[toc]
看完 CSAPP 五六章后,摆了一天玩 PVZ2,来做 Performance Lab,
做完了继续 PVZ2
Performance Lab 介绍
这个 lab 在 CMU 已经被Cache Lab取代了,听说 Cache Lab 比较难,就先做这个 lab 练练手。基于书上第五、六章对程序进行优化,主要用了循环分块消除缓存不命中和消除分支预测错误等方法。
这个 Lab 的文档不是太长,8页,不过很老了,文档标题时间:2001 年秋。这 Lab 的历史比我年龄都大了,想想那时候电脑都还没有普及呢。文档中表示程序测试会运行在 Pentium III Xeon Fish 上,想了想十年后我才用上了奔腾 E5300 的双核 CPU,并且它陪伴了我从小学到初中九年之久。
这个 Lab 搭环境又遇到了大坑,由于网上参考资料还不是很多(很多人选择跳过这个 Lab,毕竟已经被 CMU 取代了),我尝试探索了很久最终还是自己成功弄好了。
首先解压文件:
mkdir perf
tar -xvf perflab-handout.tar -C perf/
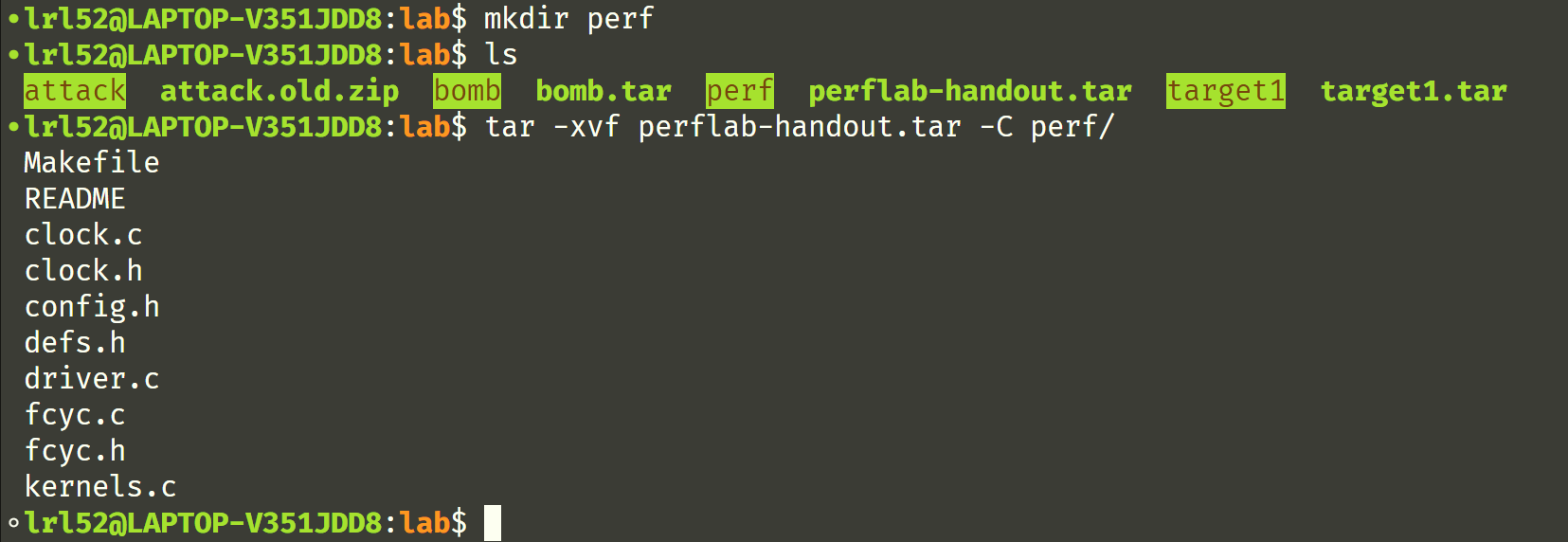
然后根据 Lab 上的介绍以及 MakeFile 文件里的规则,需要我们先手动编译几个 *.c 的代码生成 *.o 的目标文件(OBJ)。编译 make 发现不成功,
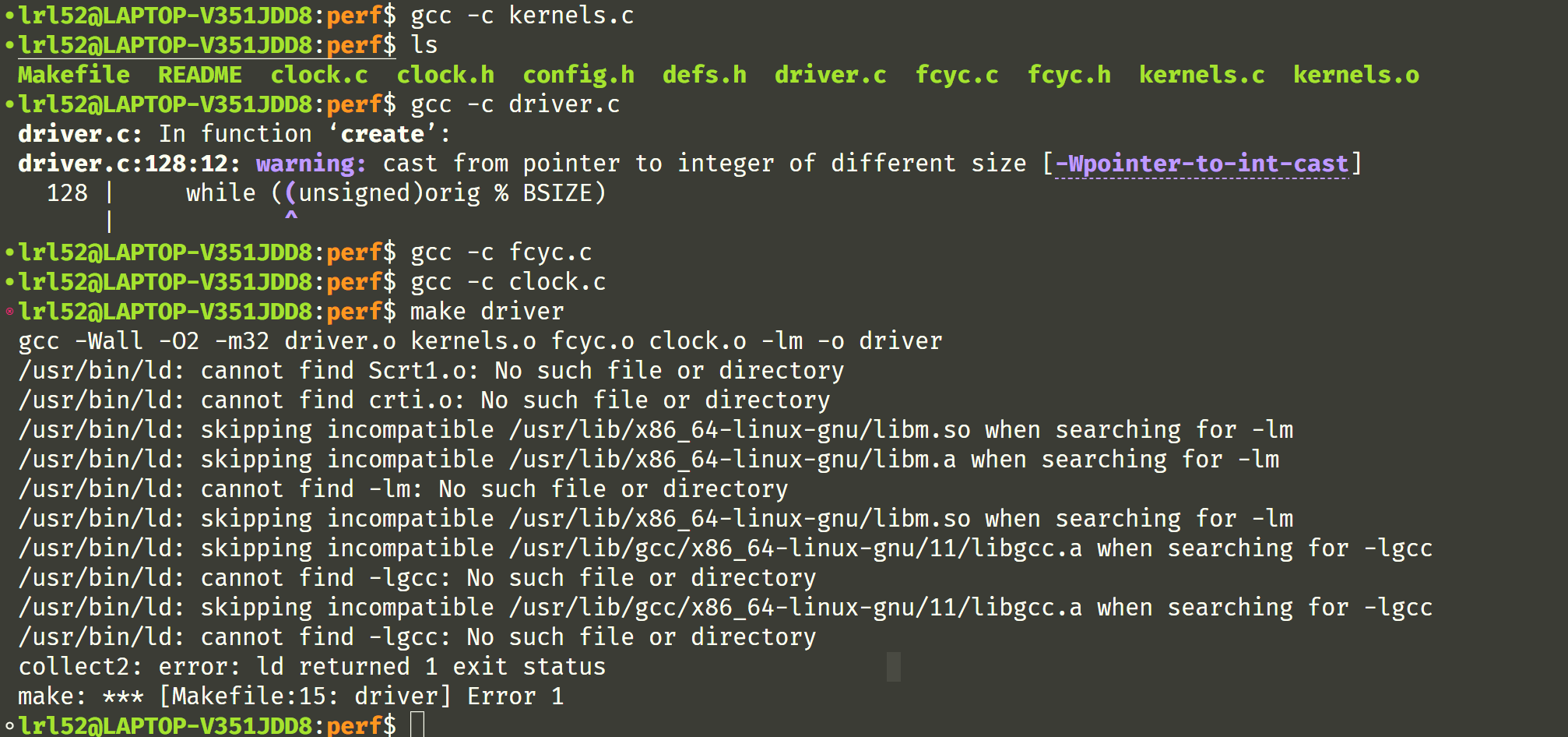
关于上图里面的问题我尝试过 Google,在 StackOverflow 上也有一些关于 /usr/bin/ld: cannot find xxx 错误的回答,传送门。
大致解决方案就是没装库的装库,装了库也找不到就尝试添加软链接。我观察到我这里是 -lm 出了问题,-lm 是链接 math 库,这是 C 自带的标准库,怎么会出问题呢?我还尝试写了一份用到 math 库的 C 代码,编译也没问题。我又把文件搬到服务器上也试过了,还是无法编译成功。
这时我点开了 Release Note ,

看到了 -m32 的含义,于是尝试把里面的 -m32 换成 -m64,
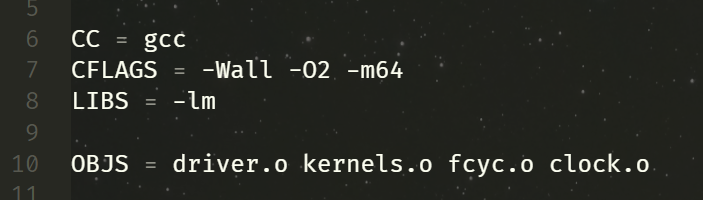
现在报错长下面这样了,根据经验,这应该是 C 代码的问题了,也就是有函数未定义
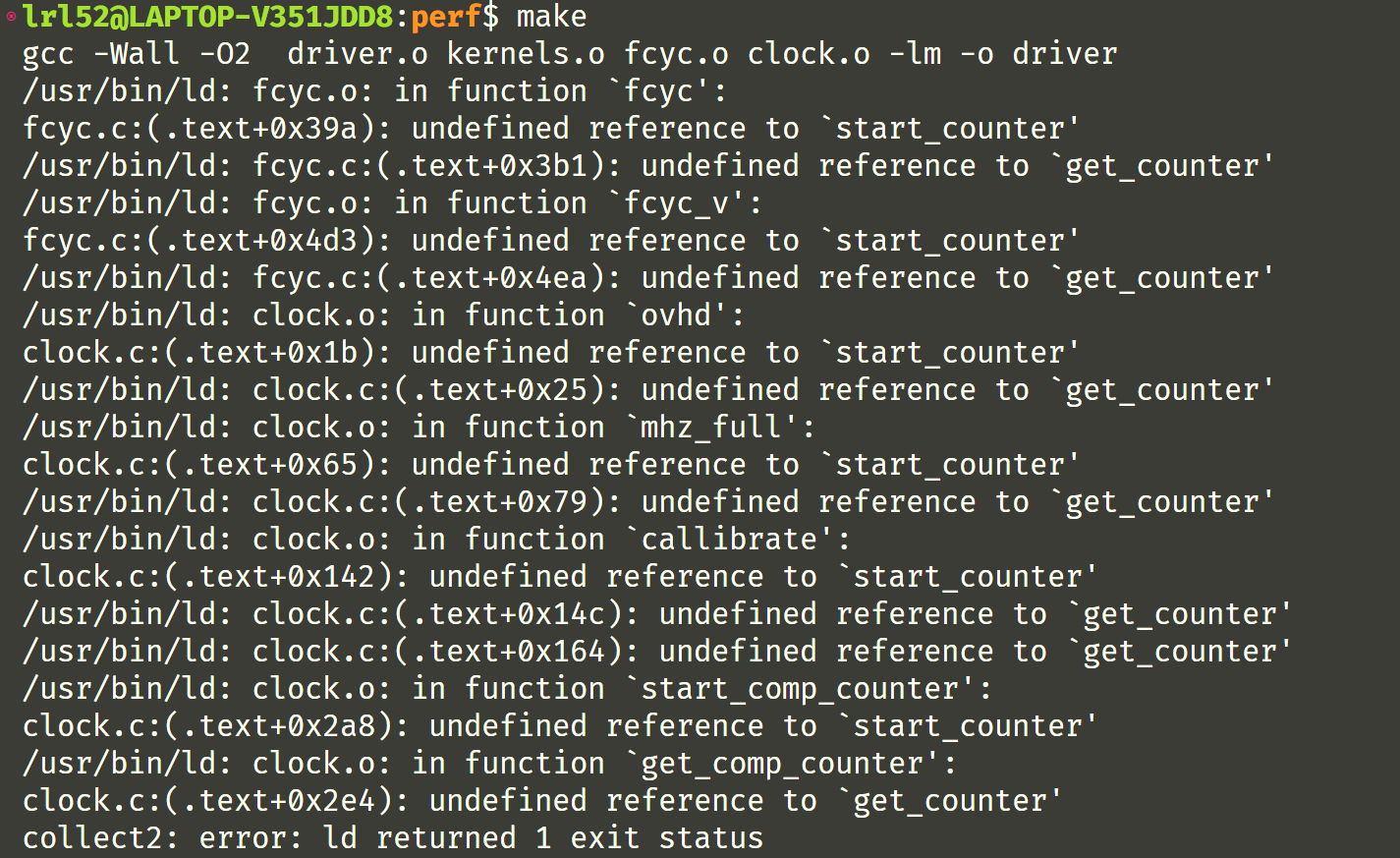
问题出现在 fcyc.c 代码里。确实,在 VScode 里还真找不到函数的实现。查了查好像也不是库函数已经实现了的,网上的博客也找不到编译不过的相关介绍。
在 clock.c 里面,我找到了原因所在:宏定义 __alpha 和 __i386__ 都不满足,导致本来有的 start_counter 和 get_counter 函数没有编译。
手动改一下,
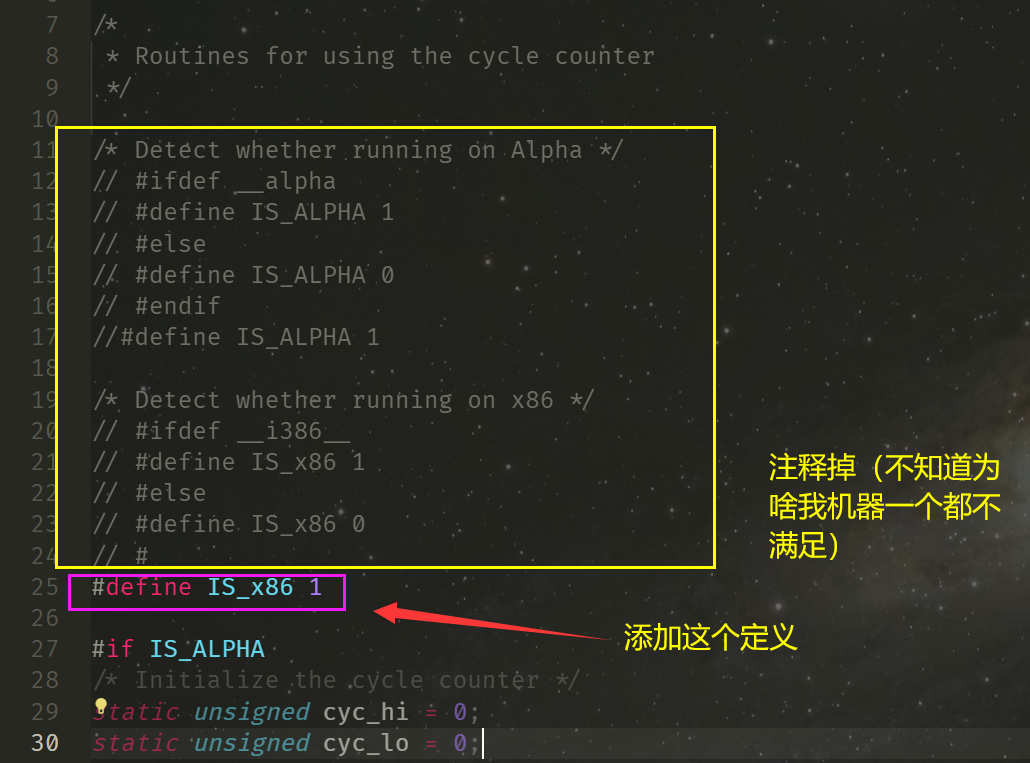
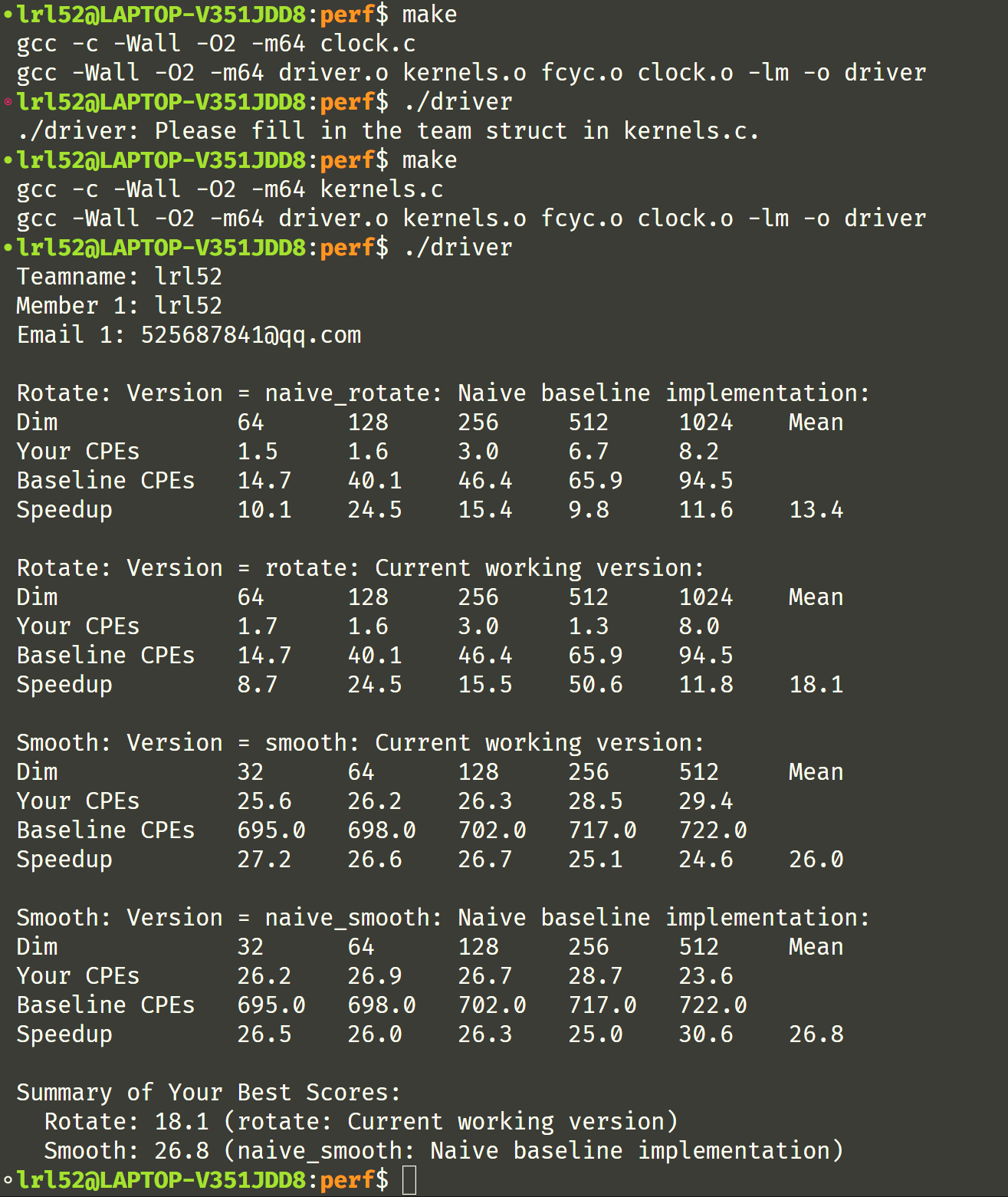
好好好,终于成功让代码跑起来了:
这里需要补充一下 team 信息才能运行,
下面是我修改后的 MakeFile ,添加了手动编译 *.o 的过程,-m32 被替换成了 -m64:
# Student's Makefile for the CS:APP Performance Lab
TEAM = bovik
VERSION = 1
HANDINDIR =
CC = gcc
CFLAGS = -Wall -O2 -m64
LIBS = -lm
OBJS = driver.o kernels.o fcyc.o clock.o
all: driver
driver.o: driver.c
$(CC) -c $(CFLAGS) driver.c
kernels.o: kernels.c
$(CC) -c $(CFLAGS) kernels.c
fcyc.o: fcyc.c
$(CC) -c $(CFLAGS) fcyc.c
clock.o: clock.c
$(CC) -c $(CFLAGS) clock.c
driver: $(OBJS) fcyc.h clock.h defs.h config.h
$(CC) $(CFLAGS) $(OBJS) $(LIBS) -o driver
handin:
cp kernels.c $(HANDINDIR)/$(TEAM)-$(VERSION)-kernels.c
clean:
-rm -f $(OBJS) driver core *~ *.o
rotate 和 smooth 函数优化
由于实验和硬件强相关,先给出笔者的实验环境:
- OS:Ubuntu-22.04
- CPU:AMD Ryzen 7 5800H
下面进入实验正题,由于我做实验的时候是改 smooth 函数的时候又想起去改了 rotate 函数,两者没有严格的先后之分,这里就把两个过程合一起了。下面是文档里的截图,
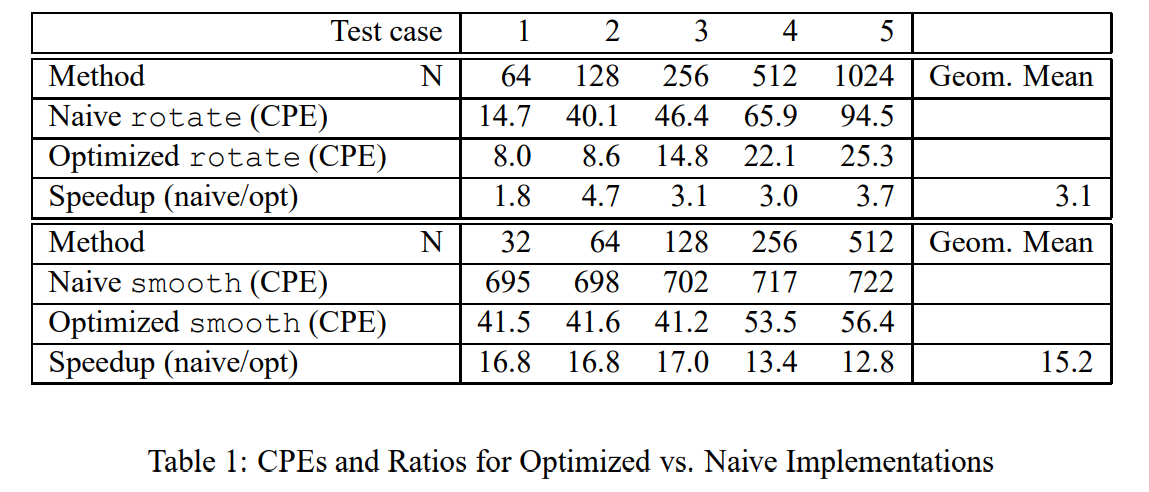
哈哈,其实什么优化不做,该代码在现代计算机上的 CPE 和分数已经吊打当时优化后的结果了?(通过上面实验介绍里的截图可以看出)
首先是 rotate,改成 8x8 的分块矩阵优化,据说这样效果最好
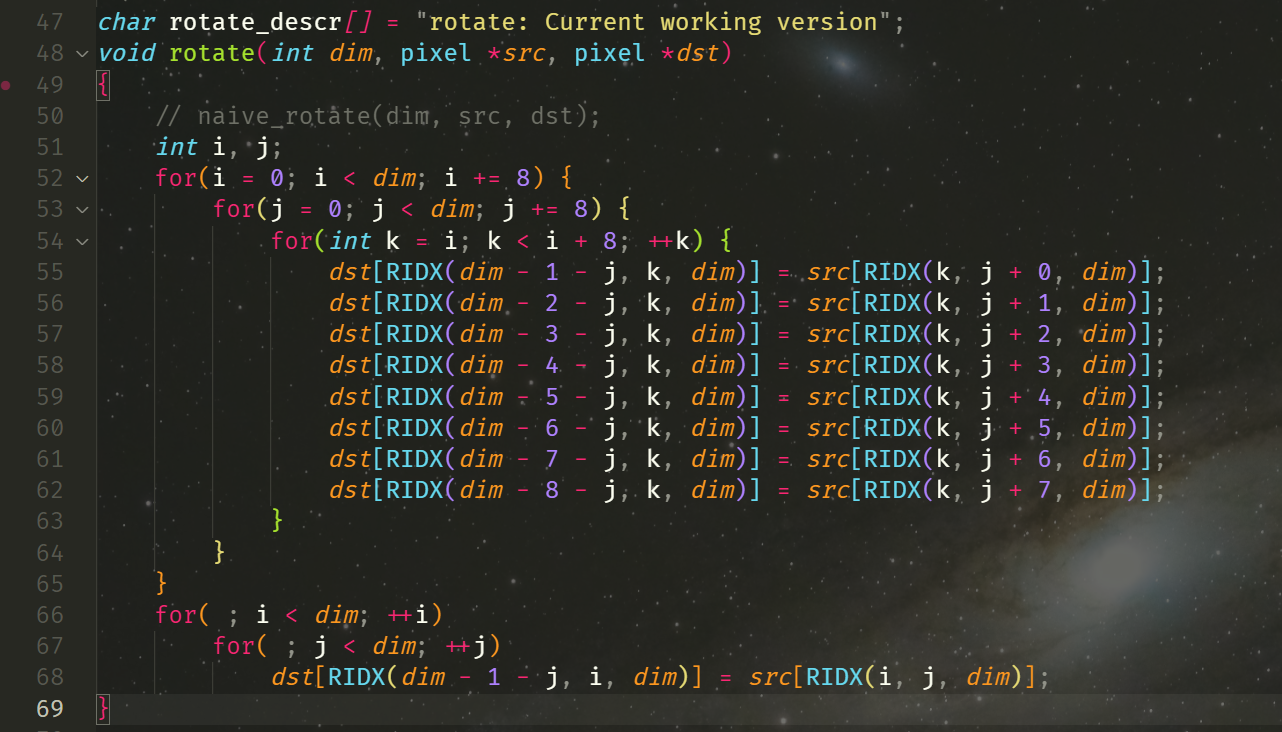
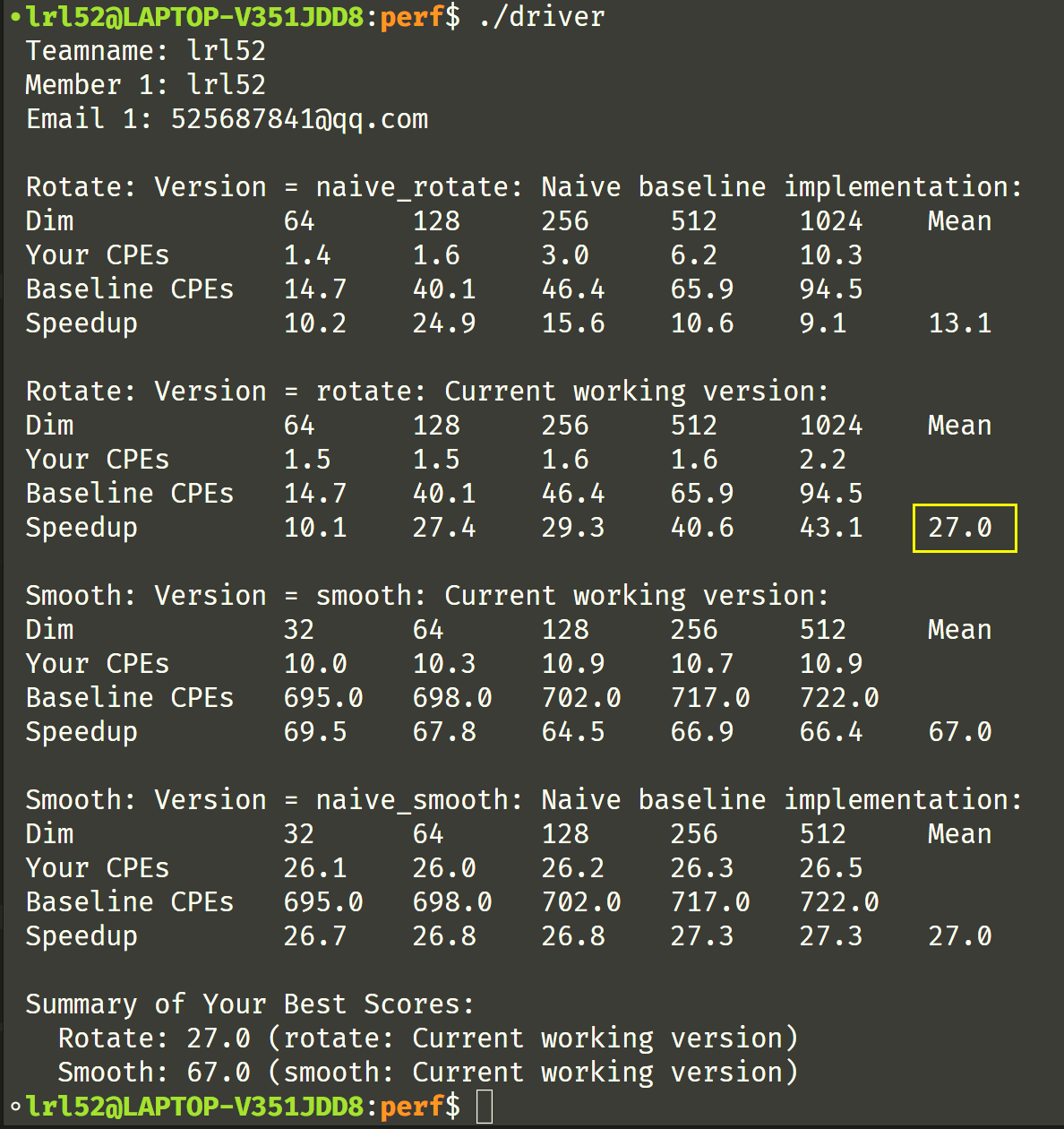
我们得到了 26.6 分的好成绩。哈哈,smooth 什么优化都没有加却拿到了 35.2 的分数了?(上个截图是 26.8 来着)
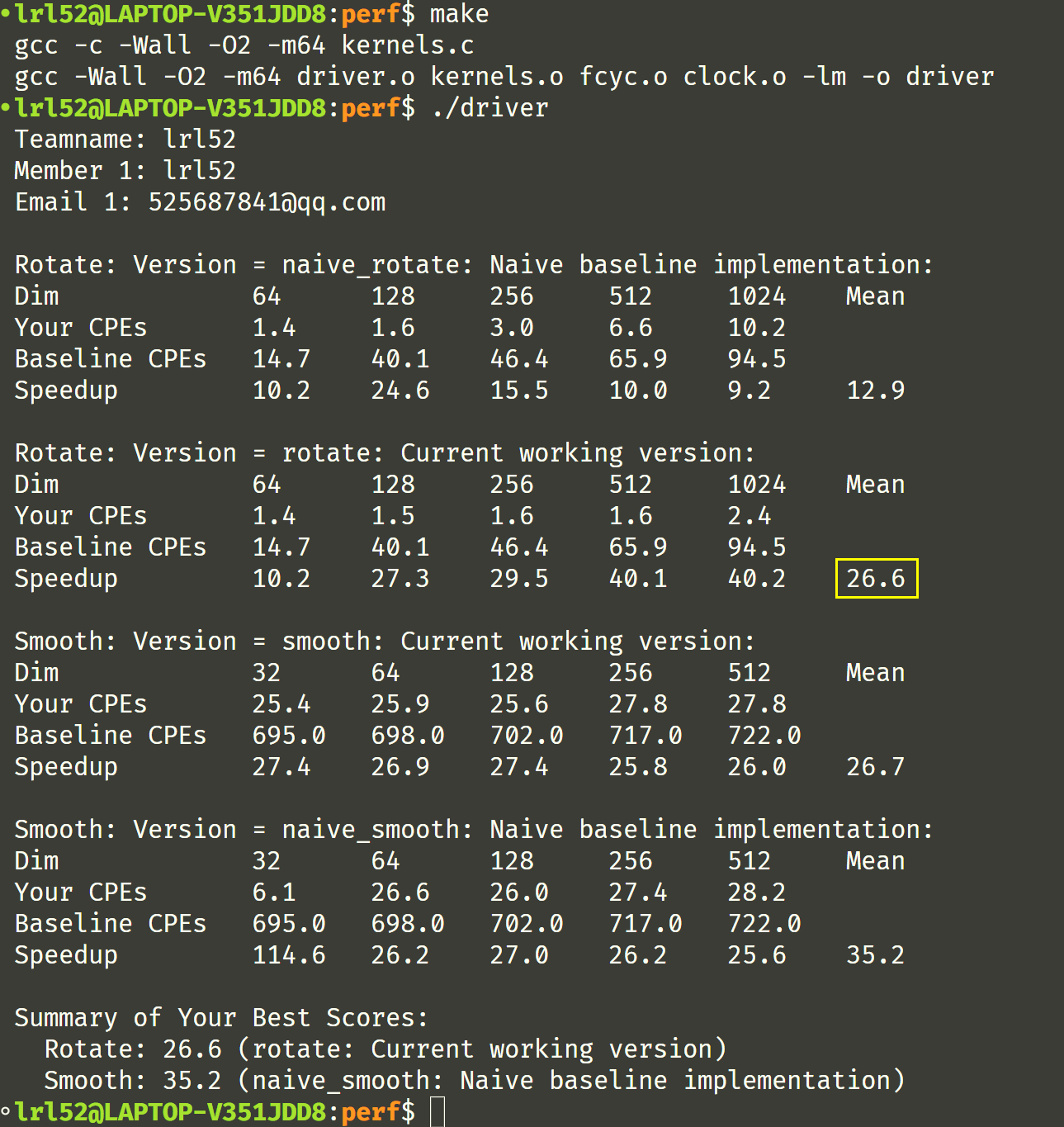
接着试了试知乎上的 smooth 代码,知乎参考代码的分数是 66.0
smooth 代码明显的性能缺陷是:
- 循环低效率。遍历过程中,对每一个点都调用了
min函数 - 没有利用循环展开
思路:先对四角、四边单独处理,然后再对内部进行循环处理,这样就能避免调用 min 和 max 函数
这么实现后跑分见下面第二张图。
小插曲:写 smooth 的时候,突然发现前面的循环展开有误,由于测试的数据都是 8 的倍数,代码肯定能正确运行,但循环展开却没有处理 8 的余数部分。因为文档里要求了,即使 N 不是那几组数据,正确性是必要的:

哦,写文档的时候才发现 N 一定是 32 的倍数,不过我在实验处理的时候认为 N 可以是任意值。
(试了试注释代码,发现如果程序错了它还是能检测出来的)
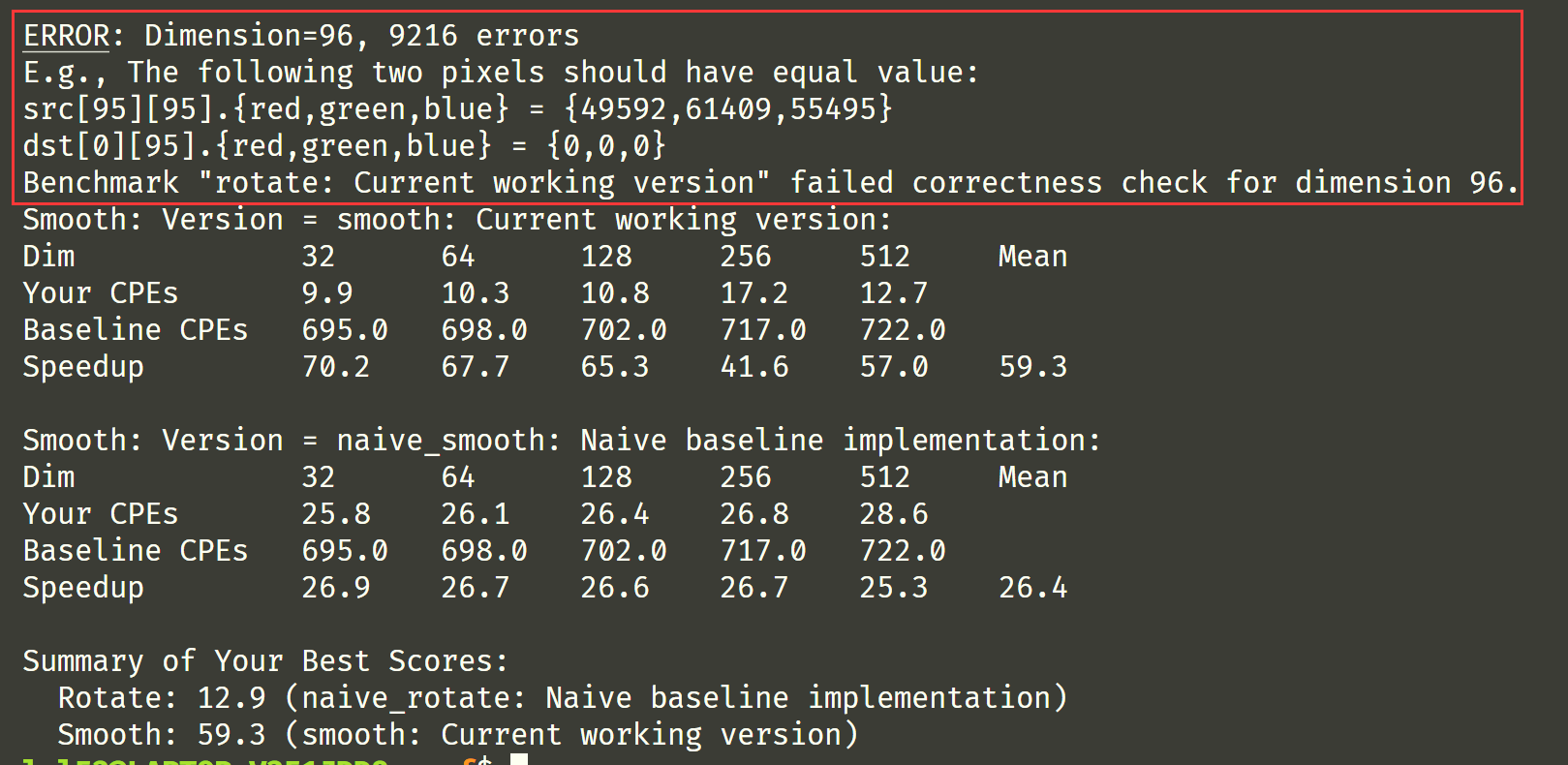
更改后的循环展开代码后跑分如下:
rotate 的代码如下:
/*
* rotate - Your current working version of rotate
* IMPORTANT: This is the version you will be graded on
*/
char rotate_descr[] = "rotate: Current working version";
void rotate(int dim, pixel *src, pixel *dst)
{
// naive_rotate(dim, src, dst);
const int limit_dim = dim - 7;
register int i, j, k; //但愿寄存器够
for(i = 0; i < limit_dim; i += 8) {
for(j = 0; j < limit_dim; j += 8) {
for(k = i; k < i + 8; ++k) {
dst[RIDX(dim - 1 - j, k, dim)] = src[RIDX(k, j + 0, dim)]; //循环展开j(i, j都展开有64种可能,这里仅仅展开j)
dst[RIDX(dim - 2 - j, k, dim)] = src[RIDX(k, j + 1, dim)];
dst[RIDX(dim - 3 - j, k, dim)] = src[RIDX(k, j + 2, dim)];
dst[RIDX(dim - 4 - j, k, dim)] = src[RIDX(k, j + 3, dim)];
dst[RIDX(dim - 5 - j, k, dim)] = src[RIDX(k, j + 4, dim)];
dst[RIDX(dim - 6 - j, k, dim)] = src[RIDX(k, j + 5, dim)];
dst[RIDX(dim - 7 - j, k, dim)] = src[RIDX(k, j + 6, dim)];
dst[RIDX(dim - 8 - j, k, dim)] = src[RIDX(k, j + 7, dim)];
}
}
for( ; j < dim; ++j) {
dst[RIDX(dim - 1 - j, i + 0, dim)] = src[RIDX(i + 0, j, dim)]; //循环展开i(j无法展开了就换i来展开)
dst[RIDX(dim - 1 - j, i + 1, dim)] = src[RIDX(i + 1, j, dim)];
dst[RIDX(dim - 1 - j, i + 2, dim)] = src[RIDX(i + 2, j, dim)];
dst[RIDX(dim - 1 - j, i + 3, dim)] = src[RIDX(i + 3, j, dim)];
dst[RIDX(dim - 1 - j, i + 4, dim)] = src[RIDX(i + 4, j, dim)];
dst[RIDX(dim - 1 - j, i + 5, dim)] = src[RIDX(i + 5, j, dim)];
dst[RIDX(dim - 1 - j, i + 6, dim)] = src[RIDX(i + 6, j, dim)];
dst[RIDX(dim - 1 - j, i + 7, dim)] = src[RIDX(i + 7, j, dim)];
}
}
for( ; i < dim; ++i) {
for(j = 0; j < limit_dim; j += 8) {
dst[RIDX(dim - 1 - j, i, dim)] = src[RIDX(i, j + 0, dim)]; //循环展开j
dst[RIDX(dim - 2 - j, i, dim)] = src[RIDX(i, j + 1, dim)];
dst[RIDX(dim - 3 - j, i, dim)] = src[RIDX(i, j + 2, dim)];
dst[RIDX(dim - 4 - j, i, dim)] = src[RIDX(i, j + 3, dim)];
dst[RIDX(dim - 5 - j, i, dim)] = src[RIDX(i, j + 4, dim)];
dst[RIDX(dim - 6 - j, i, dim)] = src[RIDX(i, j + 5, dim)];
dst[RIDX(dim - 7 - j, i, dim)] = src[RIDX(i, j + 6, dim)];
dst[RIDX(dim - 8 - j, i, dim)] = src[RIDX(i, j + 7, dim)];
}
for( ; j < dim; ++j)
dst[RIDX(dim - 1 - j, i, dim)] = src[RIDX(i, j, dim)];
}
}
对于 smooth,受循环展开启发,try to use 4x1 loop unrolling
然而结果是明显变糟了,看来对循环展开使用条件还是比较苛刻的,上面循环体都是函数调用的情况下使用会让性能变得更差,

受到该启发,尝试把循环拆分一下:

分数几乎没有变化,

smooth 的代码如下,
static inline void set_corner(int cc, pixel *src, pixel *dst, int a1, int a2, int a3){
dst[cc].blue = (src[cc].blue+src[a1].blue+src[a2].blue+src[a3].blue) >> 2;
dst[cc].green = (src[cc].green+src[a1].green+src[a2].green+src[a3].green) >> 2;
dst[cc].red = (src[cc].red+src[a1].red+src[a2].red+src[a3].red) >> 2;
}
static inline void set_top(int dim, pixel *src, pixel *dst, int j){
dst[j].blue = (src[j].blue+src[j+dim].blue+src[j-1].blue+src[j+1].blue+src[j+dim-1].blue+src[j+dim+1].blue)/6;
dst[j].green = (src[j].green+src[j+dim].green+src[j-1].green+src[j+1].green+src[j+dim-1].green+src[j+dim+1].green)/6;
dst[j].red = (src[j].red+src[j+dim].red+src[j-1].red+src[j+1].red+src[j+dim-1].red+src[j+dim+1].red)/6;
}
static inline void set_bottom(int dim, pixel *src, pixel *dst, int j){
dst[j].blue = (src[j].blue+src[j-dim].blue+src[j-1].blue+src[j+1].blue+src[j-dim-1].blue+src[j-dim+1].blue)/6;
dst[j].green = (src[j].green+src[j-dim].green+src[j-1].green+src[j+1].green+src[j-dim-1].green+src[j-dim+1].green)/6;
dst[j].red = (src[j].red+src[j-dim].red+src[j-1].red+src[j+1].red+src[j-dim-1].red+src[j-dim+1].red)/6;
}
static inline void set_left(int dim, pixel *src, pixel *dst, int i){
dst[i].blue = (src[i].blue+src[i-dim].blue+src[i-dim+1].blue+src[i+1].blue+src[i+dim].blue+src[i+dim+1].blue)/6;
dst[i].green = (src[i].green+src[i-dim].green+src[i-dim+1].green+src[i+1].green+src[i+dim].green+src[i+dim+1].green)/6;
dst[i].red = (src[i].red+src[i-dim].red+src[i-dim+1].red+src[i+1].red+src[i+dim].red+src[i+dim+1].red)/6;
}
static inline void set_right(int dim, pixel *src, pixel *dst, int i){
dst[i].blue = (src[i].blue+src[i-dim].blue+src[i-dim-1].blue+src[i-1].blue+src[i+dim].blue+src[i+dim-1].blue)/6;
dst[i].green = (src[i].green+src[i-dim].green+src[i-dim-1].green+src[i-1].green+src[i+dim].green+src[i+dim-1].green)/6;
dst[i].red = (src[i].red+src[i-dim].red+src[i-dim-1].red+src[i-1].red+src[i+dim].red+src[i+dim-1].red)/6;
}
static inline void set_in(int dim, pixel *src, pixel *dst, int k){
dst[k].blue = (src[k].blue+src[k-1].blue+src[k+1].blue+src[k+dim-1].blue+src[k+dim].blue+src[k+dim+1].blue+src[k-dim-1].blue+src[k-dim].blue+src[k-dim+1].blue)/9;
dst[k].green = (src[k].green+src[k-1].green+src[k+1].green+src[k+dim-1].green+src[k+dim].green+src[k+dim+1].green+src[k-dim-1].green+src[k-dim].green+src[k-dim+1].green)/9;
dst[k].red = (src[k].red+src[k-1].red+src[k+1].red+src[k+dim-1].red+src[k+dim].red+src[k+dim+1].red+src[k-dim-1].red+src[k-dim].red+src[k-dim+1].red)/9;
}
/*
* smooth - Your current working version of smooth.
* IMPORTANT: This is the version you will be graded on
*/
char smooth_descr[] = "smooth: Current working version";
void smooth(int dim, pixel *src, pixel *dst)
{
// naive_smooth(dim, src, dst);
// 处理四个角
set_corner(0, src, dst, 1, dim, dim + 1);
set_corner(dim - 1, src, dst, dim - 2, dim + dim - 2, dim + dim - 1);
set_corner(RIDX(dim - 1, 0, dim), src, dst, RIDX(dim - 1, 1, dim), RIDX(dim - 2, 0, dim), RIDX(dim - 2, 1, dim));
set_corner(RIDX(dim - 1, dim-1, dim), src, dst, RIDX(dim - 1, dim - 2, dim), RIDX(dim - 2, dim - 2, dim), RIDX(dim - 2, dim - 1, dim));
// 处理四个边
for(register int j = 1; j < dim - 1; ++j){
set_top(dim, src, dst, j);
}
for(register int j = 1; j < dim - 1; ++j){
set_bottom(dim, src, dst, dim * dim - dim + j);
}
for(register int j = 1; j < dim - 1; ++j){
set_left(dim, src, dst, j * dim);
}
for(register int j = 1; j < dim - 1; ++j){
set_right(dim, src, dst, j * dim + dim - 1);
}
// 中间部分
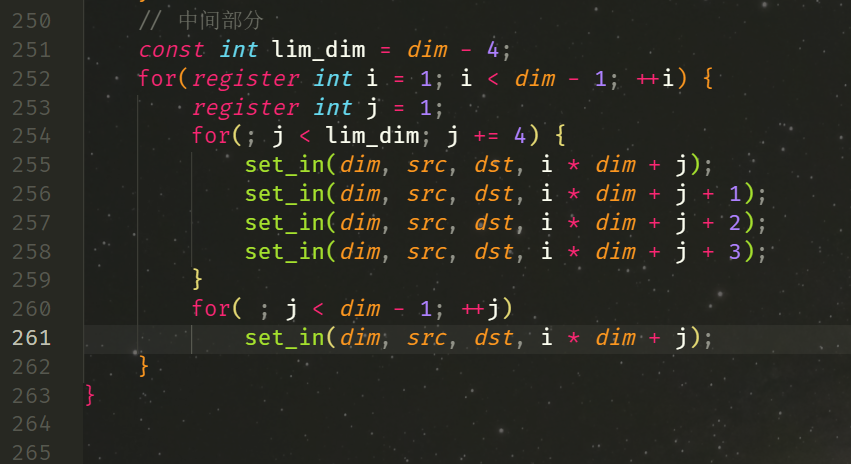
for(register int i = 1; i < dim - 1; ++i) {
for(register int j = 1; j < dim - 1; ++j) {
set_in(dim, src, dst, i * dim + j);
}
}
}
截到的一张比较高的分的图吧:
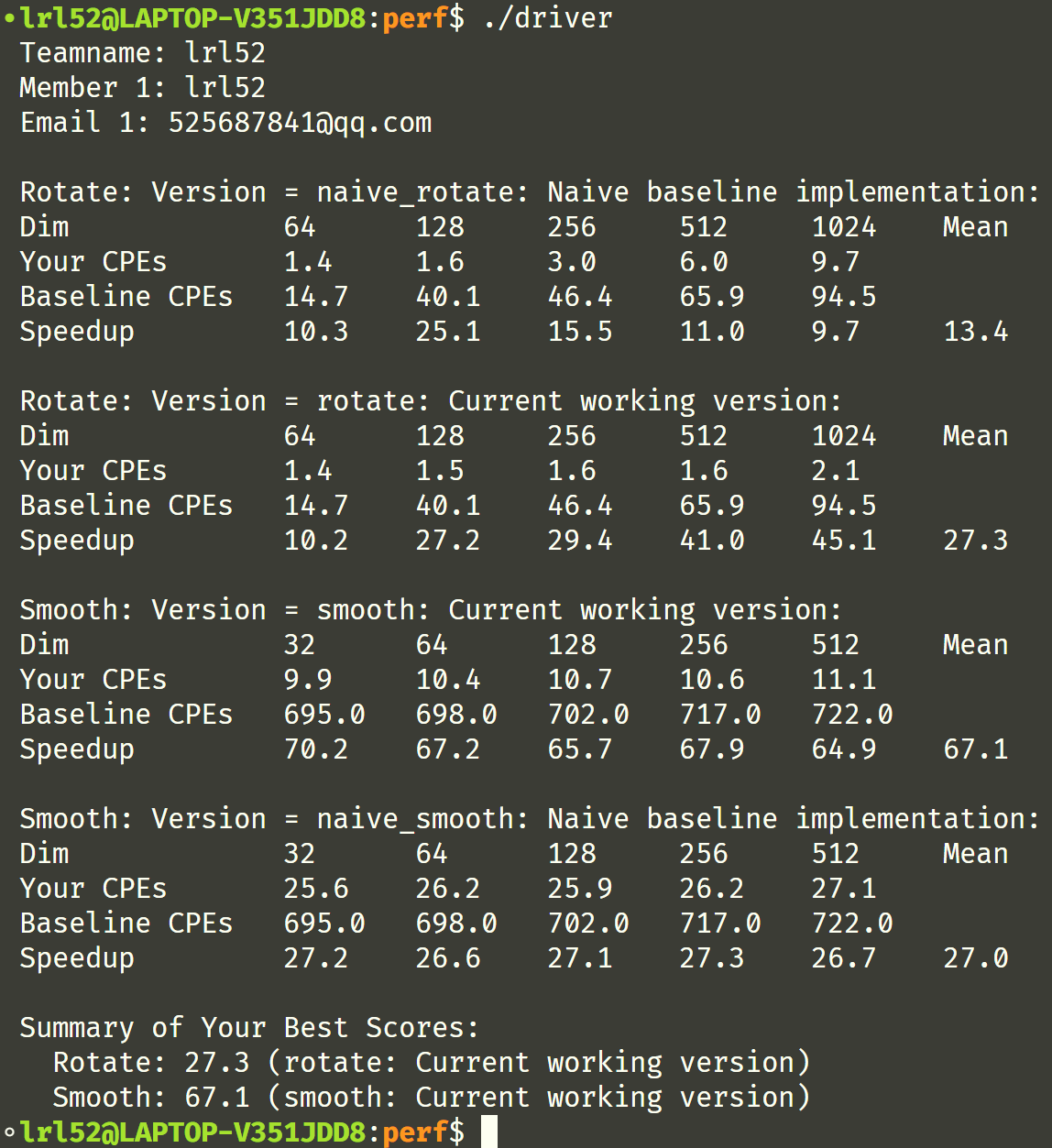
总结
- 这个 Lab 设计得就很粗糙了,多次运行同一个程序也会得到不同的跑分结果。年久失更,远古的 C 代码兼容现在的机器可能也会出问题,我通过修改宏定义才让程序能编译运行
- 这个实验也没法体会到
cache究竟是怎么工作的,我作为programmer也不知道cache命中了多少,所以实验有点玄学。这个实验就当洒洒水啦,希望能在下一个实验Cache Lab中有所收获!
