摘要和引入
数据中心工作负载推动的不断增长的内存需求是新内存技术创新(例如 NVM、CXL),Tiered meory 是一种很有前景的解决方案,它利用具有不同容量、延迟和成本特征的多种内存类型,努力降低服务器硬件成本,同时满足内存需求。
MEMTIS 和 TPP 类似,也是一种分层内存系统,采用“智慧”地决策来进行 page placement 和 page size determination,可以在有限地 CPU 开销内根据页面访问分布和 skewness-aware page size 来做出决策。论文实验表明 MEMTIS 比现有最好的分层内存系统 performance 高出 33.6% ~ 169.0%。
现有分层内存系统分析

Tracking Memory Accesses 是做出置换决策之前至关重要的一步,目前主流有 Software-based 和 Hardware-based 两种策略:Page table-based access tracking / Page fault 和 Hardware-based memory access sampling.
Page table-based access tracking / Page fault 有以下几个缺点和限制:
- 会触发额外的 page faults 和 TLB shootdowns,从而产生额外的开销
- 产生的额外开销会随着 memory size 的增大而变大
- 粒度只能达到 4KB page,对 huge pages 不适用
Hardware-based memory access sampling:现代处理器提供了硬件级的 event-based 采样机制,即 Intel 的 Processor Event-Based Sampling (PEBS) 和 AMD 的 Instruction-Based Sampling (IBS)。event-based 采样可以在不扫描页表的情况下得到精确的内存访问地址,其开销是随着采样频率增加而增加(因此可以根据 CPU 当前的使用率来动态调节采样率,后文介绍的 MEMTIS 即是如此)。
完成 Tracking Memory Accesses 后下一步就是 Deciding Where to Place Pages。现有分层内存系统需要根据一个 hotness metrics 来区分出 hot pages 和 cold pages,hotness metrics 最常见的即是 recency 和 frequency。尽管 recency 数据可以被很高效地采集,但它不能很好地反应 page 的访问历史,而 frequency 可以弥补 recency 的有限性。一个优秀的分层内存系统应该使用准确的 hotness metrics,并根据工作负载特征和当前系统配置来动态调整 hotness metrics。
在迁移页面的过程中我们还需要考虑 Mitigating Address Translation Cost。事实上,地址转换的开销已经是内存密集型应用程序众所周知的一个 bottleneck 了,随着内存占用量的增加,TLB miss 的可能性随之增大。目前一种常用做法是通过使用 huge pages 是来增加 TLB 的内存管理范围和降低 TLB miss 带来的损失(可以由四级页表变为三级页表),随之而来的问题是这也让 huge pages 的迁移开销更大。因此,迁移利用率低的热大页会浪费快速层中的内存,分层内存系统应该根据页面热度和大页面利用率动态决定合适的页面大小。
MEMTIS 设计结构
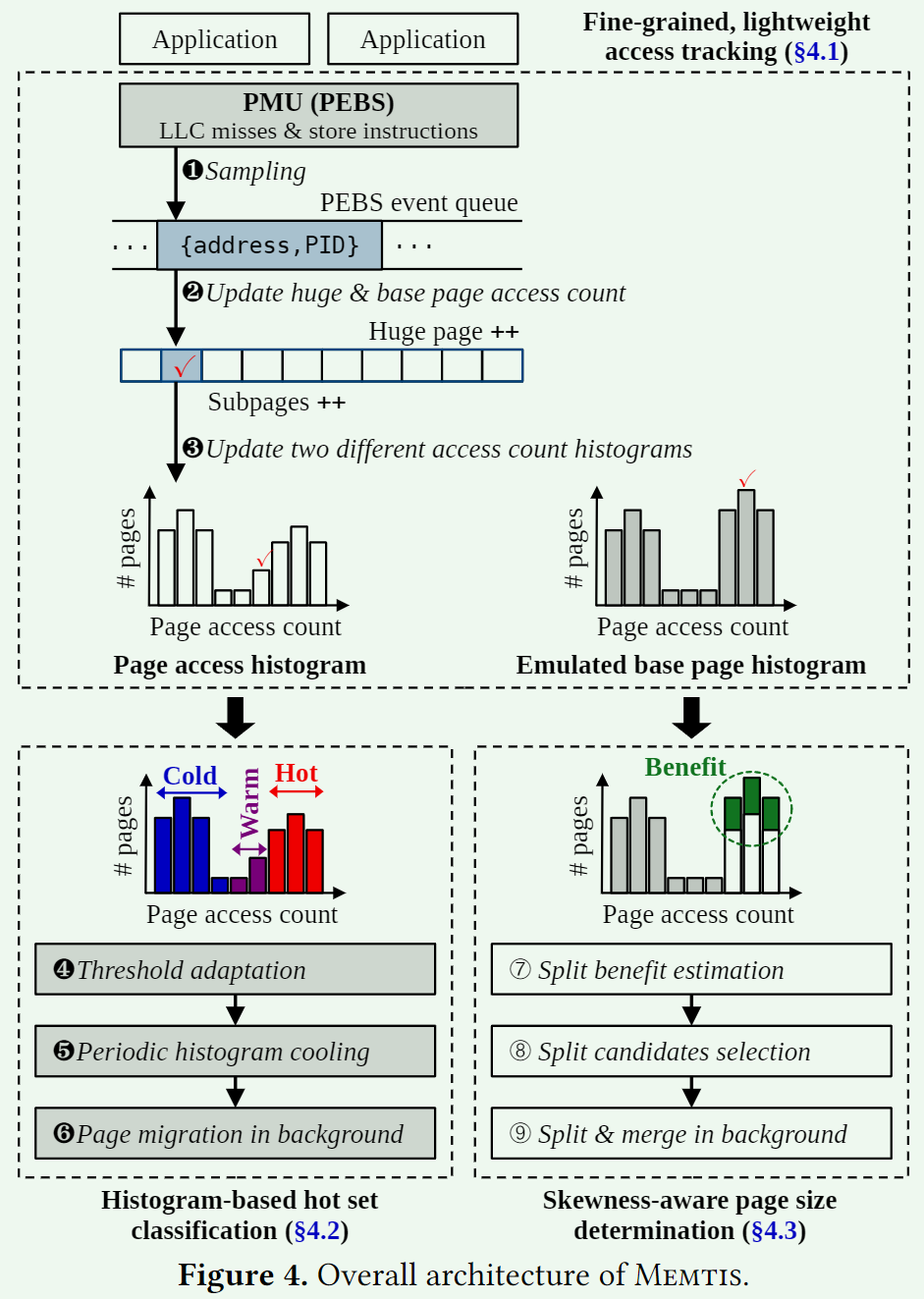
MEMTIS 的总体结构图如上图所示,在接下来的介绍中会频繁出现 huge page 和 base page,这里先做区分:
- huge page:是一种较大的内存分配单元,用于优化大型内存访问的性能,单个 TLB 条目可以映射较大的内存块(例如 2MB 或 1GB)
- base page:通常意义的 page,一般是 4KB 大小,内存管理中的最小分配单元,用于细粒度的内存访问和管理
MEMTIS 的总体架构可以分为下面三个部分:
- Fine-grained, lightweight access tracking:MEMTIS 通过 PEBS 机制进行采样。
ksampled是 MEMTIS 管理的后台内核线程,它根据采样的结果来更新内存访问统计数据和两张直方图:page access histogram 和 emulated base page histogram(记住这两张图,后面会用到)。MEMTIS 动态调整采样频率,以保证 CPU 的开销低于 3%。 - Histogram-based hot set classification:MEMTIS 通过 page access histogram 来维护页面分布热度,根据访问计数来动态调整 hot, warm, cold 的阈值。通过 cooling 操作来保持直方图数据的新鲜度(本质上是指数移动均值)。最后通过后台线程
kmigrated来完成页面的升降迁移。 - Skewness-aware page size determination:MEMTIS 启用了 Linux 的 Transparent Huge Pages (THP) 来降低地址转换成本,当 THP 中只有一小部分子页被频繁访问时(即 THP 利用率较低时),MEMTIS 会根据长期谨慎地观察,根据 split benefit estimation 和 skewness 将 THP 拆分。MEMTIS 是第一个根据 subpage access skewness 来动态决定 page size 的系统。
MEMTIS 细节讲解
MEMTIS 使用 PEBS 对 LLC load miss 和存储指令进行采样,以进行细粒度的访问跟踪。动态调整采样间隔,以在有限的开销下最大化采样事件的数量。 ksampled 定期计算其 CPU 使用率的指数移动平均值,并调整采样间隔(使用 __perf_event_period)以满足其 CPU 使用率不超过上限(默认为单核的 3%)。实验数据表明,在所有评估的基准测试中,ksampled 仅消耗了单核 CPU 的 2.016%,平均性能开销为 0.922%
MEMTIS 为 all page types (i.e., base page, huge page, subpage in a huge page) 维护了元数据:hotness。为huge pages 维护了元数据:utilization 和 skewness。
hotness 代表了一个页面的访问趋势,即页面访问次数的指数移动平均值(exponential moving average,EMA),对于页面 $i$ 其 hotness $H_i$ 的计算公式如下:
$$
H_i =
\begin{cases}
C_i & \text{if page }i\text{ is a huge page} \\
C_i \times \tt{nr\_subpages} & \text{if page }i\text{ is a base page}
\end{cases}
$$
其中 $C_i$ 代表 page $i$ 的 access count,nr_subpages 代表一个 huge page 由多少个 subpages 构成(i.e., 512 in x86)。由于 huge pages 的访问可能性是 subpages 的 nr_subpages 倍,所以对于 subpages 需要乘一个 nr_subpages 系数补偿。
一张 page access histogram 默认是由 16 个 bins(二进制区间)组成。每一个 bin 代表一个 hotness 的区间,类似树状数组。第 n-th bin 代表的 hotness 区间范围是 $\left[2^n, 2^{n+1} \right)$,最后一个 bin 的上限是 $\infty$。这种设计很符合页面访问分布的非线性增长的特征,即热页的访问量比温页或冷页多几个数量级,也为后面的 EMA 计算带来了方便(稍后会讲)。
需要注意的是,MEMTIS 总共维护了两个直方图:page access histogram 和 emulated base page histogram。MEMTIS 使用前者来决定 hot pages,使用后者来决定 page sizes。
MEMTIS 对于页面分类,维护了 3 种阈值:$T_{hot},\ T_{warm},\ T_{cold}$。如果 page $i$ 的 bin index $B_i \ge T_{hot}$,则会被放置在快速层;如果 $B_i \le T_{cold}$ ,则会被放置在容量层;否则 $T_{cold} \lt B_i \le T_{warm}$,MEMTIS 保留其页面所在位置不变。
上述 3 种 threshold 的计算具体计算算法如下:

笔者觉得第 2 行的条件应该写错了,应该是 and 吧。
第 7-11 行是计算 $T_{warm}$ 的,其实仔细一想,决定 cold, warm, hot 三种热度只需要两个 threshold 就行啦,为什么作者要计算 3 个 threshold 呢?因为类似与 TPP 中的 ping-pong 现象,为了避免在 $T_{hot}$ 边缘的页在 demote 后又很快被 promote 了,引入了 $T_{warm}$ 这一 threshold(前文说了,warm pages 不会被降级)。第 7-11 行的 $\alpha$ 默认为 0.9,如果 size of the identified hot pages 不是很接近快速层的容量(即小于等于 $MS_{fast} \times \alpha$),令 $T_{warm} = T_{hot}$ ,让 hotness 等于 $T_{hot}$ 的页面不要很快被 demote,避免来回迁移的 ping-pong 现象。
MEMTIS 每进行 $10^5$ 次采样事件后,更新一次 threshold。
为了反应 recent acccess,MEMTIS 周期性地让直方图的数据减半(即 $C_i$ 减半),这个过程称为 cooling。由于我们使用的是 EMA 指数移动平均值,其 decay factor 为 0.5,而我们的直方图的下标又是以二进制指数倍增的,因此 cooling 操作只需要将直方图的每个 bin 向左移动一位,当然对于 highest bin index 需要特殊处理一下。
MEMTIS 每 $2 \times 10^6 $ 条记录执行一次 cooling,考虑到 GB 级快速层内存大小,这已经足够了。
MEMTIS 为每个内存层创建一个 kmigrated 内核线程,并在后台执行所有升级和降级操作。升级列表仅包含 hot pages,而降级列表同时包含 warm pages 和 cold pages(有点前后矛盾?)。
kmigrated 线程每间隔 500ms 被定期唤醒。当快速层中的可用内存低于可用空间阈值(2%)时,快速层 kmigerated 将开始降级,它首先将降级列表中的 cold pages($H_i \le T_{cold}$)降级到容量层,如果降级 cold pages 后获得了足够的可用空间,则 kmigrated 将停止。否则,它将把 warm pages 降级到容量层,直到获得足够的可用空间。
如前文所述,splitting a huge page 的成本非常高,涉及到页表更新和 TLB shootdown,因此 MEMTIS 会根据长期页面访问历史来估计大页面拆分的最大收益,然后确定需要分割多少个 pages,最后在后台进行页面类型转换。
为了评估 huge page split 的收益,我们需要计算两个指标:$eHR$ 和 $rHR$。
- $eHR$:仅通过 base pages 来计算的 estimated hit ratio。类似之前的做法,计算一个 $T_{hot}^{BP}$ 阈值,如果访问的 huge pages 所对应的 subpage 或者 base page 比 $T_{hot}^{BP}$ 热,则 $eHR$ 增加 1(前后矛盾?)。
- $rHR$:如果访问的地址位于快速层,则 $rHR$ 增加 1。
MEMTIS 在对大量内存访问进行采样时进行效益评估,根据长期、稳定的内存访问趋势才做出决策。具体地,仅在 $(eHR – rHR)$ 大于 5% 的时候才会进行 split。
MEMTIS 使用如下公式来计算需要 split 的 huge pages 的数量:
$$
N_s = \min \{ (eHR-rHR) \times \frac{\Delta L}{L_{fast}} \times \frac{\mathtt{nr\_sampeles}\times \beta}{\mathtt{avg\_samples\_hp}}, \frac{\mathtt{nr\_sampeles}}{\mathtt{avg\_samples\_hp}} \}
$$
其中 $(eHR – rHR)$ 是预期 benifit,$\Delta L$ 是 capacity tier($L_{cap}$)和 fast tier($L_{fast}$)的 latency gap。为了近似表示未来一段时间内 distinct huge pages 被访问的大概数量带来的 benefit,我们通过 $\dfrac{\mathtt{nr\_sampeles}}{\mathtt{avg\_samples\_hp}}$ 计算出总的 distinct huge pages 数量,再乘上一个 $\beta$ 系数($\beta = 0.4$)。当然 $N_s$ 不能超过总的 distinct huge pages 数量,因此有个 $\min$。
在确定要拆分的大页数量后,MEMTIS 根据子页访问 skewness 来决定拆分哪些大页。具体地,对于 page $i$ ,其计算公式如下:
$$
S_i = \frac {\sum_{j=0}^{\mathtt{nr\_subpages}} H_{ij}^2}{U_i^2}
$$
其中 $U_i$ 表示在第 $i$ 个 huge page 中 hot subpages 的数量,即满足 $T_{hot}^{BP} \le H_{ij}$ 的数量。当 huge page 的利用率降低时,$U_i^2$ 降低,$H_{ij}^2$ 会上升,从而 $S_i$ 会增大。
kmigrated 线程会在后台进行页面类型转换和迁移。具体来说,根据 hotness($H_{ij}$)来把拆分后的子页面分为 hot pages 和 cold pages。
另外,将 base pages 合并为 huge page 的成本也很高,需要考虑新合并的 huge page 的 hotness 和 skewness。因此,MEMTIS 仅当所有组成的 base pages 都是 hot pages 的时候才会进行合并。合并很少发生,因为 MEMTIS 启用了 transparent huge page (THP),并且拆分 huge pages 很保守。
MEMTIS 测试
请参加上一篇文章:Memtis: Efficient Memory Tiering with Dynamic Page Classification and Page Size Determination 复现与测试
