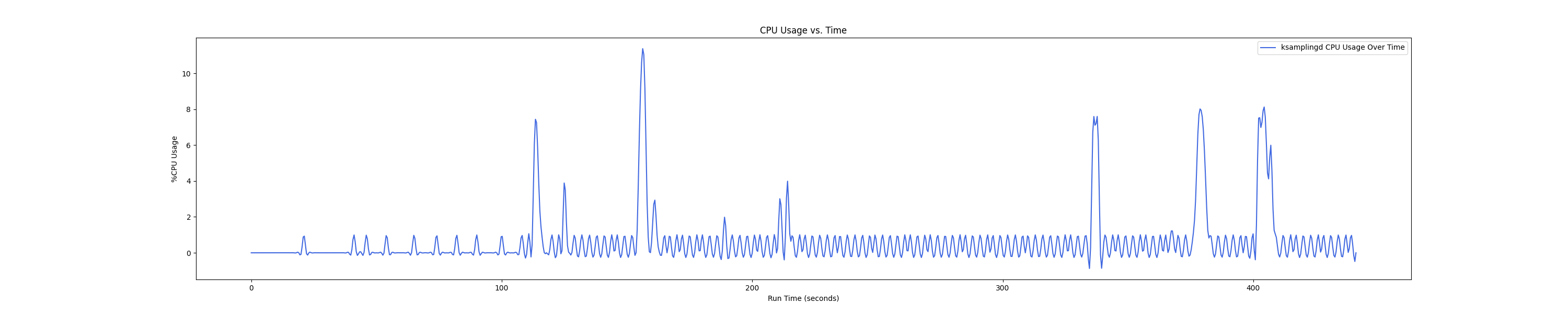
Insight:在 1 : 4 和 1 : 1 的 case 下 kmigraterd0 会有一段时间是满负载(100%)的 CPU overhead。
Btree
Btree is an in-memory index lookup.
RSS(Resident Set Size) 大约为 39G,单线程。NELEMENTS 配置为 $3.4 \times 10^8$,NLOOKUP 配置为 $2\times 10^7$ 。
| Memory Config (local : remote) | Execution Time Increase (%) (normalized to Baseline) |
|---|---|
| 1 : 16 | 10.9 |
| 1 : 8 | 9.6 |
| 1 : 4 | 5.9 |
| 1 : 2 | 5.5 |
| 1 : 1 | -4.1 |
| 1 : 0 | 0 |
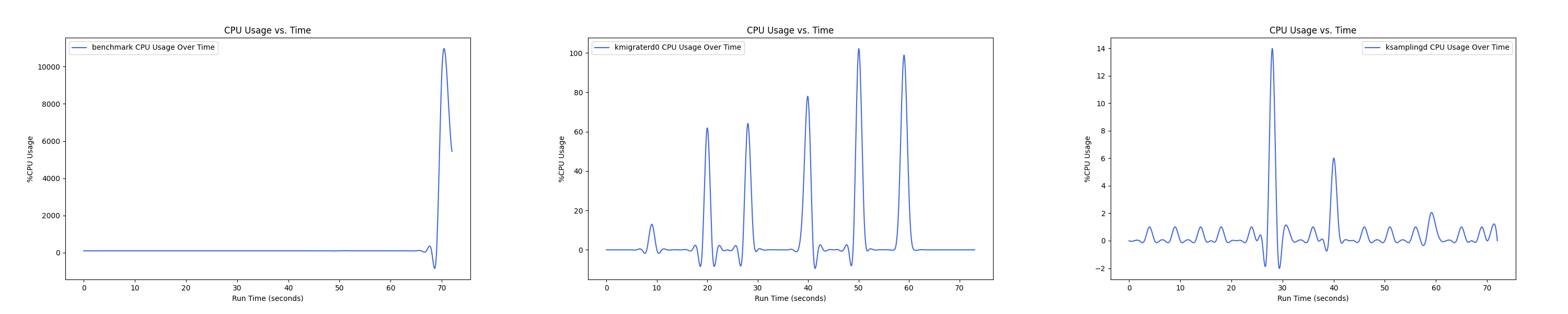
MEMTIS kthreads and benchmark CPU usage:
- 1 : 0 配置:
- 1 : 1 配置:
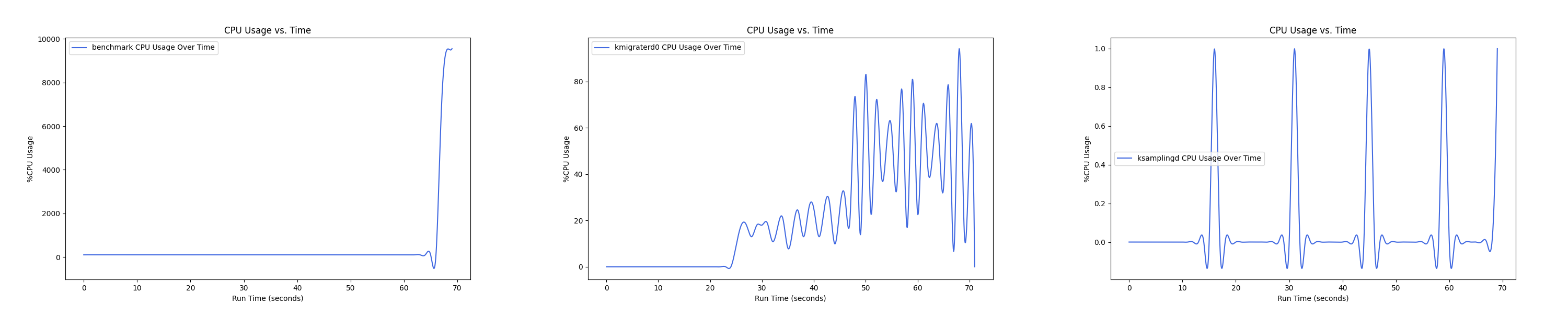
- 1 : 2 配置:
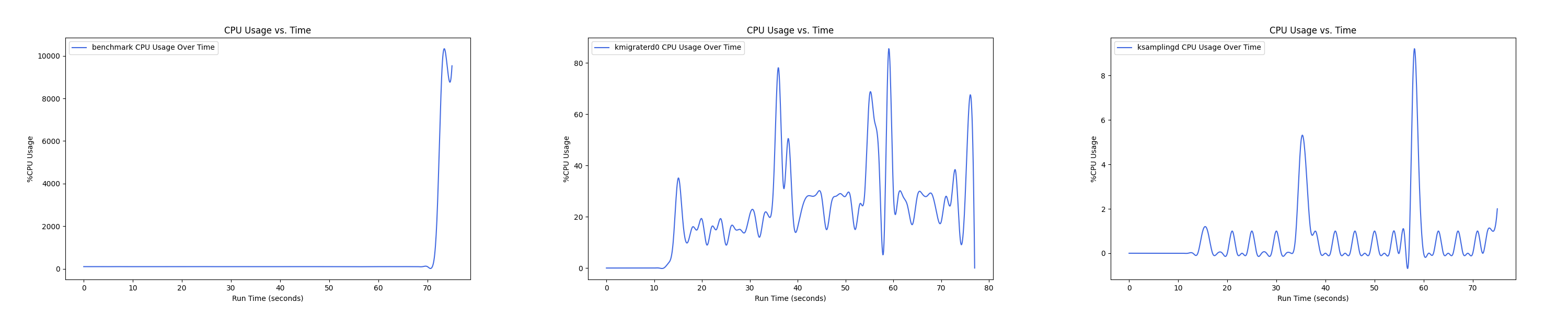
- 1 : 4 配置:
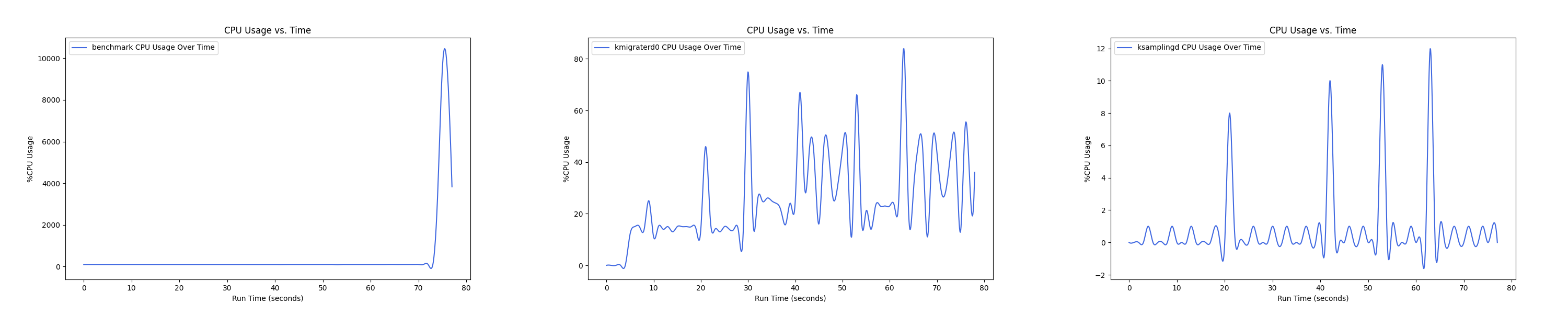
- 1 : 8 配置:
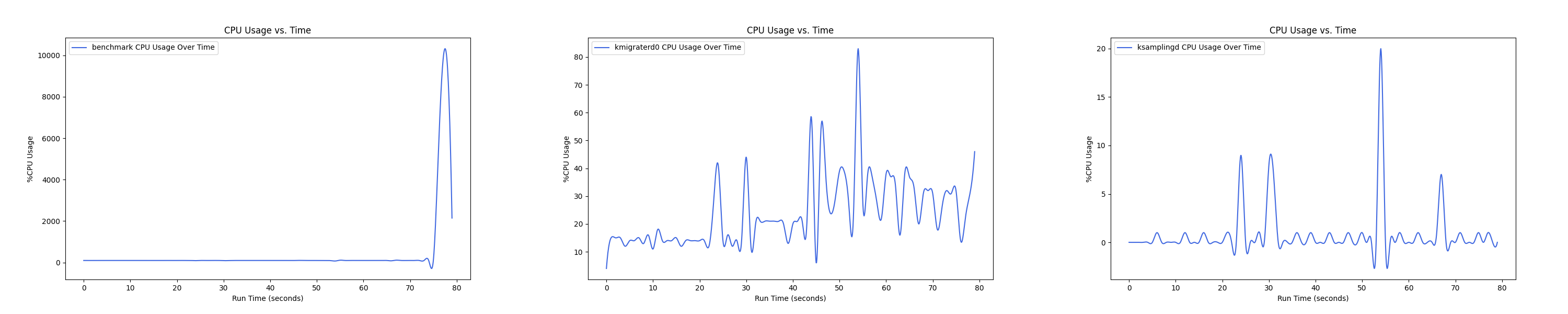
- 1 : 16 配置:
Insight:btree 负载下 kmigrated0 线程 CPU overhead 普遍较高,在 1 : 4 的 case 下达到峰值,随着非本地内存的比例继续增大,CPU overhead 反而在减小。
Liblinear
LIBLINEAR is a linear classifier for data with millions of instances and features. It supports
- L2-regularized classifiers
L2-loss linear SVM, L1-loss linear SVM, and logistic regression (LR)- L1-regularized classifiers (after version 1.4)
L2-loss linear SVM and logistic regression (LR)- L2-regularized support vector regression (after version 1.9)
L2-loss linear SVR and L1-loss linear SVR.- L2-regularized one-class support vector machines (after version 2.40)****
LIBLINEAR 是一个开源的机器学习库,专注于大规模线性分类,包括支持向量机(SVM)、逻辑回归(LR)、以及与这些方法相关的线性分类模型。LIBLINEAR 特别适合于处理那些特征数量远大于样本数量的数据集。
RSS(Resident Set Size) 大约为 69G,20 线程,求解器选择 L1-regularized logistic regression。使用 kdd12 数据集进行训练。
| Memory Config (local : remote) | Execution Time Increase (%) (normalized to Baseline) |
|---|---|
| 1 : 16 | 4.0 |
| 1 : 8 | 5.8 |
| 1 : 4 | -0.2 |
| 1 : 2 | 0.9 |
| 1 : 1 | -3.0 |
| 1 : 0 | 0 |
MEMTIS kthreads and benchmark CPU usage:
- 1 : 0 配置:



- 1 : 1 配置:



- 1 : 2 配置:



- 1 : 4 配置:



- 1 : 8 配置:



- 1 : 16 配置:



PageRank
GAP 基准测试套件旨在通过标准化评估来帮助图处理研究。图处理评估之间的差异较少将使比较不同研究工作和量化改进变得更容易。这一基准测试不仅指定了图核心、输入图和评估方法论,而且还提供了一个优化的 baseline 实现。这些 baseline 实现代表了最先进的性能,因此新的贡献应该超越它们以展示改进。
笔者使用 Twitter 数据集生成图表并运行 PageRank 算法的 20 次迭代。PageRank (PR) 代表 iterative method in pull direction。
RSS(Resident Set Size) 大约为 12600MB ,20 次 trials,最多 1000 次迭代,tolerance 为 $10^{-4}$。
| Memory Config (local : remote) | Average Trial Time Increase (%) (normalized to Baseline) |
|---|---|
| 1 : 16 | 15.2 |
| 1 : 8 | 13.4 |
| 1 : 4 | 11.5 |
| 1 : 2 | 10.8 |
| 1 : 1 | 7.5 |
| 1 : 0 | 0 |
- 1 : 0 配置:
- 1 : 1 配置:
- 1 : 2 配置:
- 1 : 4 配置:
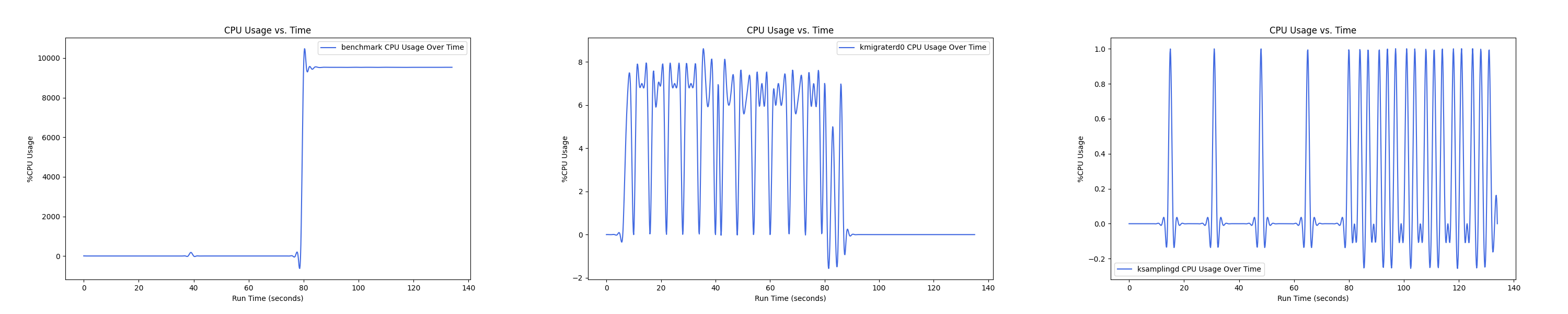
- 1 : 8 配置:
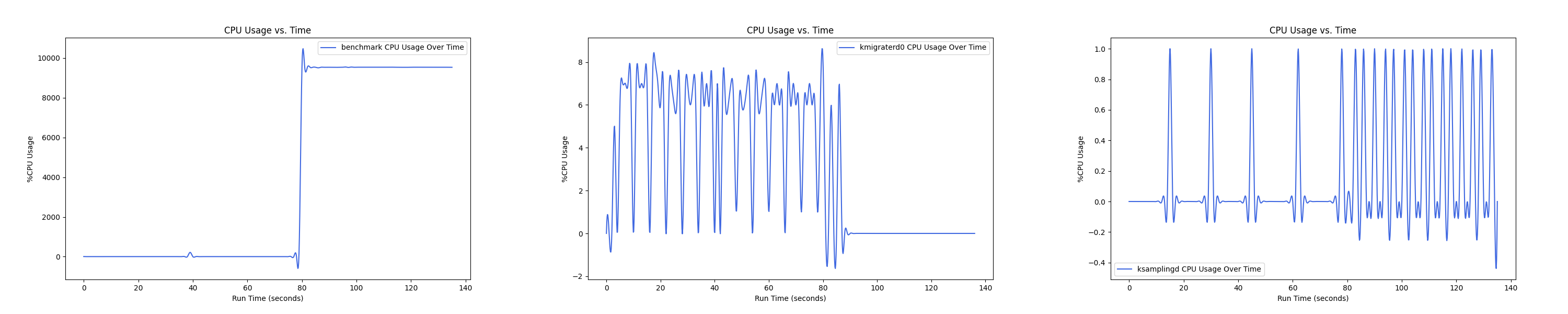
- 1 : 16 配置:
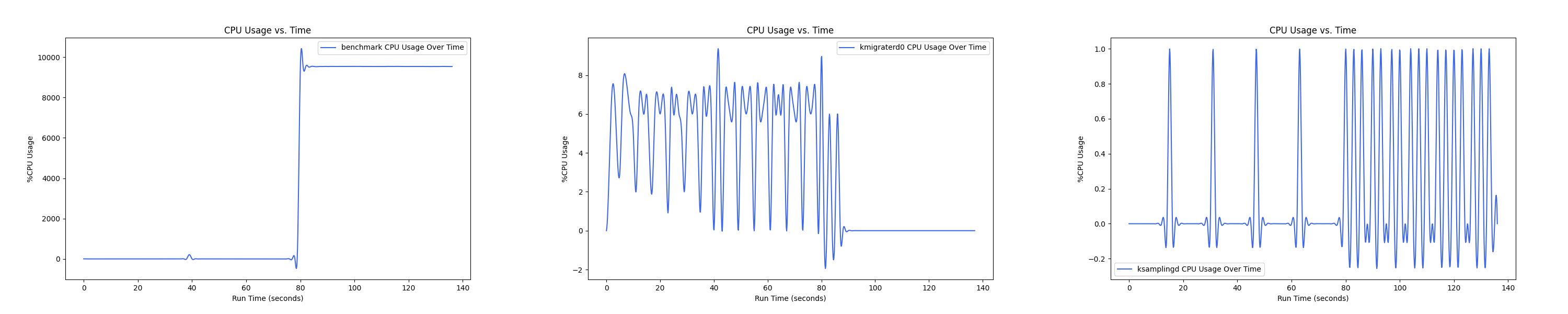
MLC 测试结果
Intel® Memory Latency Checker v3.11
确定应用程序性能的一个重要因素是应用程序从处理器的缓存层次结构和内存子系统中获取数据所需的时间。在启用非一致性内存访问(NUMA)的多插槽系统中,本地内存延迟和跨插槽内存延迟会有显著差异。除了延迟之外,带宽(b/w)在确定性能方面也起着重要作用。因此,测量这些延迟和b/w对于建立测试系统的基线以及进行性能分析非常重要。
英特尔®内存延迟检查器(Intel® MLC)是一个用于测量内存延迟和b/w的工具,以及它们随系统负载增加而变化的情况。它还提供了几个更细粒度调查的选项,其中可以测量来自特定核心组到缓存或内存的b/w和延迟。
Intel(R) Memory Latency Checker - v3.11
Measuring idle latencies for sequential access (in ns)...
Numa node
Numa node 0 1
0 111.6 192.0
1 191.0 111.8
Measuring Peak Injection Memory Bandwidths for the system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using traffic with the following read-write ratios
ALL Reads : 530501.3
3:1 Reads-Writes : 479746.6
2:1 Reads-Writes : 467437.8
1:1 Reads-Writes : 445906.0
Stream-triad like: 471268.4
Measuring Memory Bandwidths between nodes within system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using Read-only traffic type
Numa node
Numa node 0 1
0 264500.5 127408.0
1 127457.3 264561.1
Measuring Loaded Latencies for the system
Using all the threads from each core if Hyper-threading is enabled
Using Read-only traffic type
Inject Latency Bandwidth
Delay (ns) MB/sec
==========================
00000 238.22 529505.9
00002 238.37 529655.6
00008 237.26 528865.1
00015 230.48 521805.9
00050 218.13 521693.8
00100 197.44 509926.6
00200 131.93 268851.9
00300 125.93 192296.8
00400 121.21 146072.0
00500 118.66 117769.3
00700 116.21 85037.5
01000 114.73 60010.9
01300 114.24 46478.3
01700 113.86 35756.3
02500 113.53 24580.7
03500 113.33 17750.2
05000 113.60 12611.2
09000 113.11 7304.9
20000 112.93 3642.7
Measuring cache-to-cache transfer latency (in ns)...
Local Socket L2->L2 HIT latency 82.5
Local Socket L2->L2 HITM latency 83.3
Remote Socket L2->L2 HITM latency (data address homed in writer socket)
Reader Numa Node
Writer Numa Node 0 1
0 - 173.5
1 173.0 -
Remote Socket L2->L2 HITM latency (data address homed in reader socket)
Reader Numa Node
Writer Numa Node 0 1
0 - 176.2
1 175.8 -
Appendix
cgroup v2 特性移植
Can I find the base version of the *.patch file?
How to apply patch without knowing the original version the diff file comes from?

刘爷爷能教教我 Linux 2.6.38 Memory Manager 是如何实现的的吗? %%%
作者你好,很高兴能看到你做这个测试,我有一个疑问,就是要添加这个被控制的PID这里不是太清楚,这个是一个shell界面嘛?还是首先先给内存设定好,然后,执行redis的脚本,然后将其进程号添加到htmm这个下面?希望作者方便的时候解答我的一个疑问,邮件号所对应是我的QQ号,有问题向你请教。