Pond
背景与动机
许多公共云客户以虚拟机 (VM) 的形式部署工作负载,获得虚拟化计算的性能接近专用云的性能。这给公共云提供商带来了一个重大挑战:以具有竞争力的硬件成本为 opaque VMs(即提供商不知道也不应该检查虚拟机内运行的内容)实现卓越的性能。
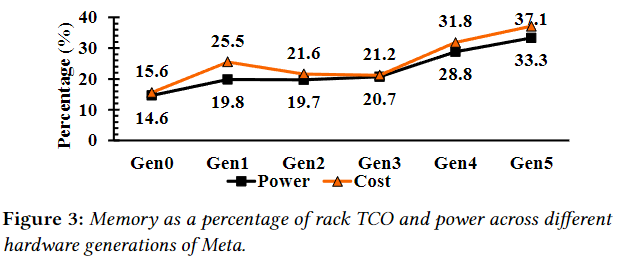
与此同时,DRAM 已成为硬件成本的主要部分,甚至可以占到服务器成本的 50%。
通过对 Azure 生产跟踪的分析,我们发现内存搁浅(memory stranding)是内存浪费的主要来源,也是节省大量成本的潜在来源。(memory stranding:当服务器的所有核心都被租用,即分配给客户虚拟机。但未分配的内存容量仍然存在且无法租用时,就会发生 memory stranding)
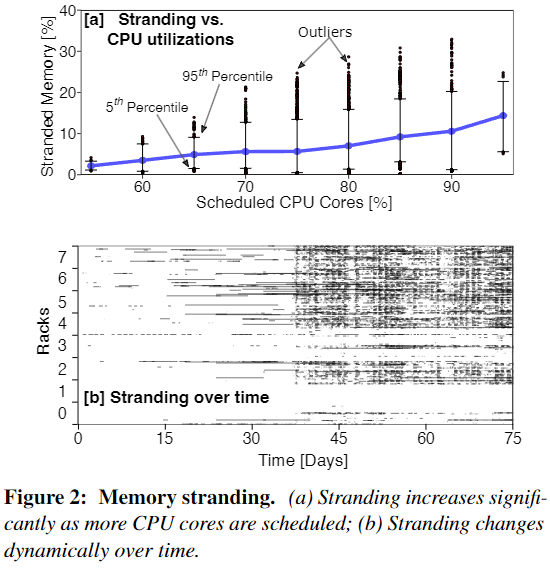
下图 2a 显示了随着 CPU 被核心被调度的比率增大,内存搁浅率也随之上升。2b 显示了随着工作时间增加,机架(rack)的搁浅情况也随越来越多,并且搁浅会影响周围的机架。
解决内存搁浅问题的有效手段是构建分离式共享内存池(pooling memory via memory disaggregation),为服务器和处理器按需动态分配内存,而不是以计算和内存资源紧耦合的方式在每个服务器中预先配置足量内存。通过在不同时间动态地将内存重新分配给不同的主机,我们可以将内存资源转移到需要的地方,而不是悲观地依赖于为所有情况配置每个单独的服务器。(除此之外,论文中提到还有 oversubscribing、process-level memory compression 两种解决方案)
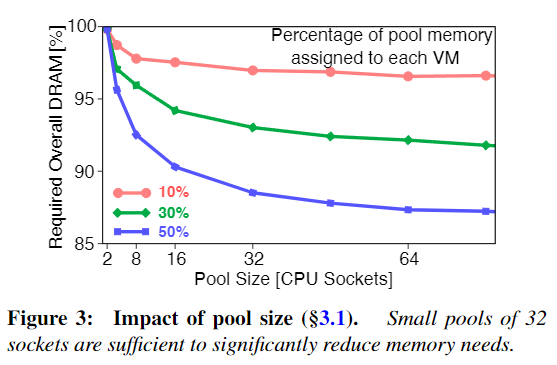
下图 3 显示了当虚拟机把自己的 DRAM 分别以 10%, 30% 和 50% 分配给内存池时,随着 Pool Size[CPU Sockets] 的增大,需要总的 DRAM 量的减少。
为了描述 CXL 延迟对 Azure 数据中心典型工作负载的性能影响,作者在两种模拟 CXL 访问延迟场景下评估了 158 个工作负载:内存增加 182% 和 222%。并且作者将工作负载性能与 NUMA 本地内存进行比较。得到的结果如下图:
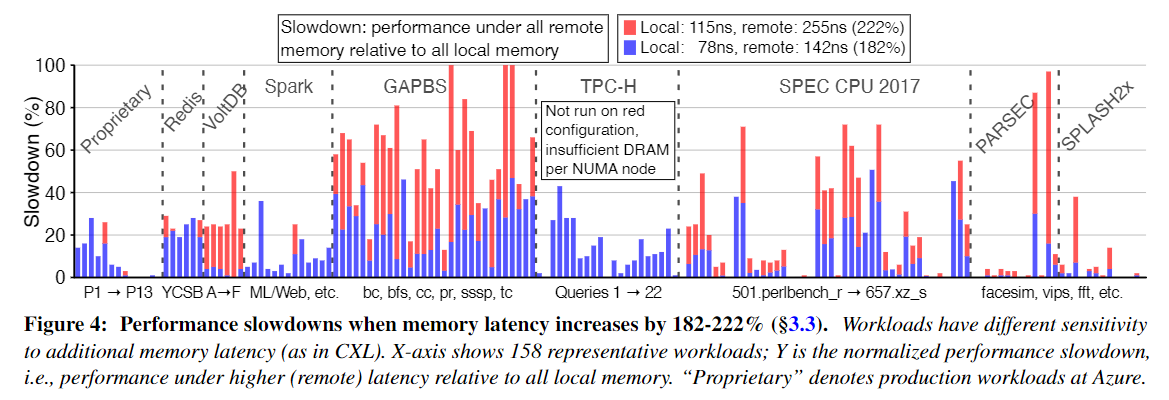
在内存延迟增加 182% 的情况下,我们发现 158 个工作负载中有 26% 在 CXL 下经历了不到 1% 的减速。另外 17% 的工作负载下降幅度不到 5%。与此同时,一些工作负载受到严重影响,其中 21% 的工作负载面临超过 25% 的减速。并且每个工作负载类别内的差异性通常远高于工作负载类别之间的差异性。总体而言,每个工作负载类别至少有一个工作负载的速度减慢小于 5%,以及一个工作负载的速度减慢超过 25%(SPLASH2x 除外)。这些数据为作者后面构建 Pond 合理分配内存类型奠定了基础。
Pond 系统设计
作者为 Pond 的构建提出了 4 个宏伟目标:
- G1:性能与 NUMA-local DRAM 相当
- G2:与虚拟化加速器兼容
- G3:与 opaque VMs 和 unchanged guest OSes/applications 兼容
- G4:宿主机资源开销小
为实现以上目标,Pond的系统架构如下图所示,解决思路概述如下:
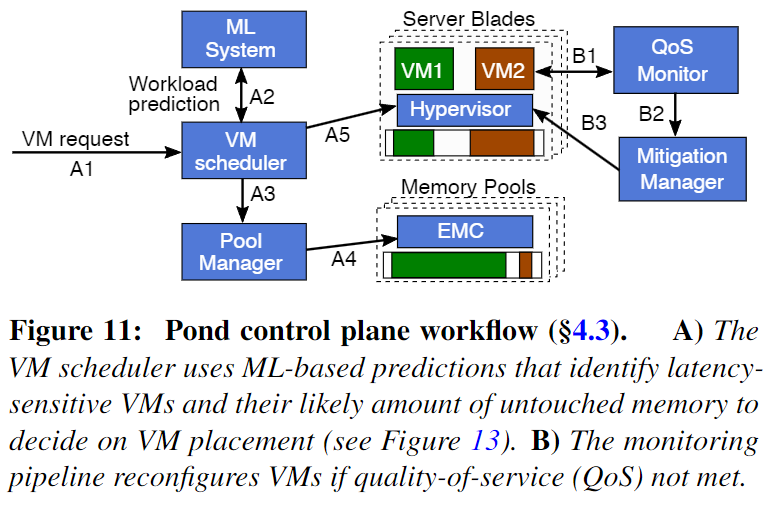
设计智能的混合内存分配策略,在满足虚拟机性能约束的同时减少服务器内存搁浅。首先,定义虚拟机性能目标作为条件约束。具体来说,定义了工作负载的性能下降幅度(PDM,performance degradation margin)和可配置的 VM 尾部百分比(TP,configurable tail-percentage of VMs)。例如,相比于分配本地内存,98% 的虚拟机性能损失不超过 1%。
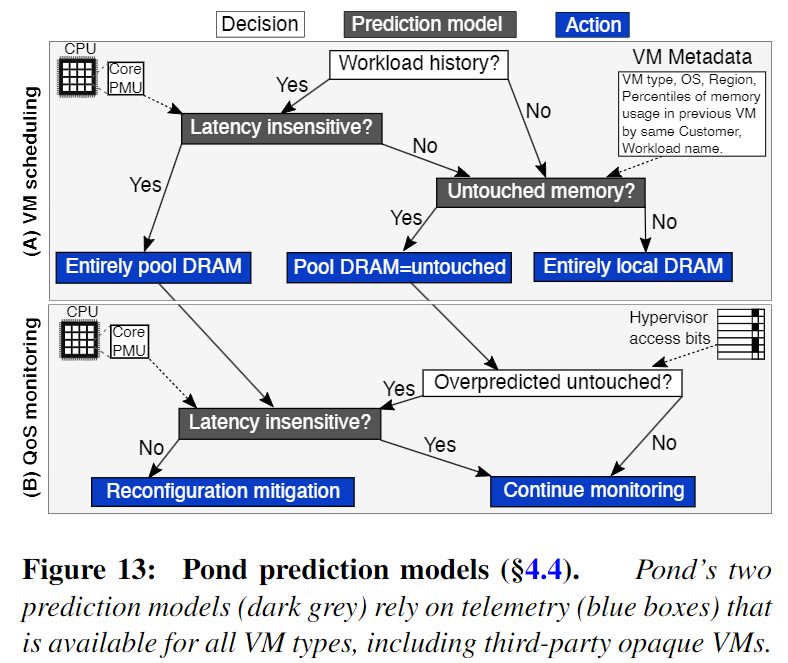
然后,事先预测虚拟机的内存延迟敏感性、未使用内存比例(预测方法见后文介绍),在虚拟机启动时为其完成内存分配。对于内存延迟不敏感的虚拟机,为其全部分配外部 CXL 内存;对于内存延迟敏感的虚拟机,根据预测的内存使用比例分配 NUMA 节点本地内存,为不使用部分分配外部 CXL 内存。

以对虚拟机透明高效的方式完成系统实现。首先,在内存池架构方面,为多个 CPU sockets 配置一个共享的外部 CXL 内存池,并基于 ASIC 实现具有多个 CXL 端口的外部内存控制器(EMC, external memory controller),负责 CPU 与 CXL 内存之间的通信。其次,为了让虚拟机以透明的方式使用 CXL 内存,通过 hypervisor 将分配的外部 CXL 内存以 zero-CPU-core virtual NUMA (zNUMA) 的方式暴露给虚拟机,后者的操作系统会优先分配和使用本地内存,尽可能少使用 zNUMA 内存,避免性能损失。(如果 zNUMA 的大小调整为 untouched meomry 的大小,则它永远不会被使用)。另外,智能内存分配策略需要收集虚拟机特征和监测虚拟机性能,通过利用CPU性能监控单元和修改hypervisor来实现透明的数据收集和性能监测。
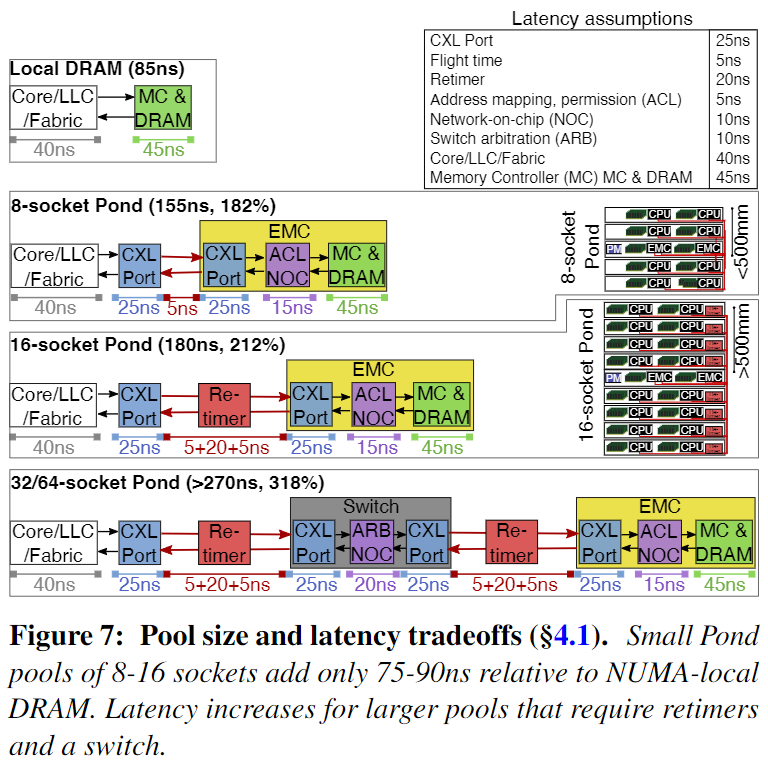
内存池大小与延迟的权衡。CXL 延迟受到传播延迟的影响,但它主要受 CXL 端口延迟以及 CXL 重定时器和 CXL 交换机的使用影响。重定时器是用于在较长距离上保持 CXL/PCIe 信号完整性并在每个方向增加约 10ns 延迟的设备。图 7 详细列出了不同池大小的 Pond 延迟。作者发现 Pond 使用 8 插槽和 16 插槽池将延迟减少了 1/3,相对于 NUMA-local DRAM 仅增加了 70-90 纳秒。在实践中,考虑到延迟和成本开销以及较大池的边际收益递减,作者预计 Pond 将主要部署在小型 8/16 插槽池中。
虚拟机预测模型。Pond 使用基于 ML 的预测模型来决定在调度期间为虚拟机分配多少 CXL 内存。
采用基于决策树的监督学习方法构建虚拟机内存延迟敏感性的预测模型,训练输入的特征为虚拟机运行时 CPU 性能检测计数器采集的相关指标,标签为性能损失值(通过离线测试获得)。Pond 会持续收集虚拟机运行特征,定期重训练预测模型。
虚拟机未使用内存比例的预测依据是,来自于同一个客户的虚拟机很有可能具有类似的行为特征。其预测同样采用监督学习模型,训练输入的特征为虚拟机元数据(如客户 ID、虚拟机类型、及位置),标签为虚拟机在生命周期内未使用内存比例的统计最小值。
另外,Pond 会监测使用 CXL 内存的虚拟机,如果对它们的未使用内存比例的预测过高,需要判断它们是否存在过高的性能损失;如果存在,需要执行虚拟机迁移操作来重配置其内存分配。
TPP
背景和动机
随着数据中心的内存需求激增,加上 DRAM 成本和技术扩展的不断增加,导致内存成为超大规模数据中心的一项重要基础设施开支。伴随着新一代 CPU 和 DRAM 技术的发展,内存正成为机架级功耗和总拥有成本 (TCO) 中更重要的部分。然而,在当今的服务器架构中,内存子系统设计完全依赖于 CPU 中的底层内存技术支持,存在着以下几个限制:
- 内存控制器仅支持单代内存技术(这限制了混合搭配具有不同每 GB 成本、带宽与延迟的技术)
- 存储器的容量颗粒度为 2 的幂,限制了更细粒度的存储容量分配
- 每一代 DRAM 的带宽与容量都是有限的
随着CXL内存的出现, 在主存(本地内存)之外多出来了一种延迟没有增加太多, 但容量巨大的新内存。如何能够用好这部分内存成为了一个重要问题。(与正常 DRAM 访问相比,CXL 增加了大约 50-100 纳秒的额外延迟)
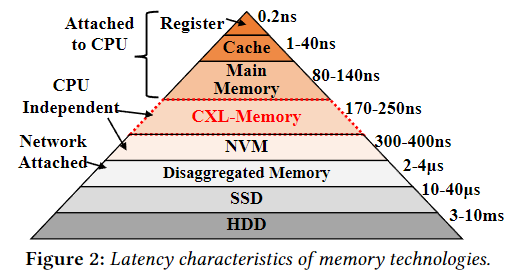
Compute Express Link (CXL)通过提供具有类似 DRAM 带宽和缓存线粒度访问语义的中间延迟操作点来缓解此问题。 CXL 协议允许使用新的内存总线接口将内存连接到 CPU(图 1)。从软件角度来看,CXL-Memory 在系统中表现为一个无 CPU 的 NUMA 节点,其内存特性(例如带宽、容量、代数、技术等)独立于直接连接到 CPU 的内存。然而,Linux 的内存管理机制是为同质 CPU 连接的仅 DRAM 系统设计的,在 CXL-Memory 系统上表现不佳。
为此,作者设计了一种操作系统级透明页面放置机制 – TPP,以有效地将页面放置在分层内存系统中,以便相对热的页面保留在快速内存层中,而冷页面则移动到慢速内存层中。
为了了解现有数据中心应用程序中的各种内存访问行为,即对于每个应用程序,我们想知道在一定时期内有多少内存保持热、暖和冷状态,以及其内存中哪些部分是短期内存,哪些部分是长期内存。
现有的基于空闲页跟踪 (IPT) 的分析工具不符合要求,因为它们需要对内核进行修改,而这在生产中通常是不可能的。此外,连续访问位采样和分析需要过多的 CPU 和内存开销。为此,我们构建了 Chameleon,这是一个强大且轻量级的用户空间工具,它使用现有 CPU 的精确基于事件的采样 (PEBS) 机制来表征应用程序的内存访问行为。
我们使用 Chameleon 来表征在我们的生产服务器群中运行多年的最流行的内存负载应用程序,这些工作负载占服务器群的很大一部分,代表了我们工作负载的广泛多样性。分别是:
- Web:Web 实现了一个虚拟机来服务 Web 请求。Web1 是基于 HipHop 虚拟机(HHVM)的服务,Web2 是基于 Python 的服务。
- Cache:Cache 是位于网络层和数据库层之间的大型分布式内存对象缓存服务,用于低延迟数据检索。
- Data Warehouse:Data Warehouse 是一个统一的计算引擎,用于在计算集群上进行并行数据处理。该服务可管理和协调整个集群中长期复杂批量数据查询的执行。
- Ads:Ads 是检索内存数据和执行机器学习计算的重计算工作负载。
通过分析应用程序的内存使用情况和冷热分布,得到下图和一些结论:
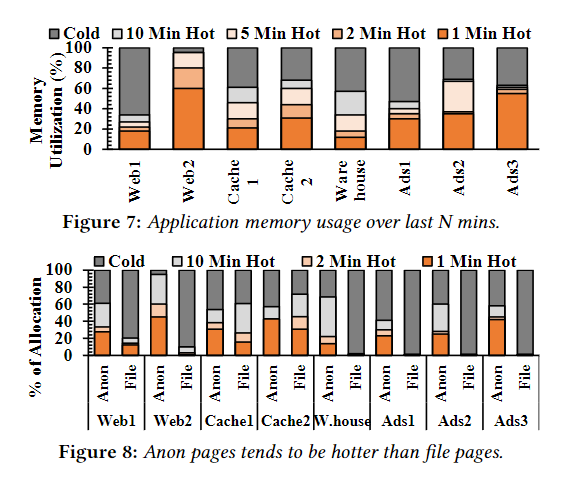
- 数据中心应用程序访问的内存的很大一部分在几分钟内仍处于冷状态。如果页面放置机制可以将这些冷页面移至较低的内存层,则分层内存系统可以非常适合此类冷内存。
- 很大一部分匿名页面是热的,而文件页面在短时间内相对较冷。
- 尽管匿名页和文件页使用情况可能会随着时间的推移而变化,但应用程序大多保持稳定的使用模式。智能页面放置机制在做出放置决策时应该了解页面类型。
- 工作负载对不同页面类型具有不同级别的敏感度,并且随着时间的推移而变化。
TPP 的设计
由于用户空间到内核空间的上下文切换开销、用户空间中的历史管理开销等,作者将 TPP 设计为内核功能,因为我们认为它实现起来更简单,并且比用户空间机制性能更高。
页温度检测:论文中列举了好多种方法, 最后 TPP 选择的是
- 对CXL-Memory 使用 NUMA Balancing,在下次访问的时候触发一次缺页异常。在最常访问的页面上定期发生缺页异常可能会导致较高的开销,为了解决这个问题,我们选择只利用较小的页面的缺页异常作为 CXL-Memory 的温度检测机制。
- 对于本地内存节点的冷页检测,我们发现 Linux 现有的基于 LRU 的管理机制是轻量级的并且非常高效的。
结合 LRU 和 NUMA 平衡,我们可以以几乎零开销检测 CXL-Memory 中的大多数热点页。
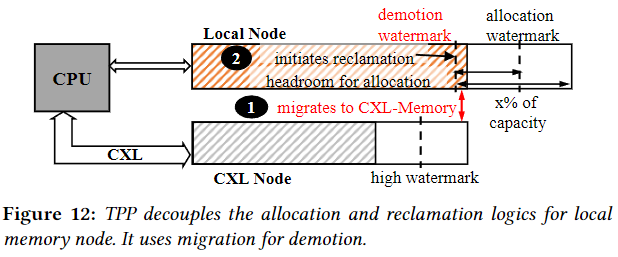
轻量级内存回收迁移(降级到 CXL-Memory):为了对本地节点启用轻量级页面回收,在找到回收候选者后,我们不调用交换机制,而是将它们放入单独的降级列表中,并尝试将它们异步迁移到 CXL 节点。迁移到 NUMA 节点比交换(swap)快几个数量级。使用 Linux 默认的基于 LRU 的机制来选择降级候选者。
内存分配与回收解耦:Linux 为节点内的每个内存区域维护三个 watermarks (min, low, high),如果节点的空闲页面总数低于 low_watermark,Linux 会认为该节点面临内存压力并启动该节点的页面回收。在我们的例子中,TPP 将它们降级为 CXL 节点。对本地节点的新分配将停止,直到回收器释放足够的内存以满足 high_watermark。回收器检索的内存可能很快就会填满以满足分配请求。因此,本地内存分配频繁停止,更多页面最终出现在 CXL 节点中,最终降低应用程序性能。在内存严重受限的多NUMA系统中,我们应该主动维护合理的可用内存量。
为了实现这一点,我们将“回收停止”和“新分配发生”机制的逻辑解耦,在本地内存中额外维护了一部分空闲页。简单地说也就是靠 LRU 多迁移一点内存页到 CXL 内存, 给本地内存多留点了 buffer, 确保未来新的内存页都优先从主存上分配。
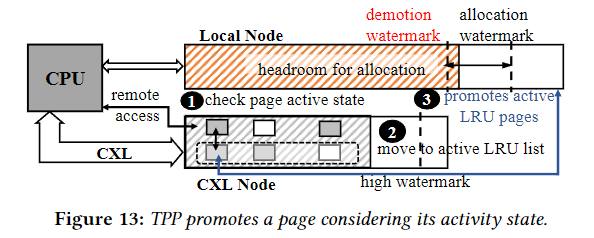
从 CXL 内存中提升内存页:在 CXL 内存中使用 NUMA Balancing 方法。CXL 系统中,将本地节点的热内存提升到其他本地或 CXL 节点是不合理的,因此我们仅将采样限制为 CXL 节点。当 CPU 访问采样页时,当会生成 page fault(称为 NUMA hint fault),默认 NUMA 平衡会立即提升该页面,而不检查其活动状态。这可能导致访问频率很低的页面仍然可以提升到本地节点,从而产生 ping-pong 现象。为了解决这个乒乓问题,我们不是立即提升,而是通过页面在操作系统维护的 LRU 列表中的位置来检查页面的状态,如果故障页面处于非活动 LRU 状态,我们不会立即考虑该页面进行升级,因为它可能是不经常访问的页面。仅当在活动 LRU 链表中找到 faulted page 时,我们才将其视为升级候选页面。
具体来说,每当我们在非活动 LRU 列表中发现故障页面时,我们都会将该页面标记为已访问,并立即将其移至活动 LRU 列表,如果在下一次 NUMA 提示故障期间页面仍然保持热状态,则它将处于活动 LRU 中,并提升到本地节点。
页面类型感知分配:生产应用程序通常在预热阶段执行大量文件 I/O,并生成不经常访问的文件缓存占用本地内存,从而导致匿名页被分配在 CXL 节点上(最终又会被提升回本地内存)。为了解决这些不必要的页面迁移,我们允许应用程序优先向 CXL 节点分配缓存(例如文件缓存、tmpfs 等),同时保留匿名页面的分配策略。启用此分配策略后,在应用程序生命周期的任何点生成的页面缓存将最初分配给 CXL 节点,如果页面缓存变得足够热而被选为升级候选者,那么它最终将被升级为本地节点。此策略有助于不频繁缓存访问的应用程序在具有少量本地内存和大但廉价的 CXL-Memory 的系统上运行,同时保持性能
References
解读 CXL 内存池系统 Pond(ASPLOS’23 杰出论文)
CXL论文分享-TPP(Transparent Page Placement)
(ASPLOS 23)TPP: Transparent Page Placement for CXL-Enabled Tiered-Memory
YouTube – University of Michigan | Transparent Memory Management for CXL-enabled Systems
