Hello, cuda!
CMake 中启用 CUDA 支持
最新版的 CMake(3.18 以上),只需在 LANGUAGES 后面加上 CUDA 即可启用。
然后在 add_executable 里直接加你的 .cu 文件,和 .cpp 一样。
project(hellocuda LANGUAGES CXX CUDA)
CUDA 编译器兼容 C++17
CUDA 的语法,基本完全兼容 C++。包括 C++17 新特性,都可以用。甚至可以把任何一个 C++ 项目的文件后缀名全部改成 .cu,都能编译出来。
笔者目前使用的是 2023 年 1 月发布的 CUDA 12.0.1,可以兼容 C++ 20 的特性
这是 CUDA 的一大好处,CUDA 和 C++ 的关系就像 C++ 和 C 的关系一样,大部分都兼容,因此能很方便地重用 C++ 现有的任何代码库,引用 C++ 头文件等。
host 代码和 device 代码写在同一个文件内,这是 OpenCL 做不到的。
第一个 CUDA 程序
定义函数 kernel,前面加上 __global__ 修饰符,即可让它在 GPU 上执行。
这里的 kernel 函数在 GPU 上执行,称为核函数,用 __global__ 修饰的就是核函数。
❗ 注意:
__global__返回值必须是 void 的
GPU 和 CPU 之间的通信,为了高效,是异步的。也就是 CPU 调用 kernel<<<2, 4>>>() 后,并不会立即在 GPU 上执行完毕,再返回。实际上只是把 kernel 这个任务推送到 GPU 的执行队列上,然后立即返回,并不会等待执行完毕。
因此可以调用 cudaDeviceSynchronize(),让 CPU 陷入等待,等 GPU 完成队列的所有任务后再返回。从而能够在 main 退出前等到 kernel 在 GPU 上执行完。
__global__用于定义核函数,它在 GPU 上执行,从 CPU 端通过三重尖括号语法调用,可以有参数,不可以有返回值。__device__则用于定义设备函数,它在 GPU 上执行,但是从 GPU 上调用的,而且不需要三重尖括号,和普通函数用起来一样,可以有参数,有返回值。__host__则相反,将函数定义在 CPU 上。
即:host 可以调用 global;global 可以调用 device;device 可以调用 device。
从 Kelper 架构开始,
__global__里可以调用另一个__global__,也就是说核函数可以调用另一个核函数,且其三重尖括号里的板块数和线程数可以动态指定,无需先传回到 CPU 再进行调用,这是 CUDA 特有的能力。
CUDA 完全兼容 C++,因此任何函数如果没有指明修饰符,则默认就是 __host__,即 CPU 上的函数。
#include <cstdio>
#include <cuda_runtime.h>
__device__ void say_hello_device() {
std::printf("Hello, world from GPU!\n");
}
__host__ void say_hello_host() {
std::printf("Hello, world from CPU!\n");
}
__global__ void kernel() {
say_hello_device();
}
int main() {
kernel<<<2, 4>>>();
cudaDeviceSynchronize();
say_hello_host();
return 0;
}
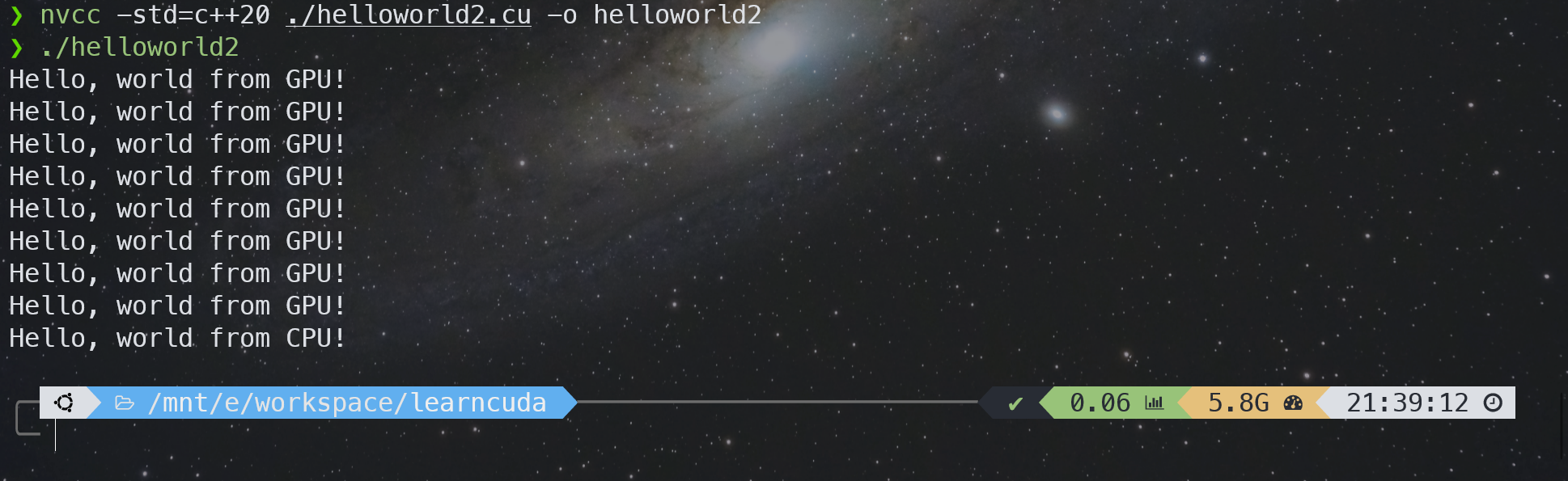
下面来编译和运行第一个 CUDA 程序,和 gcc 差不多,
nvcc -std=c++20 ./helloworld2.cu -o helloworld2
./helloworld2
执行结果如下,
CUDA 内联函数
注意,inline 在现代 C++ 中的效果是声明一个函数为 weak 符号,和性能优化意义上的内联无关。
优化意义上的内联指把函数体直接放到调用者那里去。
因此 CUDA 编译器提供了一个“私货”关键字:__inline__ 来声明一个函数为内联。不论是 CPU 函数还是 GPU 都可以使用,只要你用的 CUDA 编译器。GCC 编译器相应的私货则是 __attribute__(("inline"))。
注意声明为 __inline__ 不一定就保证内联了,如果函数太大编译器可能会放弃内联化。因此 CUDA 还提供 __forceinline__ 这个关键字来强制一个函数为内联。GCC 也有相应的 __attribute__(("always_inline"))。
此外,还有 __noinline__ 来禁止内联优化。
示例代码与下一小节合并一起展示。
让函数在 GPU 和 CPU 上都可以运行
一种方法是通过 __host__ __device__ 这样的双重修饰符,可以把函数同时定义在 CPU 和 GPU 上,这样 CPU 和 GPU 都可以调用。
还有一种方法是借助 constexpr 函数自动变成 CPU 和 GPU 都可以调用。因为 constexpr 通常都是一些可以内联的函数,数学计算表达式之类的,一个个加上太累了,所以产生了这个需求。
不过必须指定 --expt-relaxed-constexpr 这个选项才能用这个特性,我们可以用 CMake 的生成器表达式来实现只对 .cu 文件开启此选项(不然给到 gcc 就出错了)。
target_compile_options(main PUBLIC $<$<COMPILE_LANGUAGE:CUDA>:--expt-relaxed-constexpr>)
当然,constexpr 里没办法调用 printf,也不能用 __syncthreads 之类的 GPU 特有的函数,因此也不能完全替代 __host__ 和 __device__。
示例代码与下一小节合并一起展示。
#ifdef 指令针对 CPU 和 GPU 生成不同的代码
CUDA 编译器具有多段编译的特点。
一段代码它会先送到 CPU 上的编译器(通常是系统自带的编译器比如 gcc 和 msvc)生成 CPU 部分的指令码。然后送到真正的 GPU 编译器生成 GPU 指令码。最后再链接成同一个文件,看起来好像只编译了一次一样,实际上你的代码会被预处理很多次。
它在 GPU 编译模式下会定义 __CUDA_ARCH__ 这个宏,利用 #ifdef 判断该宏是否定义,就可以判断当前是否处于 GPU 模式,从而实现一个函数针对 GPU 和 CPU 生成两份源码级不同的代码。
其实__CUDA_ARCH__ 是个版本号。
其实 __CUDA_ARCH__ 是一个整数,表示当前编译所针对的 GPU 的架构版本号是多少。这里是 520 表示版本号是 5.2.0,最后一位始终是 0 不用管,我们通常简称它的版本号为 52 就行了。
这个版本号是编译时指定的版本,不是运行时检测到的版本。编译器默认就是最老的 52,能兼容所有 GTX900 以上显卡。
关于编译参数选项,具体见 CUDA 官方文档 extended-notation。
关于显卡和版本号的对照表,见 Matching CUDA arch and CUDA gencode for various NVIDIA architectures](https://arnon.dk/matching-sm-architectures-arch-and-gencode-for-various-nvidia-cards/)
#include <cstdio>
#include <cuda_runtime.h>
__host__ __device__ __inline__ void say_hello() {
#ifdef __CUDA_ARCH__
std::printf("Hello, from GPU architecture %d!\n", __CUDA_ARCH__);
#else
std::printf("Hello, from CPU!\n");
#endif
}
__global__ void kernel() {
say_hello();
}
int main() {
kernel<<<2, 4>>>();
cudaDeviceSynchronize();
say_hello();
return 0;
}
CMake 设置架构版本号
可以用 CMAKE_CUDA_ARCHITECTURES 这个变量,设置要针对哪个架构生成 GPU 指令码。
例如小彭老师的显卡是 RTX2080,它的版本号是 75,因此最适合它用的指令码版本是 75。
如果不指定,编译器默认的版本号是 52,它是针对 GTX900 系列显卡的。
不过英伟达的架构版本都是向前兼容的,即版本号为 75 的 RTX2080 也可以运行版本号为 52 的指令码,虽然不够优化,但是至少能用。也就是要求:编译期指定的版本 ≤ 运行时显卡的版本。
CMake 可以同时指定多个版本号,之间用分号分割。运行时可以自动选择最适合当前显卡的版本号,通常用于打包发布的时候。不过这样会导致 GPU 编译器重复编译很多遍,每次针对不同的架构,所以编译会变得非常慢,生成的可执行文件也会变大。
set(CMAKE_CUDA_ARCHITECTURES 52;70;75;86)
线程与板块
GPU 是为并行而生的,可以开启很大数量的线程,用于处理大吞吐量的数据。
刚刚说了 CUDA 的核函数调用时需要用 kernel<<<2, 4>>>() 这种奇怪的语法,这里面的数字代表什么意思呢?具体含义如下:
- 当前线程在板块中的编号:threadIdx
- 当前板块中的线程数量:blockDim
- 当前板块的编号:blockIdx
- 总的板块数量:gridDim
- 线程(thread):并行的最小单位
- 板块(block):包含若干个线程
- 网格(grid):指整个任务,包含若干个板块
- 从属关系:线程<板块<网格
- 调用语法:<<<gridDim, blockDim>>>(<<<板块数量,每个板块中的线程数量>>>)
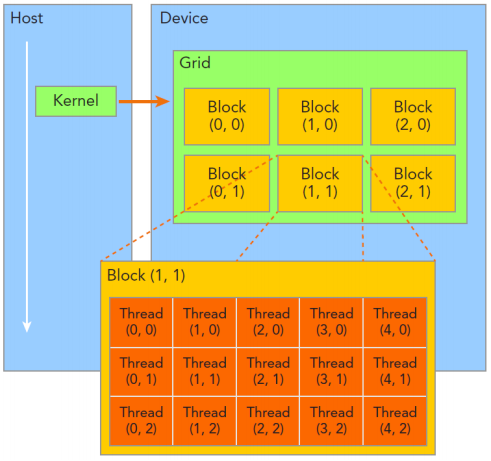
获取板块和线程号

扁平化线程:
__global__ void kernel() {
// std::printf("Block %d of %d, Thread %d of %d\n", blockIdx.x, blockDim.x, threadIdx.x, blockDim.x);
auto tid = blockIdx.x * blockDim.x + threadIdx.x;
auto tnum = gridDim.x * blockDim.x;
std::printf("Flattened Thread %u of %u\n", tid, tnum);
}
三维的板块和线程编号
CUDA 支持三维的板块和线程区间。
只要在三重尖括号内指定的参数改成 dim3 类型即可。dim3 的构造函数就是接受三个无符号整数(unsigned int)非常简单。调用即 dim3(x, y, z)。
这样在核函数里就可以通过 threadIdx.y 获取 y 方向的线程编号,以此类推。
之所以会把 blockDim 和 gridDim 分三维主要是因为 GPU 的业务常常涉及到三维图形学和二维图像,觉得这样很方便,并不一定 GPU 硬件上是三维这样排列的。
#include <cstdio>
#include <cuda_runtime.h>
__global__ void kernel() {
std::printf("Block (%d, %d, %d) of (%d, %d, %d), " \
"Thread (%d, %d, %d) of (%d, %d, %d)\n", \
blockIdx.x, blockIdx.y, blockIdx.z,
gridDim.x, gridDim.y, gridDim.z,
threadIdx.x, threadIdx.y, threadIdx.z,
blockDim.x, blockDim.y, blockDim.z);
}
int main() {
kernel<<<dim3(2, 3, 4), dim3(3, 4, 5)>>>();
cudaDeviceSynchronize();
return 0;
}
分离编译
默认情况下 GPU 函数必须定义在同一个文件里。如果你试图分离声明和定义,调用另一个文件里的 __device__ 或 __global__ 函数,就会出错。
set(CMAKE_CUDA_SEPARABLE_COMPILATION ON)
开启 CMAKE_CUDA_SEPARABLE_COMPILATION 选项(设为 ON),即可启用分离声明和定义的支持。
不过一般情况下还是建议把要相互调用的 __device__ 函数放在同一个文件,这样方便编译器自动内联优化。
内存管理
cudaMalloc 与 cudaMemcpy
GPU 和 CPU 各自使用着独立的内存。CPU 的内存称为主机内存(host)。GPU 使用的内存称为设备内存(device),它是显卡上板载的,速度更快,又称显存。
而不论栈还是 malloc 分配的都是 CPU 上的内存,所以自然是无法被 GPU 访问到。
因此可以用用 cudaMalloc 分配 GPU 上的显存,这样就不出错了,结束时 cudaFree 释放。
❗ 注意到 cudaMalloc 的返回值已经用来表示错误代码,所以返回指针只能通过 &pret 二级指针。
跨 GPU/CPU 地址空间拷贝数据可以用 cudaMemcpy,它能够在 GPU 和 CPU 内存之间拷贝数据。
这里我们希望把 GPU 上的内存数据拷贝到 CPU 内存上,也就是从设备内存(device)到主机内存(host),因此第四个参数指定为 cudaMemcpyDeviceToHost。
同理,还有 cudaMemcpyHostToDevice 和 cudaMemcpyDeviceToDevice。
❗ 注意:cudaMemcpy 会自动进行同步操作,即和 cudaDeviceSynchronize() 等价!因此前面的 cudaDeviceSynchronize() 实际上可以删掉了。
#include <cstdio>
#include <cuda_runtime.h>
__global__ void work(int *ptr) {
*ptr = 52;
}
int main() {
int *ptr{};
cudaMalloc(&ptr, sizeof(int));
work<<<1, 1>>>(ptr);
// cudaDeviceSynchronize();
int res{};
cudaMemcpy(&res, ptr, sizeof(int), cudaMemcpyDeviceToHost);
std::printf("res = %d\n", res);
cudaFree(ptr);
return 0;
}
统一内存地址技术(Unified Memory)
还有一种在比较新的显卡上支持的特性,那就是统一内存(managed),只需把 cudaMalloc 换成 cudaMallocManaged 即可,释放时也是通过 cudaFree。这样分配出来的地址,不论在 CPU 还是 GPU 上都是一模一样的,都可以访问。而且拷贝也会自动按需进行(当从 CPU 访问时),无需手动调用 cudaMemcpy,大大方便了编程人员,特别是含有指针的一些数据结构。
❗ 注意:
cudaMallocManaged需要手动进行同步
#include <cstdio>
#include <cuda_runtime.h>
__global__ void kernel(int *ptr) {
*ptr = 52;
}
int main() {
int *ptr;
cudaMallocManaged(&ptr, sizeof(int));
kernel<<<1, 1>>>(ptr);
cudaDeviceSynchronize();
std::printf("res = %d\n", *ptr);
cudaFree(ptr);
return 0;
}
数组
如 malloc 一样,可以用 cudaMalloc 配合 n * sizeof(int),分配一个大小为 n 的整型数组。这样就会有 n 个连续的 int 数据排列在内存中,而 arr 则是指向其起始地址。然后把 arr 指针传入 kernel,即可在里面用 arr[i] 访问它的第 i 个元素。
网格跨步循环(grid-stride loop)
无论调用者指定了多少个线程(blockDim),都能自动根据给定的 n 区间循环,不会越界,也不会漏掉几个元素。
这样一个 for 循环非常符合 CPU 上常见的 parallel for 的习惯,又能自动匹配不同的 blockDim,看起来非常方便。
其实这里可以这样理解,长度为 $n$ 的数组的第 $i$ 个元素会被第 $i \bmod \texttt{blockDim.x}$ 号线程处理,由于 $i \bmod \texttt{blockDim.x}$ 是唯一确定的,所以第 $i$ 个元素会被恰好处理一次。
#include <cstdio>
#include <cuda_runtime.h>
__global__ void work(int *arr, int n) {
for (int i = threadIdx.x; i < n; i += blockDim.x) {
arr[i] = i;
}
}
int main() {
int n = 1e7, *arr{};
cudaMallocManaged(&arr, n * sizeof(int));
work<<<1, 16>>>(arr, n);
cudaDeviceSynchronize();
for (int i = 0; i < n; i += 10000)
std::printf("arr[%d] = %d\n", i, arr[i]);
cudaFree(arr);
return 0;
}
网格跨步循环:扩展到板块
网格跨步循环实际上本来是这样,利用扁平化的线程数量和线程编号实现动态大小。
同样,无论调用者指定每个板块多少线程(blockDim),总共多少板块(gridDim)。都能自动根据给定的 n 区间循环,不会越界,也不会漏掉几个元素。
这样一个 for 循环非常符合 CPU 上常见的 parallel for 的习惯,又能自动匹配不同的 blockDim 和 gridDim,看起来非常方便。
#include "helper_cuda.h"
#include <cstdio>
#include <cuda_runtime.h>
// 网格跨步循环
__global__ void work(int *arr, int n) {
const int dx = blockDim.x * gridDim.x;
for (int i = blockDim.x * blockIdx.x + threadIdx.x; i < n; i += dx) {
arr[i] = i;
}
}
int main() {
int n = 1e8, *arr{};
checkCudaErrors(cudaMallocManaged(&arr, n * sizeof(int)));
work<<<32, 128>>>(arr, n);
checkCudaErrors(cudaDeviceSynchronize());
// for (int i = 0; i < n; i += 10000)
// std::printf("arr[%d] = %d\n", i, arr[i]);
checkCudaErrors(cudaFree(arr));
return 0;
}
C++ 封装
封装 std::vector
你知道吗?std::vector 作为模板类,其实有两个模板参数:std::vector<T, AllocatorT>
那为什么我们平时只用了 std::vectorstd::allocator<T>。
也就是 std::vector<T> 等价于 std::vector<T, std::allocator<T>>。
std::allocator<T> 的功能是负责分配和释放内存,初始化 T 对象等等。
它具有如下几个成员函数:
T *allocate(size_t n) // 分配长度为n,类型为T的数组,返回其起始地址
void deallocate(T *p, size_t n) // 释放长度为n,起始地址为p,类型为T的数组
抽象的 std::allocator 接口
vector 会调用 std::allocator<T> 的 allocate/deallocate 成员函数,它又会去调用标准库的 malloc/free 分配和释放内存空间(即它分配是的 CPU 内存)。
我们可以自己定义一个和 std::allocator<T> 一样具有 allocate/deallocate 成员函数的类,这样就可以“骗过”vector,让它不是在 CPU 内存中分配,而是在 CUDA 的统一内存(managed)上分配。
实际上这种“骗”来魔改类内部行为的操作,正是现代 C++ 的 concept 思想所在。因此替换 allocator 实际上是标准库允许的,因为它提升了标准库的泛用性。
核函数可以是一个模板函数
刚刚说过 CUDA 的优势在于对 C++ 的完全支持。所以 __global__ 修饰的核函数自然也是可以为模板函数的。
调用模板时一样可以用自动参数类型推导,如有手动指定的模板参数(单尖括号)请放在三重尖括号的前面。
template <int N, class T>
__global__ void kernel(T *arr) {
for (int i = blockDim.x * blockIdx.x + threadIdx.x;
i < N; i += blockDim.x * gridDim.x) {
arr[i] = i;
}
}
int main() {
constexpr int n = 65536;
std::vector<int, CudaAllocator<int>> arr(n);
kernel<n><<<32, 128>>>(arr.data());
checkCudaErrors(cudaDeviceSynchronize());
for (int i = 0; i < n; i++) {
printf("arr[%d]: %d\n", i, arr[i]);
}
return 0;
}
核函数可以传递回调函数
核函数可以接受函子(functor),实现函数式编程
需要注意三点:
- 这里的
func不可以是const func &,那样会变成一个指向 CPU 内存地址的指针,从而出错。所以 CPU 向 GPU 的传参必须按值传。 - 做参数的这个函数必须是一个有着成员函数
operator()的类型,即functor类。而不能是独立的函数,否则报错。 - 这个函数必须标记为
__device__,即 GPU 上的函数,否则会变成 CPU 上的函数。
进一步:函子可以是 lambda 表达式
可以直接写 lambda 表达式,不过必须在 [] 后,() 前,插入 __device__ 修饰符。
而且需要开启 --extended-lambda 开关。
为了只对 .cu 文件开启这个开关,可以用 CMake 的生成器表达式,限制 flag 只对 CUDA 源码生效,这样可以混合其它 .cpp 文件也不会发生 gcc 报错的情况了。。
target_compile_options(main PUBLIC $<$<COMPILE_LANGUAGE:CUDA>:--extended-lambda>)
❗ 注意观察代码的 lambda 表达式是如何捕获外部变量的
具体示例代码间下一节😆
数学运算
经典案例1:并行地求 sin 值
这里为什么用 sinf 而不是 sin?
因为 sin 是 double 类型的正弦函数,而我们需要的 sinf 是 float 类型的正弦函数。可不要偷懒少打一个 f 哦,否则影响性能。
适当调整板块数量 gridDim 和每板块的线程数量 blockDim,还可以更快一些。
顺便一提,这样的数学函数还有 sqrtf,rsqrtf,cbrtf,rcbrtf,powf,sinf,cosf,sinpif,cospif,sincosf,sincospif,logf,log2f,log10f,expf,exp2f,exp10f,tanf,atanf,asinf,acosf,fmodf,fabsf,fminf,fmaxf。
稍微快一些,但不完全精确的 __sinf
两个下划线的 __sinf 是 GPU intrinstics,精度相当于 GLSL 里的那种。适合对精度要求不高,但有性能要求的图形学任务。
类似的这样的低精度内建函数还有 __expf、__logf、__cosf、__powf 等。
还有 __fdividef(x, y) 提供更快的浮点除法,和一般的除法有相同的精确度,但是在 $2^{216} < y < 2^{218}$ 时会得到错误的结果。
#include <cstdio>
#include <cuda_runtime.h>
#include <vector>
// #include <functional>
#include "helper_cuda.h"
#include "ticktock.h"
#include "cudaAllocator.hpp"
// using func = std::function<void (int)>;
template<typename func>
__global__ void paraller_for(int n, func f) {
for (int i = blockDim.x * blockIdx.x + threadIdx.x; i < n; i += blockDim.x * gridDim.x) {
f(i);
}
}
int main() {
int n = 1 << 25;
std::vector<float, cudaAllocator<float> > gpu(n);
std::vector<float> cpu(n);
TICK(cpu_sinf);
for (int i = 0; i < n; ++i) cpu[i] = sinf(i);
TOCK(cpu_sinf);
TICK(gpu_sinf);
paraller_for<<<n / 512, 128>>>(n, [gpu = gpu.data()] __device__ (int i) {
gpu[i] = sinf(i);
});
checkCudaErrors(cudaDeviceSynchronize());
TOCK(gpu_sinf);
// for (int i = 0; i < n; i += 10000) {
// printf("diff %d = %f\n", i, gpu[i] - cpu[i]);
// }
return 0;
}
编译器选项:–use_fast_math
如果开启了 --use_fast_math 选项,那么所有对 sinf 的调用都会自动被替换成 __sinf。
--ftz=true会把极小数(denormal)退化为0。--prec-div=false降低除法的精度换取速度。--prec-sqrt=false降低开方的精度换取速度。--fmad因为非常重要,所以默认就是开启的,会自动把a * b + c优化成乘加(FMA)指令。
开启 --use_fast_math 后会自动开启上述所有。
经典案例2:SAXPY(Scalar A times X Plus Y)
即标量 A 乘 X 加 Y。
这是很多 CUDA 教科书上的 Hello, world。
#include "cudaAllocator.hpp"
#include <cmath>
#include <cstdio>
#include <vector>
template<typename T>
__global__ void parallel_for(int n, T fun) {
for (int i = blockDim.x * blockIdx.x + threadIdx.x;
i < n;
i += blockDim.x * gridDim.x) {
fun(i);
}
}
int main() {
constexpr int n = 65536;
float a = acosf(-1.0f);
std::vector<float, cudaAllocator<float> > x(n);
std::vector<float, cudaAllocator<float> > y(n);
for (int i = 0; i < n; ++i) {
x[i] = std::rand() / static_cast<float>(RAND_MAX);
y[i] = std::rand() / static_cast<float>(RAND_MAX);
}
auto fun = [a, x = x.data(), y = y.data()] __device__ (int i) {
x[i] = a * x[i] + y[i];
};
parallel_for<<<n / 512, 128>>>(n, fun);
checkCudaErrors(cudaDeviceSynchronize());
for (int i = 0; i < n; ++i) {
std::printf("x[%d] = %f\n", i, x[i]);
}
return 0;
}
thrust 库
thrust::vector
thrust::universal_vector
虽然自己实现 CudaAllocator 很有趣,也帮助我们理解了底层原理。但是既然 CUDA 官方已经提供了 thrust 库,那就用它们的好啦。
thrust::universal_vector 会在统一内存上分配,因此不论 GPU 还是 CPU 都可以直接访问到。
❗ 需要包括头文件
<thrust/universal_vector.h>,后面同理
#include "cudaAllocator.hpp"
#include <cmath>
#include <cstdio>
#include <thrust/universal_vector.h>
template<typename T>
__global__ void parallel_for(int n, T fun) {
for (int i = blockDim.x * blockIdx.x + threadIdx.x;
i < n;
i += blockDim.x * gridDim.x) {
fun(i);
}
}
int main() {
constexpr int n = 65536;
float a = acosf(-1.0f);
thrust::universal_vector<float> x(n);
thrust::universal_vector<float> y(n);
for (int i = 0; i < n; ++i) {
x[i] = std::rand() / static_cast<float>(RAND_MAX);
y[i] = std::rand() / static_cast<float>(RAND_MAX);
}
auto fun = [a, x = x.data(), y = y.data()] __device__ (int i) {
x[i] = a * x[i] + y[i];
};
parallel_for<<<n / 512, 128>>>(n, fun);
checkCudaErrors(cudaDeviceSynchronize());
for (int i = 0; i < n; ++i) {
std::printf("x[%d] = %f\n", i, x[i]);
}
return 0;
}
thrust::device_vector 和 thrust::host_vector
而 device_vector 则是在 GPU 上分配内存,host_vector 在 CPU 上分配内存。
可以通过 = 运算符在 device_vector 和 host_vector 之间拷贝数据,它会自动帮你调用 cudaMemcpy,非常智能。
比如这里的 x_dev = x_host 会把 CPU 内存中的 x_host 拷贝到 GPU 的 x_dev 上。
示例代码见下一小节
thrust::generate 和 thrust::for_each
thrust 提供了很多类似于标准库里的模板函数,比如 thrust::generate(b, e, f) 对标 std::generate,用于批量调用 f() 生成一系列(通常是随机)数,写入到 [b, e) 区间。
其前两个参数是 device_vector 或 host_vector 的迭代器,可以通过成员函数 begin() 和 end() 得到。第三个参数可以是任意函数,这里用了 lambda 表达式。
同理,还有 thrust::for_each(b, e, f) 对标 std::for_each。它会把 [b, e) 区间的每个元素 x 调用一遍 f(x)。这里的 x 实际上是一个引用。如果 b 和 e 是常值迭代器则是个常引用,可以用 cbegin(),cend() 获取常值迭代器。
当然还有 thrust::reduce,thrust::sort,thrust::find_if,thrust::count_if,thrust::reverse,thrust::inclusive_scan 等。
#include <cmath>
#include <cstdio>
#include <cuda_runtime.h>
#include <thrust/host_vector.h>
#include <thrust/device_vector.h>
#include <thrust/generate.h>
template<typename T>
__global__ void parallel_for(int n, T fun) {
for (int i = blockDim.x * blockIdx.x + threadIdx.x;
i < n;
i += blockDim.x * gridDim.x) {
fun(i);
}
}
int main() {
constexpr int n = 65536;
float a = acosf(-1.0f);
thrust::host_vector<float> x_host(n);
thrust::host_vector<float> y_host(n);
auto float_rand = [] {
return std::rand() / static_cast<float>(RAND_MAX);
};
thrust::generate(x_host.begin(), x_host.end(), float_rand);
thrust::generate(y_host.begin(), y_host.end(), float_rand);
thrust::device_vector<float> x_dev = x_host;
thrust::device_vector<float> y_dev = y_host;
auto print = [] __device__ (float x) {
std::printf("%f\n", x);
};
thrust::for_each(x_dev.begin(), x_dev.end(), print);
return 0;
}
thrust::zip_iterator
可以用 thrust::make_zip_iterator(a, b) 把多个迭代器合并起来,相当于 Python 里的 zip。
然后在函数体里通过 const auto &tup 捕获,并通过 thrust::get<index>(tup) 获取这个合并迭代器的第 index 个元素……之所以它搞这么复杂,其实是因为 thrust 需要兼容一些“老年程序”爱用的 C++03,不然早该换成 C++11 的 std::tuple 和 C++17 的 structual-binding 语法了…
thrust::for_each(
thrust::make_zip_iterator(x_dev.begin(), y_dev.cbegin()),
thrust::make_zip_iterator(x_dev.end(), y_dev.cend()),
[a] __device__ (const auto &tup) {
auto &x = thrust::get<0>(tup);
const auto &y = thrust::get<1>(tup);
x = a * x + y;
}
);
原子操作
atomicAdd
如何并行地对数组进行求和操作?显然,如果直接并行地把结果累加到一个变量上,会出现数据竞争的问题,从而导致结果与预期不符。
解决办法是使用原子操作。原子操作的功能就是保证读取/加法/写回三个操作,不会有另一个线程来打扰。
CUDA 也提供了这种函数,即 atomicAdd。效果和 += 一样,不过是原子的。它的第一个参数是个指针,指向要修改的地址。第二个参数是要增加多少。也就是说:
atomicAdd(dst, src) 和 *dst += src 差不多。
atomicAdd:会返回旧值(划重点!)
old = atomicAdd(dst, src) 其实相当于:
old = *dst;
*dst += src;
利用这一点可以实现往一个全局的数组 res 里追加数据的效果(push_back),其中 sum 起到了记录当前数组大小的作用。
因为返回的旧值就相当于在数组里“分配”到了一个位置一样,不会被别人占据。
例如下面的代码中 12 行可以理解为单线程的
res[idx++] = arr[i](假设 idx 初始值为 0)
#include <cstdio>
#include <cuda_runtime.h>
#include <thrust/host_vector.h>
#include <thrust/device_vector.h>
#include "ticktock.h"
#include "helper_cuda.h"
__global__ void parallel_filter(int *sum, int *res, const int *arr, int n) {
for (int i = blockDim.x * blockIdx.x + threadIdx.x; i < n; i += blockDim.x * gridDim.x) {
if (arr[i] >= 2) {
auto idx = atomicAdd(&sum[0], 1);
res[idx] = arr[i];
}
}
}
int main() {
constexpr int n = 1 << 24;
thrust::host_vector<int> arr_host(n);
thrust::device_vector<int> res_device(n);
thrust::device_vector<int> sum_device(1);
for (auto &x : arr_host) x = std::rand() % 4;
thrust::device_vector<int> arr_device = arr_host;
TICK(parallel_filter);
parallel_filter<<<n / 4096, 512>>>(sum_device.data().get(), res_device.data().get(), arr_device.data().get(), n);
checkCudaErrors(cudaDeviceSynchronize());
TOCK(parallel_filter);
thrust::host_vector<int> sum_host = sum_device;
thrust::host_vector<int> res_host = res_device;
printf("sum = %d\n", sum_host[0]);
for (int i = 0; i < sum_host[0]; ++i) {
if (res_host[i] < 2) {
puts("Wrong Answer!");
return 0;
}
}
puts("Accepted!");
return 0;
}
类似的其它原子操作
atomicAdd(dst, src):*dst += src
atomicSub(dst, src):*dst -= src
atomicOr(dst, src):*dst |= src
atomicAnd(dst, src):*dst &= src
atomicXor(dst, src):*dst ^= src
atomicMax(dst, src):*dst = std::max(*dst, src)
atomicMin(dst, src):*dst = std::min(*dst, src)
当然,它们也都会返回旧值(如果需要的话)。
atomicExch
除了刚刚那几个带有运算的原子操作,也有这种单纯是写入而没有读出的。
old = atomicExch(dst, src) 相当于:
old = *dst;
*dst = src;
注:Exch 是 exchange 的简写,对标的是 std::atomic 的 exchange 函数。
atomicCAS
原子地判断是否相等,相等则写入,并读取旧值。
old = atomicCAS(dst, cmp, src) 相当于:
old = *dst;
if (old == cmp)
*dst = src;
return old;
为什么需要这么复杂的一个原子指令?
因为 atomicCAS 的作用在于他可以用来实现任意 CUDA 没有提供的原子读-修改-写回指令。
比如这里我们通过 atomicCAS 实现了整数 atomicAdd 同样的效果。
另外,由于 atomicCAS 仅支持 int, unsigned int, unsigned short, unsigned long long 几种类型,可以配合按位转换(bit-cast)技巧来实现浮点数或者 long long 的计算操作。
CUDA 中有
__float_as_int和__int_as_float来实现浮点原子加法, C++ 20 中提供了模板函数std::bit_cast,具体见这里。
#include <cstdio>
#include <bit>
#include <cuda_runtime.h>
#include <thrust/universal_vector.h>
#include "ticktock.h"
using i64 = long long;
using ui64 = unsigned long long;
// atomicCAS 实现任意运算的原子操作,但不知道为什么速度慢的离谱,需要11s
__device__ i64 myAtomicAdd(i64 *dst, i64 src) {
ui64 expect, old = std::bit_cast<ui64>(*dst);
do {
expect = old;
old = atomicCAS((ui64*)dst, expect, std::bit_cast<ui64>(std::bit_cast<i64>(expect) + src));
} while (expect != old);
return old;
}
template<typename T>
__global__ void parallel_sum(T a, i64 *sum, int n) {
i64 local_sum = 0;
for (int i = blockDim.x * blockIdx.x + threadIdx.x; i < n; i += blockDim.x * gridDim.x) {
local_sum += a[i];
}
myAtomicAdd(sum, local_sum);
// atomicAdd(reinterpret_cast<ui64*>(sum), local_sum);
}
int main() {
constexpr int n = 65536;
thrust::universal_vector<int> a(n);
i64 *sum{};
cudaMallocManaged(&sum, sizeof(i64));
for (int i = 0; i < n; ++i) a[i] = i;
for (int _ = 1; _ <= 5; ++_) {
*sum = 0LL;
TICK(parallel_sum);
// parallel_sum<<<n / 4096, 512>>>(a.data(), sum, n);
parallel_sum<<<4, 4>>>(a.data(), sum, n);
cudaDeviceSynchronize();
TOCK(parallel_sum);
i64 ans = 1LL * (0 + n - 1) * n / 2;
if (*sum == ans) {
printf("sum = ans = %lld\n", *sum);
} else {
printf("sum = %lld ans = %lld\n", *sum, ans);
}
}
cudaFree(sum);
return 0;
}
但上面的代码不知道为什么速度慢的离谱,只有在板块数和线程数非常少的时候速度才会很快,否则速度超级慢,原子操作如此影响性能?
原子操作影响性能
由于原子操作要保证同一时刻只能有一个线程在修改某个地址,如果多个线程同时修改同一个就需要像“排队”那样,一个线程修改完了另一个线程才能进去,非常低效。
解决方法之一就是:先累加到局部变量 local_sum,最后一次性累加到全局的 sum。
这样每个线程就只有一次原子操作,而不是网格跨步循环的那么多次原子操作了。当然,我们需要调小 gridDim * blockDim 使其远小于 n,这样才能够减少原子操作的次数。
当然在上面例子的代码中已经使用了该优化技巧了。
正常情况下使用 CUDA 提供的原子操作就够了,如果库已经提供了需要的原子操作就不要自己写了。CUDA 编译器比较聪明,例如对于并行求和,直接调库进行求和,它会进行BLS(block-local storage)优化!(不过是否真是如此存在疑问🤔)
板块与共享内存
SM 与板块
SM(Streaming Multiprocessors)与板块(block)
GPU 是由多个流式多处理器(SM)组成的。每个 SM 可以处理一个或多个板块。
SM 又由多个流式单处理器(SP)组成。每个 SP 可以处理一个或多个线程。
每个 SM 都有自己的一块共享内存(shared memory),他的性质类似于 CPU 中的缓存——和主存相比很小,但是很快,用于缓冲临时数据。还有点特殊的性质,我们稍后会讲。
通常板块数量总是大于 SM 的数量,这时英伟达驱动就会在多个 SM 之间调度你提交的各个板块。正如操作系统在多个 CPU 核心之间调度线程那样……
不过有一点不同,GPU 不会像 CPU 那样做时间片轮换——板块一旦被调度到了一个 SM 上,就会一直执行,直到他执行完退出,这样的好处是不存在保存和切换上下文(寄存器,共享内存等)的开销,毕竟 GPU 的数据量比较大,禁不起这样切换来切换去……
一个 SM 可同时运行多个板块,这时多个板块共用同一块共享内存(每块分到的就少了)。
而板块内部的每个线程,则是被进一步调度到 SM 上的每个 SP。
板块的共享内存
同一个板块中的每个线程,都共享着一块存储空间,他就是共享内存。在 CUDA 的语法中,共享内存可以通过定义一个修饰了 __shared__ 的变量来创建。因此我们可以把刚刚的 local_sum 声明为 __shared__ 就可以让他从每个线程有一个,升级为每个板块有一个了。
板块内线程的同步
__syncthreads() 指令强制同步当前板块内的所有线程。也就是让所有线程都运行到 __syncthreads() 所在位置以后,才能继续执行下去。
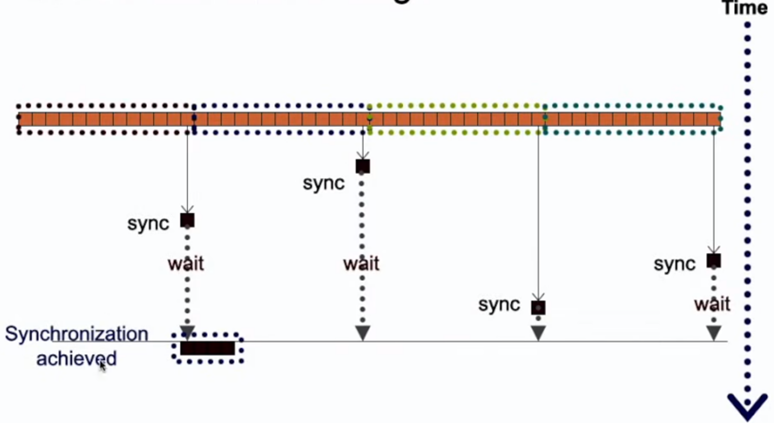
线程组分歧(warp divergence)
GPU 线程组(warp)中 32 个线程实际是绑在一起执行的,就像 CPU 的 SIMD 那样。因此如果出现分支(if)语句时,如果 32 个 cond 中有的为真有的为假,则会导致两个分支都被执行!不过在 cond 为假的那几个线程在真分支会避免修改寄存器和访存,产生副作用。而为了避免会产生额外的开销。因此建议 GPU 上的 if 尽可能 32 个线程都处于同一个分支,要么全部真要么全部假,否则实际消耗了两倍时间!
经典案例:BLS(block-local storage)并行求和
直接看代码和示意图吧,我实在懒得写了。
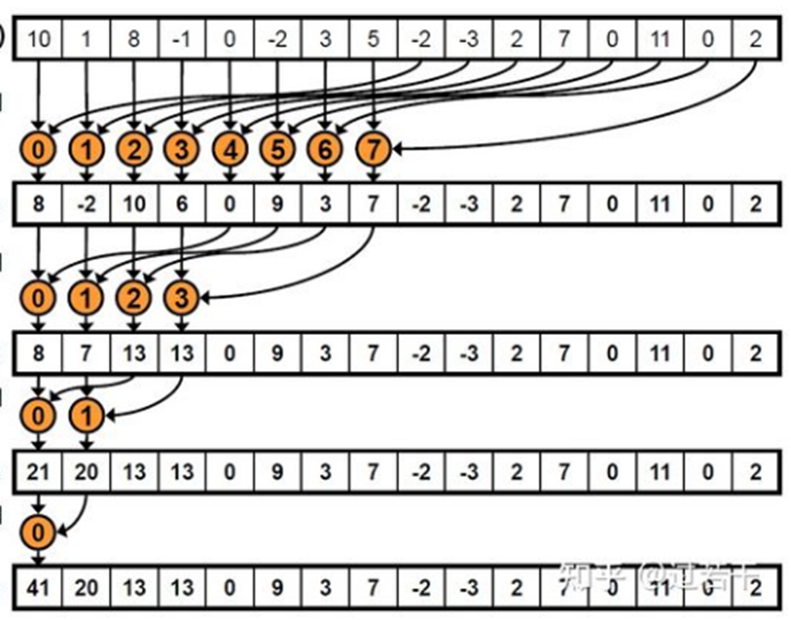
大概就是递归地缩并,时间复杂度是 $\mathcal O(\log n)$。
同样是缩并到一定小的程度开始就切断(cutoff),开始用 CPU 串行求和。
#include <cstdio>
#include <cuda_runtime.h>
#include "helper_cuda.h"
#include <vector>
#include "cudaAllocator.hpp"
#include "ticktock.h"
template <int blockSize, class T>
__global__ void parallel_sum_kernel(T *sum, T const *arr, int n) {
__shared__ volatile int local_sum[blockSize];
int j = threadIdx.x;
int i = blockIdx.x;
T temp_sum = 0;
for (int t = i * blockSize + j; t < n; t += blockSize * gridDim.x) {
temp_sum += arr[t];
}
local_sum[j] = temp_sum;
__syncthreads();
if constexpr (blockSize >= 1024) {
if (j < 512)
local_sum[j] += local_sum[j + 512];
__syncthreads();
}
if constexpr (blockSize >= 512) {
if (j < 256)
local_sum[j] += local_sum[j + 256];
__syncthreads();
}
if constexpr (blockSize >= 256) {
if (j < 128)
local_sum[j] += local_sum[j + 128];
__syncthreads();
}
if constexpr (blockSize >= 128) {
if (j < 64)
local_sum[j] += local_sum[j + 64];
__syncthreads();
}
if (j < 32) {
if constexpr (blockSize >= 64)
local_sum[j] += local_sum[j + 32];
if constexpr (blockSize >= 32)
local_sum[j] += local_sum[j + 16];
if constexpr (blockSize >= 16)
local_sum[j] += local_sum[j + 8];
if constexpr (blockSize >= 8)
local_sum[j] += local_sum[j + 4];
if constexpr (blockSize >= 4)
local_sum[j] += local_sum[j + 2];
if (j == 0) {
sum[i] = local_sum[0] + local_sum[1];
}
}
}
template <int reduceScale = 4096, int blockSize = 256, int cutoffSize = reduceScale * 2, class T>
int parallel_sum(T const *arr, int n) {
if (n > cutoffSize) {
std::vector<int, cudaAllocator<int>> sum(n / reduceScale);
parallel_sum_kernel<blockSize><<<n / reduceScale, blockSize>>>(sum.data(), arr, n);
return parallel_sum(sum.data(), n / reduceScale);
} else {
checkCudaErrors(cudaDeviceSynchronize());
T final_sum = 0;
for (int i = 0; i < n; i++) {
final_sum += arr[i];
}
return final_sum;
}
}
int main() {
int n = 1 << 24;
std::vector<int, cudaAllocator<int>> arr(n);
int ans = 0;
for (int i = 0; i < n; i++) {
arr[i] = std::rand() % 4;
ans += arr[i];
}
TICK(parallel_sum);
int final_sum = parallel_sum(arr.data(), n);
TOCK(parallel_sum);
printf("result: %d, ans = %d\n", final_sum, ans);
return 0;
}
结论:编译器很智能。刚刚我们深入研究了如何 BLS 做数组求和,只是出于学习原理的目的。实际做求和时,直接写 atomicAdd 即可。反正编译器会自动帮我们优化成 BLS,而且他优化得比我们手写的更好……然后 atomicMax 求数组最大值,也同理。
共享内存进阶
笔者太菜也不太懂,懒得写了,这一章和上一章都详见 PPT 吧。
GPU 优化手法总结
线程组分歧(wrap divergence):尽量保证 32 个线程都进同样的分支,否则两个分支都会执行。
延迟隐藏(latency hiding):需要有足够的 blockDim 供 SM 在陷入内存等待时调度到其他线程组。
寄存器打翻(register spill):如果核函数用到很多局部变量(寄存器),则 blockDim 不宜太大。
共享内存(shared memory):全局内存比较低效,如果需要多次使用,可以先读到共享内存。
跨步访问(coalesced acccess):建议先顺序读到共享内存,让高带宽的共享内存来承受跨步。
区块冲突(bank conflict):同一个 warp 中多个线程访问共享内存中模 32 相等的地址会比较低效,可以把数组故意搞成不对齐的 33 跨步来避免。
番外篇
Makefile
通过下面的 Makefile,我们可以就不用每次都麻烦的手动编译啦。需要编译 xxx.cu 就直接 make xxx 就行了。
# 获取当前目录和目录下所有的 .cu 文件
WORKDIR = $(shell pwd)
SOURCES = $(wildcard *.cu)
# 将 .cu 文件列表转换为对应的可执行文件列表
TARGETS = $(SOURCES:%.cu=%)
# 编译器和编译参数
CXX = nvcc
CXXFLAGS = -std=c++20 --extended-lambda --expt-relaxed-constexpr
CXXFLAGS += --gpu-architecture=compute_86 --gpu-code=sm_86
CXXFLAGS += -I${WORKDIR}/include
# 默认规则,编译所有可执行文件
all: $(TARGETS)
# 通用规则,将 .cu 文件编译为可执行文件
%: %.cu
$(CXX) $(CXXFLAGS) $< -o $@
# 清理规则,删除所有可执行文件
clean:
rm -f $(TARGETS)
.PHONY: all clean
clangd 配置文件
为了更好的编写代码体验,需要配置一下 clangd 文件。主要是为了避免误报错,感觉 clangd 对 nvcc 的支持也不是很完美。引入一些头文件会造成误报错,看着就很烦。
CompileFlags:
Add: [-std=c++20,
--cuda-path=/usr/local/cuda,
-I/usr/local/cuda/include,
-L/usr/local/cuda/lib64,
-I/mnt/e/workspace/learncuda/include,
]
Compiler: /usr/local/cuda/bin/nvcc
Diagnostics:
Suppress: [variadic_device_fn, ovl_no_viable_function_in_init]
variadic_device_fn 是为了抑制 #include <thrust/universal_vector.h> 误报错
In included file: CUDA device code does not support variadic functions
ovl_no_viable_function_in_init 是为了抑制 #include "CudaAllocator.h" 报错(CudaAllocator.h 是小彭老师自己写的一个头文件,这个不是误报,确实编译通不过,不知道为什么)
In template: no matching constructor for initialization of 'std::vector<int, CudaAllocator<int>>::allocator_type' (aka 'CudaAllocator<int>')
