Raft 算法鼎鼎大名早有耳闻,也是 MIT 6.824 分布式课程的经典 Lab。回想 2022 年,要是我能放弃失败的 XCPC 集训,和林爷爷一起学分布式做项目,我也就能更早踏入 sys 方向的大门(坑),走上群友的成功之路。
回想 THU 保研推免面试前的一周,由于导师的研究方向是分布式系统,而我对分布式系统一无所知,万一面试被问到不就尴尬了,于是我花了几天速通 DDIA 作者 Martin Kleppmann 讲分布式系统,一直看到 Raft 算法,对 Raft 有了初步窥探,然后几乎忘光。又过了一年半,这学期上导师的分布式系统课程,不得不学了,本打算寒假的时候把 Lab 写完这学期就轻松了,然而寒假没有导师 Push,时间安排自由又摆了,最后在寒假的尾巴速成了 Golang,大年初二赶回校园,写了 Lab 1 MapReduce 然后又停滞了。
当导师讲完 Raft 后我是比较懵逼的,因为在我印象中 Raft 算法很复杂,但课上很快就讲完了,很多细节我也没搞清楚。看了 Raft paper 后豁然开朗,不得不说这个 paper 写作写得很不戳,内容讲解也很清晰,Raft 提出来的一大动机就是易理解和教学,天下苦 Paxos 久已。
总体思路:写这个 Raft Lab 主要参考 paper 中的 Figure 2/13,以及 Martin Kleppmann 讲分布式系统的课程笔记,该课程笔记给出了 Raft 实现的伪代码,质量很高。
Raft 算法
Raft 算法细节需要读者自行学习和看 paper,这里仅给出笔者觉得很有帮助的参考资料。
Raft Paper
Figure 2

Raft 算法的几条性质

Figure 13

Martin Kleppmann 讲分布式系统
节点状态转换
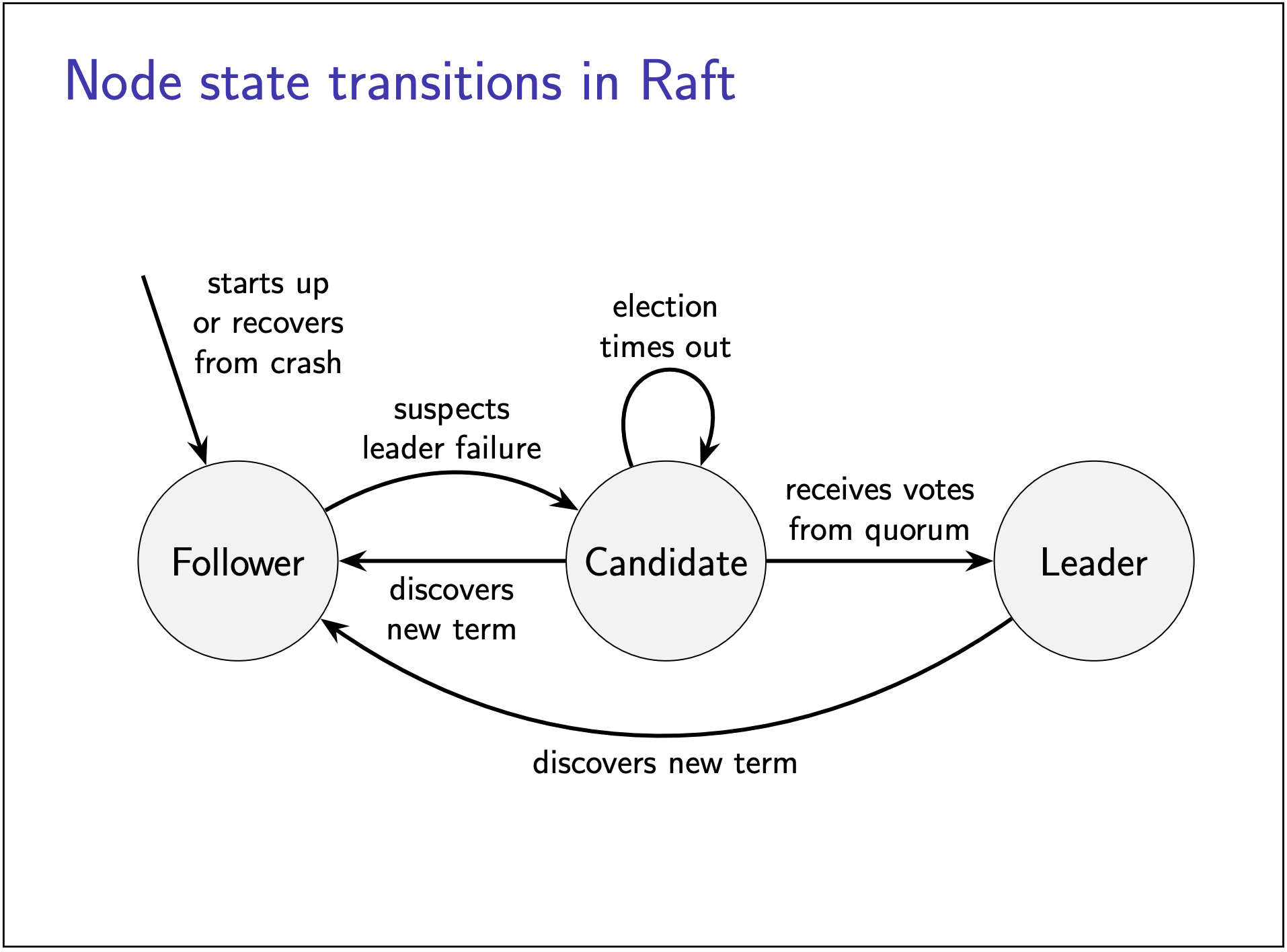
伪代码









Part 3A: leader election
思路:
- 我的 raft 结构体基本都是参照 Paper Figure 2 中的字段设计的
- 实验限制了 heartbeats 的频率 1s 不能超过 10 次,因此我设置间隔 125ms 发送 heartbeat,并把 electionTimeout 设为 1s
- 由于 Hint 建议我们不要使用 time.Timer 或 time.Ticker,我对 Golang 也不熟,选择使用一个 ticker() goroutine 间隔 sleep 25ms 轮询的方式实现,并且 25ms 整除 125ms 和 1s
- 在改变身份(setState)的时候重置 timer,可以省去很多单独的计时器操作
⚠️ 需要注意的是,Martin Kleppmann 给的伪代码中对计时器相关部分个人感觉有问题,比如伪代码中都是 cancel election timer,实际应该是 reset timer 才对,此外收到 AppendEntries 也应该 reset election timer,AppendEntries 有 log 载荷视为日志复制,没有 log 载荷视为 heartbeat,伪代码中没有 reset。另外伪代码没有 heartbeat 计时器相关的代码。
数据结构
Raft 结构体的字段完全对应 Paper Figure 2 的三组状态:所有节点持久化的 currentTerm、votedFor、log,所有节点的易失状态 commitIndex、lastApplied,以及 leader 专属的 nextIndex[]、matchIndex[]。在此基础上额外增加了三个字段用于驱动状态机:currentState 表示当前角色,lastHeartbeatSent 是 leader 的心跳计时器,lastHeartbeatRecv 是 follower/candidate 的选举超时计时器,另有 randAdditionalTime 存储随机附加时间以打散选票。
type Raft struct {
// ...
currentTerm int
votedFor int
log []LogEntry
commitIndex int
lastApplied int
nextIndex []int
matchIndex []int
currentState raftState
currentLeader int
lastHeartbeatSent time.Time
lastHeartbeatRecv time.Time
randAdditionalTime time.Duration
}
节点角色用 raftState 枚举表示,定义在 util.go 中,同时也在这里集中定义了两个关键时间常量。实验要求心跳频率不超过 10 次/秒,取 125ms 作为心跳间隔留有余量;选举超时设为 1000ms,加上最多 500ms 的随机附加时间。
const (
heartbeatTimeout = 125 * time.Millisecond
electionTimeout = 1000 * time.Millisecond
)
func randomizedAdditionalTime() time.Duration {
return time.Duration(rand.Int63()%500) * time.Millisecond
}
状态转换与计时器
setState 在状态转换时顺带重置对应的计时器(转为 follower 时重置选举计时器并重新随机化附加时间;转为 leader 时重置心跳计时器),这样就不需要在每个 RPC handler 里单独维护计时器。调用方需持锁调用。
func (rf *Raft) setState(state raftState) {
if rf.currentState != state {
rf.currentState = state
switch state {
case followerState:
rf.lastHeartbeatRecv = time.Now()
rf.randAdditionalTime = randomizedAdditionalTime()
case candidateState:
case leaderState:
rf.lastHeartbeatSent = time.Now()
}
}
}
ticker 轮询
ticker() goroutine 每 25ms 醒来一次,检查当前角色并决定下一步动作。25ms 能整除 125ms 和 1000ms。leader 检查心跳计时器是否到期,到期则广播心跳;follower 和 candidate 检查选举超时,超时则发起选举。注意 StartElection 内部会自己加锁,因此调用前需先释放锁,返回后再重新加锁,并在此处重置选举计时器。
func (rf *Raft) ticker() {
for true {
time.Sleep(25 * time.Millisecond)
rf.mu.Lock()
switch rf.currentState {
case leaderState:
if time.Since(rf.lastHeartbeatSent) >= heartbeatTimeout {
rf.broadcastHeartbeat()
rf.lastHeartbeatSent = time.Now()
}
case followerState, candidateState:
if time.Since(rf.lastHeartbeatRecv) >= electionTimeout+rf.randAdditionalTime {
rf.mu.Unlock()
rf.StartElection()
rf.mu.Lock()
rf.lastHeartbeatRecv = time.Now()
rf.randAdditionalTime = randomizedAdditionalTime()
}
}
rf.mu.Unlock()
}
}
选举流程
StartElection 先在锁内完成本轮选举的准备工作:term 自增,切换为 candidate,为自己投票,构造 RequestVoteArgs,然后释放锁。随后对每个 peer 并发发起 RPC,在回调 goroutine 中重新加锁处理结果。votesReceived 是一个被多个 goroutine 共享的计数器,由 rf.mu 保护。一旦票数过半且当前仍是 candidate(防止重复当选),立即切换为 leader 并广播一轮心跳,快速宣示主权、抑制其他节点发起新选举。若收到更高 term 的回复,则退回 follower。
func (rf *Raft) StartElection() {
rf.mu.Lock()
rf.currentTerm++
rf.setState(candidateState)
rf.votedFor = rf.me
args := &RequestVoteArgs{Term: rf.currentTerm, CandidateId: rf.me}
rf.mu.Unlock()
votesReceived := 1
for peer := range rf.peers {
if peer == rf.me {
continue
}
go func(peer int) {
reply := new(RequestVoteReply)
if rf.sendRPC("RequestVote", peer, args, reply) {
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.currentState == candidateState && reply.Term == rf.currentTerm && reply.VoteGranted {
votesReceived++
if votesReceived > len(rf.peers)/2 {
rf.setState(leaderState)
rf.currentLeader = rf.me
rf.broadcastHeartbeat()
}
} else if reply.Term > rf.currentTerm {
rf.currentTerm = reply.Term
rf.setState(followerState)
rf.votedFor = -1
}
}
}(peer)
}
}
RPC Handler
RequestVote handler 遵循 Figure 2 的逻辑:收到更高 term 时无条件更新 term 并退回 follower,重置 votedFor;在 term 相同且尚未投票(或已投给同一 candidate)的情况下授予选票。注意 3A 阶段暂未实现 log up-to-date 检查,这部分留到 3B 补充。
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
rf.setState(followerState)
rf.votedFor = -1
}
reply.Term = rf.currentTerm
if args.Term == rf.currentTerm && (rf.votedFor == -1 || rf.votedFor == args.CandidateId) {
rf.votedFor = args.CandidateId
reply.VoteGranted = true
} else {
reply.VoteGranted = false
}
}
AppendEntries handler 在 3A 阶段主要承担心跳接收的职责。收到合法 leader 的消息(term 相等)时,切换/保持 follower 状态,记录 leader id,并显式重置选举计时器。这里有一个细节:setState(followerState) 内部虽然也会重置计时器,但只在状态发生变化时触发;若节点已经是 follower,则不会重置。因此在 setState 之后需要再次显式重置,确保每次收到合法心跳都能刷新超时时间。
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
rf.votedFor = -1
}
if args.Term == rf.currentTerm {
rf.setState(followerState)
rf.currentLeader = args.LeaderId
}
// explicit reset regardless of whether setState triggered it
rf.lastHeartbeatRecv = time.Now()
rf.randAdditionalTime = randomizedAdditionalTime()
reply.Term = rf.currentTerm
reply.Success = args.Term == rf.currentTerm
}
Part 3B: log
思路:
- 关于 log 结构的设计,Raft paper 中的 log 是 1-indexed,Lab Hint 建议我们设计成 0-indexed 的并加上 dummy entry 在 index 0,也是说
log[0]保存了上一个 snapshot 的最后一个 term/index 和nilcommand。尽管 3B 不涉及 Snapshot,但这个保留设计会给后续 3C/3D 带来方便 - 在
src/raft1/util.go中我封装了 log 操作的一些 API,比如logLength()、lastLogEntry(),logAt()以实际 log index 作为下标访问返回对应 log entry,logIndex()以当前 log 数组下标访问返回实际的 log index,这些封装对我们写代码有很大帮助 - 参考
sofajraft的日志复制实现 。每个 peer 在启动时会为除自己之外的每个 peer 都分配一个 replicator 协程。对于 follower 节点,该协程利用条件变量执行 wait 来避免耗费 cpu,并等待变成 leader 时再被唤醒;对于 leader 节点,该协程负责尽最大地努力去向对应 follower 发送日志使其同步,直到该节点不再是 leader 或者该 follower 节点的 matchIndex 大于等于本地的 lastIndex。 - 用一个 applier 协程,让其不断的把 [lastApplied + 1, commitIndex] 区间的日志 push 到 applyCh 中去。这样既可保证每一条日志只会被 exactly once 地 push 到 applyCh 中,也可以使得日志 apply 到状态机和 raft 提交新日志可以真正的并行。
If election timeout elapses without receiving AppendEntries RPC from current leader or granting vote to candidate: convert to candidate
注意,也就是 Candidate 投票后需要重置计时器。
Log 结构与辅助 API
log[0] 是一个 dummy entry,其 Index 字段存储上一个 snapshot 截断点的实际 log index(3B 阶段始终为 0),Term 存储对应 term,Command 为 nil。这样设计的好处是:PrevLogIndex = 0 是合法的数组下标,第一条 AppendEntries 不需要特判;同时为 3D 的 log compaction 预留了接口,截断后只需更新 log[0] 即可,上层代码无需改动。
所有 log 访问都通过封装的 API 进行,避免直接操作数组下标引入 off-by-one 错误:
func (rf *Raft) logAt(index int) *LogEntry {
return &rf.log[index-rf.log[0].Index]
}
func (rf *Raft) logIndex(index int) int {
return index - rf.log[0].Index
}
func (rf *Raft) logLength() int {
return len(rf.log) - 1 + rf.log[0].Index
}
func (rf *Raft) lastLogEntry() *LogEntry {
return rf.logAt(rf.logLength())
}
logAt 和 logLength 以实际 log index(即对外暴露的、从 1 开始的逻辑 index)为参数,logIndex 则做反向转换,返回数组下标。这个区分在 3D 引入 snapshot 后尤为重要,因为数组下标和逻辑 index 之间会存在偏移。
选举限制(Election Restriction)
3A 的 RequestVote handler 暂时跳过了 log up-to-date 检查,3B 补上。Raft 的选举限制要求 candidate 的 log 至少和 receiver 一样新:先比较最后一条 entry 的 term,term 更大的更新;term 相同则 index 更大的更新。此外,Figure 2 的 Rules for Servers 中有一条容易忽略的规则:投票给 candidate 时也需要重置选举计时器,否则一个 follower 在投票后仍可能因超时而发起新选举,干扰已经在进行的选举。
lastTerm := rf.lastLogEntry().Term
logOK := args.LastLogTerm > lastTerm || (args.LastLogTerm == lastTerm && args.LastLogIndex >= rf.lastLogEntry().Index)
if args.Term == rf.currentTerm && logOK && (rf.votedFor == -1 || rf.votedFor == args.CandidateId) {
rf.votedFor = args.CandidateId
rf.resetElectionTimer()
reply.VoteGranted = true
}
replicator 与 applier 协程
日志复制的并发模型参考了 sofajraft 的设计。Make 时为每个 peer 启动一个 replicator goroutine,它持有该 peer 专属的条件变量锁,在不需要复制时调用 Wait 挂起,由 Start 或心跳路径通过 Signal 唤醒。needReplicateLog 判断当前是否仍是 leader 且该 peer 的 matchIndex 落后于本地最新 index,满足则调用 replicateLog 发送,否则继续等待。这样既避免了空转轮询,又能在有新日志时立即触发复制,而不必等到下一次心跳。
func (rf *Raft) replicator(peer int) {
rf.replicatorCond[peer].L.Lock()
defer rf.replicatorCond[peer].L.Unlock()
for true {
if rf.needReplicateLog(peer) {
rf.replicateLog(peer)
} else {
rf.replicatorCond[peer].Wait()
}
}
}
applier goroutine 同样用条件变量驱动,在 commitIndex 推进时被 Signal 唤醒。它先在锁内快照当前的 commitIndex,然后释放锁,将 [lastApplied+1, commitIndex] 区间的 entry 逐条发送到 applyCh,最后重新加锁更新 lastApplied。释放锁后发送到 channel 是关键:这使得 apply 和 Raft 内部的 RPC 处理可以真正并行,不会因为 channel 阻塞而持锁卡死。更新 lastApplied 时使用 max(rf.lastApplied, commitIndex) 而非直接赋值,是为了防止并发的 InstallSnapshot RPC 将 lastApplied 推进到更大值后被此处的赋值回退。
func (rf *Raft) applier() {
for true {
rf.mu.Lock()
commitIndex := rf.commitIndex // save commitIndex to avoid race condition
if rf.lastApplied >= commitIndex {
rf.applyCond.Wait()
}
entries := make([]LogEntry, commitIndex-rf.lastApplied)
copy(entries, rf.log[rf.logIndex(rf.lastApplied+1):rf.logIndex(commitIndex)+1])
rf.mu.Unlock()
for _, entry := range entries {
rf.applyCh <- raftapi.ApplyMsg{
CommandValid: true,
Command: entry.Command,
CommandIndex: entry.Index,
}
}
rf.mu.Lock()
// use max(rf.lastApplied, commitIndex) rather than commitIndex directly to avoid concurrently InstallSnapshot rpc causing rf.lastApplied to rollback
rf.lastApplied = max(rf.lastApplied, commitIndex)
rf.mu.Unlock()
}
}
AppendEntries 日志一致性检查
AppendEntries handler 在 3B 中需要完整实现 Figure 2 的五条 receiver 规则。logOK 检查 PrevLogIndex 处的 entry 是否存在且 term 匹配,不满足则直接返回 false,leader 收到后会递减 nextIndex 重试。通过检查后,处理冲突和追加的逻辑需要小心:不能无脑截断再追加,因为 follower 可能已经有了 leader 尚未发送的更新 entry(网络乱序场景)。正确做法是找到第一个冲突点,只截断冲突及之后的部分,再追加 leader 发来的新 entry。
logOK := args.PrevLogIndex <= rf.logLength() && (args.PrevLogIndex == 0 || rf.logAt(args.PrevLogIndex).Term == args.PrevLogTerm)
if args.Term == rf.currentTerm && logOK {
reply.Success = true
if len(args.Entries) > 0 && rf.logLength() > args.PrevLogIndex {
index := min(rf.logLength(), args.PrevLogIndex+len(args.Entries))
if rf.logAt(index).Term != args.Entries[index-args.PrevLogIndex-1].Term {
rf.log = rf.log[:rf.logIndex(args.PrevLogIndex)+1]
}
}
if args.PrevLogIndex+len(args.Entries) > rf.logLength() {
rf.log = append(rf.log, args.Entries[rf.logLength()-args.PrevLogIndex:]...)
}
if args.LeaderCommit > rf.commitIndex {
rf.commitIndex = args.LeaderCommit
rf.applyCond.Signal()
}
}
commitIndex 推进
leader 在收到 follower 的成功回复后更新 matchIndex[peer],然后调用 commitLogEntries 检查是否可以推进 commitIndex。做法是将 matchIndex 排序后取中位数(即 n/2 处,因为 matchIndex 是 0-indexed 且包含 leader 自身),若该值大于当前 commitIndex 且对应 entry 属于当前 term(Raft 不提交前任 term 的 entry),则更新 commitIndex 并唤醒 applier。
func (rf *Raft) commitLogEntries() {
n := len(rf.matchIndex)
tempIndex := make([]int, n)
copy(tempIndex, rf.matchIndex)
// reverse sort tempIndex to get the majority's match index
sort.Slice(tempIndex, func(i, j int) bool { return tempIndex[i] > tempIndex[j] })
// Note that tempIndex is 0-indexed, so the majority is at n/2
newCommitIndex := tempIndex[n/2]
if newCommitIndex > rf.commitIndex && rf.logAt(newCommitIndex).Term == rf.currentTerm {
rf.commitIndex = newCommitIndex
rf.applyCond.Signal()
}
}
Part 3C: persistence
思路:
- 根据 Lab Hint,3C 需要增加快速回退机制,这部分也是 Martin Kleppmann 伪代码里没有的。Hint 建议添加 3 个字段,实际上我们只需要添加 XIndex 和 XTerm 就够了。如果 follower 的日志过短,则返回 XTerm = -1,XIndex 为 follower 最后一个日志的 index + 1
- 对于 Persistent state,每次发生一次变动,都要调用
rf.persist()持久化。把这行代码添加到各个需要的位置,不要漏掉。
持久化
根据 Figure 2,需要持久化的状态只有三个:currentTerm、votedFor、log。commitIndex 和 lastApplied 是易失状态,重启后从 0 开始重新 apply 即可,上层状态机负责保证幂等性。persist 和 readPersist 的实现直接用 labgob 编解码,按固定顺序 encode/decode 三个字段。
func (rf *Raft) persist() {
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(rf.currentTerm)
e.Encode(rf.votedFor)
e.Encode(rf.log)
raftstate := w.Bytes()
rf.persister.Save(raftstate, nil)
}
func (rf *Raft) readPersist(data []byte) {
if len(data) < 1 { // bootstrap without any state?
return
}
r := bytes.NewBuffer(data)
d := labgob.NewDecoder(r)
var currentTerm, votedFor int
var log []LogEntry
if d.Decode(¤tTerm) != nil ||
d.Decode(&votedFor) != nil ||
d.Decode(&log) != nil {
DPrintf("Server %d failed to read persist data", rf.me)
} else {
rf.currentTerm, rf.votedFor, rf.log = currentTerm, votedFor, log
}
}
persist 的调用时机是关键,必须在每次修改持久化状态后立即调用,不能遗漏。涉及的位置有:RequestVote 和 AppendEntries handler 返回前(可能修改 currentTerm、votedFor、log)、StartElection 中自增 term 并投票后、Start 中追加新 entry 后,以及所有因收到更高 term 而退回 follower 的路径。这里用 defer rf.persist() 处理 handler 的情况,既简洁又不会遗漏——即使 handler 提前 return,defer 也会执行。代价是每次 RPC 都会触发一次序列化,即便状态没有变化,但对正确性而言这是最安全的做法。
快速回退(Fast Backup)
3B 中 nextIndex 每次失败只递减 1,在 follower 日志严重落后的场景下需要大量 RPC 才能找到一致点,TestBackup3B 虽然能过但耗时较长。3C 引入快速回退:follower 在拒绝 AppendEntries 时,额外返回冲突 entry 的 term(XTerm)和该 term 在 follower log 中第一次出现的 index(XIndex),让 leader 一次跳过整个冲突 term 的所有 entry。若 follower 日志过短(PrevLogIndex 超出 follower log 末尾),则返回 XTerm = -1,XIndex 设为 follower 最后一条 entry 的 index + 1,告知 leader 直接从这里开始发。
} else {
reply.Success = false
if rf.logLength() < args.PrevLogIndex {
reply.XTerm, reply.XIndex = -1, rf.logLength()+1
} else {
reply.XTerm = rf.logAt(args.PrevLogIndex).Term
for i := args.PrevLogIndex; i > 0 && rf.logAt(i).Term == reply.XTerm; i-- {
reply.XIndex = i
}
}
}
leader 收到失败回复后,根据 XTerm 分两种情况处理:若 XTerm == -1,直接将 nextIndex 设为 XIndex;否则在自己的 log 中从后往前找最后一条 term 等于 XTerm 的 entry,若找到则 nextIndex = i + 1(跳过 leader 中该 term 的最后一条之后),若找不到则 nextIndex = XIndex(跳过 follower 中整个 XTerm 的所有 entry)。
} else {
rf.nextIndex[peer] = reply.XIndex
if reply.XTerm != -1 {
for i := rf.logLength(); i >= reply.XIndex; i-- {
if rf.logAt(i).Term == reply.XTerm {
rf.nextIndex[peer] = i + 1
break
}
}
}
}
Part 3D: log compaction
这是 Raft Lab 的最后一个 Part,但确是最不容易通过的一个,在 Part 3D,之前写的 BUG 很可能会暴露出来。 Martin Kleppmann 伪代码同样没有 snapshot 这部分。
思路:
- 上层会在 log 增长到快接近设定的长度上限后调用 Snapshot 函数,此时我们需要截断 Snapshot 已包含部分的日志
- 对于 leader 发过来的 InstallSnapshot,只需要判断 term 是否正确,如果无误则 follower 只能无条件接受
- 此外,如果该 snapshot 的 lastIncludedIndex 小于等于本地的 commitIndex,那说明本地已经包含了该 snapshot 所有的数据信息,尽管可能状态机还没有这个 snapshot 新,即 lastApplied 还没更新到 commitIndex,但是 applier 协程也一定尝试在 apply 了,此时便没必要再去用 snapshot 更换状态机了。对于更新的 snapshot,这里通过异步的方式将其 push 到 applyCh 中。
- 由于日志会被 snapshot 截断,leader 广播日志的时候,需要根据维护的 nextIndex 数组判断是通过
AppendEntries还是InstallSnapshot发送日志。 - 由于日志会被 snapshot 截断,在很多其它地方的代码,也需要注意访问日志的下界不要低于
lastSnapshotEntry().Index
另外有一个卡了我两天的 BUG,在 InstallSnapshot 后 dummy entry 必须填上发过来 snapshot 的 LastIncludedTerm 和 LastIncludedIndex。不能省略这一步直接使用现有 index 位置的值,因为这个位置的 log 可能没有被 commit,它的内容已经被后面新的 log 覆盖了。否则,后续会因为 log 冲突,有概率 failed to reach agreement,无法通过测试。
分布式代码很难调试,可以参考 MIT6.824 助教写的 Debugging by Pretty Printing(原 Blog 地址已经失效,可以访问 Wayback Machine 存档),借助 Python 脚本处理 raw log,从而优雅地古法打 Log 进行调试。下面是具体效果展示:
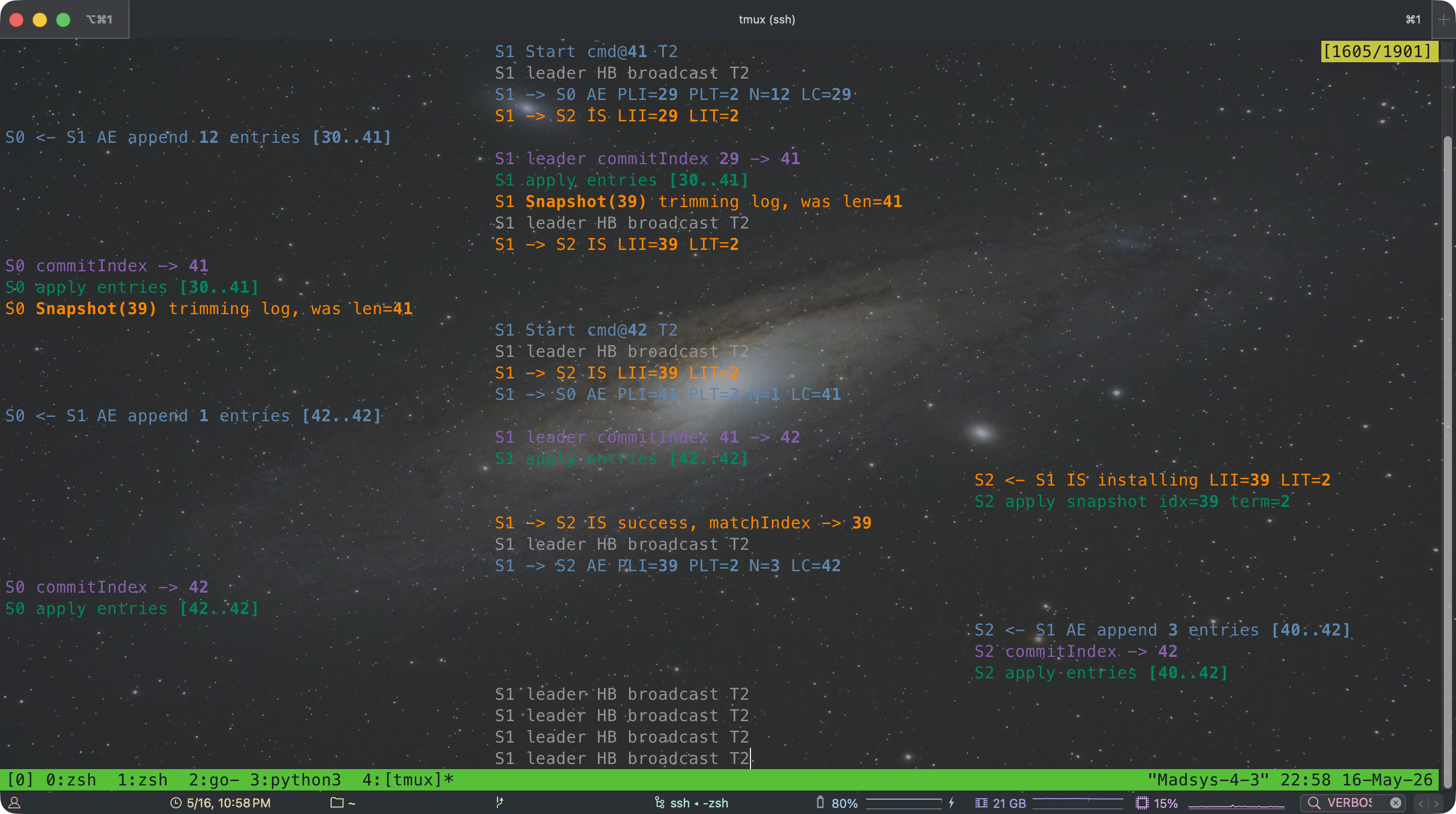
Snapshot
Snapshot 由上层服务调用,传入已经被快照覆盖的最高 log index 和序列化后的状态数据。实现上只需将 log[logIndex(index):] 切出来作为新的 log 数组,并将 log[0](dummy entry)的 Command 清空以避免持久化冗余数据,然后同时保存 Raft 状态和 snapshot 数据。注意 3C 中 persist 传的是 rf.persister.ReadSnapshot(),这里需要改为传入新的 snapshot 字节。为此将编码逻辑抽出为 encodeState,让 persist 和 Snapshot 都能复用。
func (rf *Raft) encodeState() []byte {
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(rf.currentTerm)
e.Encode(rf.votedFor)
e.Encode(rf.log)
return w.Bytes()
}
func (rf *Raft) Snapshot(index int, snapshot []byte) {
rf.mu.Lock()
defer rf.mu.Unlock()
if index <= rf.lastSnapshotEntry().Index {
return
}
newLog := make([]LogEntry, len(rf.log[rf.logIndex(index):]))
copy(newLog, rf.log[rf.logIndex(index):])
newLog[0].Command = nil // avoid persisting command in the dummy entry
rf.log = newLog
rf.persister.Save(rf.encodeState(), snapshot)
}
重启恢复时,readPersist 在还原 log 后需要将 lastApplied 和 commitIndex 初始化为 log[0].Index,因为 snapshot 截断点之前的 entry 已经被 apply 过了,不能重复 apply。
InstallSnapshot
当 leader 的 nextIndex[peer] 已经落在 snapshot 截断点之前时,AppendEntries 无法提供所需的 entry,此时 leader 改为发送 InstallSnapshot RPC。follower 收到后,若 LastIncludedIndex <= commitIndex,说明本地已经 commit 了这些数据,applier 迟早会 apply,直接忽略即可。否则需要截断或替换 log:若 LastIncludedIndex 在当前 log 范围内,保留其后的 suffix;若超出范围,则整个 log 只剩一个 dummy entry。
这里有一个关键细节:无论哪种情况,dummy entry 的 Term 和 Index 都必须显式设置为 LastIncludedTerm 和 LastIncludedIndex,不能依赖原有 entry 的值。原因是:当 LastIncludedIndex 在 log 范围内时,该位置的 entry 可能尚未 commit,其 term 可能已经被后续 leader 的 entry 覆盖,直接复用会导致 dummy entry 记录了错误的 term,进而在后续 AppendEntries 的 PrevLogTerm 检查中产生虚假冲突,概率性地导致 failed to reach agreement。这正是卡了两天的 bug 所在。
// Trim or replace the log
if args.LastIncludedIndex <= rf.logLength() {
// keep the suffix after the snapshot
offset := rf.logIndex(args.LastIncludedIndex)
newLog := make([]LogEntry, len(rf.log[offset:]))
copy(newLog, rf.log[offset:])
newLog[0].CommandBytes = nil
rf.log = newLog
} else {
// discard entire log, start fresh from snapshot point
rf.log = make([]LogEntry, 1)
}
// dummy entry must reflect the snapshot's term, not the original entry's term
rf.log[0].Term, rf.log[0].Index = args.LastIncludedTerm, args.LastIncludedIndex
rf.commitIndex, rf.lastApplied = args.LastIncludedIndex, args.LastIncludedIndex
rf.persister.Save(rf.encodeState(), args.Data)
snapshot 不能在持有锁的情况下直接发送到 applyCh(会死锁),也不能在释放锁后直接发送(可能与 applier 的 entry 发送乱序)。解决方案是引入 pendingSnapshot 字段,将 snapshot 消息暂存,由 applier goroutine 统一处理。applier 每次醒来优先检查 pendingSnapshot,有则先发送 snapshot 再处理 entry,保证 snapshot 和 entry 的顺序性。
func (rf *Raft) applier() {
for true {
rf.mu.Lock()
for rf.pendingSnapshot == nil && rf.lastApplied >= rf.commitIndex {
rf.applyCond.Wait()
}
// Drain pending snapshot first to guarantee ordering with command entries
if rf.pendingSnapshot != nil {
msg := *rf.pendingSnapshot
rf.pendingSnapshot = nil
rf.mu.Unlock()
rf.applyCh <- msg
continue
}
commitIndex, lastApplied := rf.commitIndex, rf.lastApplied // save commitIndex to avoid race condition
// Guard: entries may have been trimmed by a concurrent InstallSnapshot
if lastApplied+1 <= rf.lastSnapshotEntry().Index {
rf.mu.Unlock()
continue
}
entries := make([]LogEntry, commitIndex-lastApplied)
copy(entries, rf.log[rf.logIndex(lastApplied+1):rf.logIndex(commitIndex)+1])
rf.mu.Unlock()
// ... send entries to applyCh
}
}
Pretty Debug Log
分布式系统的调试难点在于多个 goroutine 并发输出的日志混在一起,时序关系难以辨认。MIT 6.824 助教写的 Debugging by Pretty Printing 给出了一套优雅的解决方案:在 Go 侧为每条日志打上时间戳和 topic 标签,再用 Python 脚本按 topic 着色、按 peer 分列展示,让多节点的并发行为一目了然。
Go 侧的核心是一个替代 log.Printf 的 Debug 函数。它读取环境变量 VERBOSE 决定是否输出,时间戳以毫秒为单位(取 microseconds / 100),格式固定为 时间戳 TOPIC 消息,方便 Python 脚本解析。topic 用字符串常量枚举,覆盖计时器、投票、日志复制、提交、apply、snapshot、持久化等各个子系统,调试时可以按需过滤。
type logTopic string
const (
dTimer logTopic = "TIMR"
dVote logTopic = "VOTE"
dLeader logTopic = "LEAD"
dLog logTopic = "LOG1"
dLog2 logTopic = "LOG2"
dCommit logTopic = "CMIT"
dApply logTopic = "APLY"
dSnap logTopic = "SNAP"
dPersist logTopic = "PERS"
dError logTopic = "ERRO"
dWarn logTopic = "WARN"
)
var debugStart time.Time
var debugVerbosity int
func init() {
debugVerbosity = getVerbosity()
debugStart = time.Now()
log.SetFlags(log.Flags() &^ (log.Ldate | log.Ltime))
}
func Debug(topic logTopic, format string, a ...interface{}) {
if debugVerbosity >= 1 {
ms := time.Since(debugStart).Microseconds() / 100
prefix := fmt.Sprintf("%06d %v ", ms, string(topic))
log.Printf(prefix+format, a...)
}
}
Python 脚本 dslogs.py 负责将 raw log 转化为可读的彩色输出。它依赖 rich 和 typer 两个库,核心逻辑是逐行解析日志,提取时间戳、topic 和消息体,根据 topic 映射到对应颜色,再通过 rich.columns.Columns 将不同 peer 的日志分列对齐。-c N 参数指定列数(即 peer 数),-j TOPIC 只显示指定 topic,-i TOPIC 忽略指定 topic,非常适合在定位问题时聚焦某个子系统。
# fmt: off
# Mapping from topics to colors
TOPICS = {
"TIMR": "#9a9a99",
"VOTE": "#67a0b2",
"LEAD": "#d0b343",
"LOG1": "#4878bc",
"LOG2": "#398280",
"CMIT": "#98719f",
"APLY": "#00813c",
"SNAP": "#FD971F",
"PERS": "#d08341",
"ERRO": "#fe2626",
"WARN": "#d08341",
}
# fmt: on
def main(...):
# We can take input from a stdin (pipes) or from a file
input_ = file if file else sys.stdin
# Print just some topics or exclude some topics (good for avoiding verbose ones)
# ...
panic = False
for line in input_:
try:
time, topic, *msg = line.strip().split(" ")
if topic not in topics:
continue
msg = " ".join(msg)
# Debug calls from the test suite aren't associated with
# any particular peer. Otherwise we can treat second column
# as peer id
i = int(msg[1])
# Colorize output by using rich syntax when needed
if colorize and topic in TOPICS:
color = TOPICS[topic]
msg = f"[{color}]{msg}[/{color}]"
# Single column printing. Always the case for debug stmts in tests
if n_columns is None:
print(time, msg)
# Multi column printing, timing is dropped to maximize horizontal
# space. Heavylifting is done through rich.column.Columns object
else:
cols = ["" for _ in range(n_columns)]
cols[i] = msg
col_width = int(width / n_columns)
cols = Columns(cols, width=col_width - 1, equal=True, expand=True)
print(cols)
except:
# Code from tests or panics does not follow format
# so we print it as is
if line.startswith("panic"):
panic = True
# Output from tests is usually important so add a
# horizontal line with hashes to make it more obvious
if not panic:
print("#" * console.width)
print(line, end="")
使用方式是先设置 VERBOSE=1 运行测试并将输出重定向到文件,再用脚本处理,例如:
# 基本用法(3 节点,按列显示)
VERBOSE=1 go test -run TestSnapshotInstall3D -count=1 2>&1 | python3 dslogs.py -c 3
# 只看快照和 commit 相关
VERBOSE=1 go test -run TestSnapshotInstall3D -count=1 2>&1 | python3 dslogs.py -c 3 -j SNAP,CMIT
# 过滤掉心跳噪音
VERBOSE=1 go test -run TestSnapshotInstall3D -count=1 2>&1 | python3 dslogs.py -c 3 -i TIMR
# 我的使用办法,先把日志保存到文件,再用脚本分析
VERBOSE=1 go test -v -race -run TestSnapshotInstallUnreliable3D -count=10 -timeout 24h 2>&1 | tee TestSnapshotInstallUnreliable3D.log
python3 dslogs.py -c 3 ./TestSnapshotInstallUnreliable3D.log
测试
5.14 晚上首次通过:
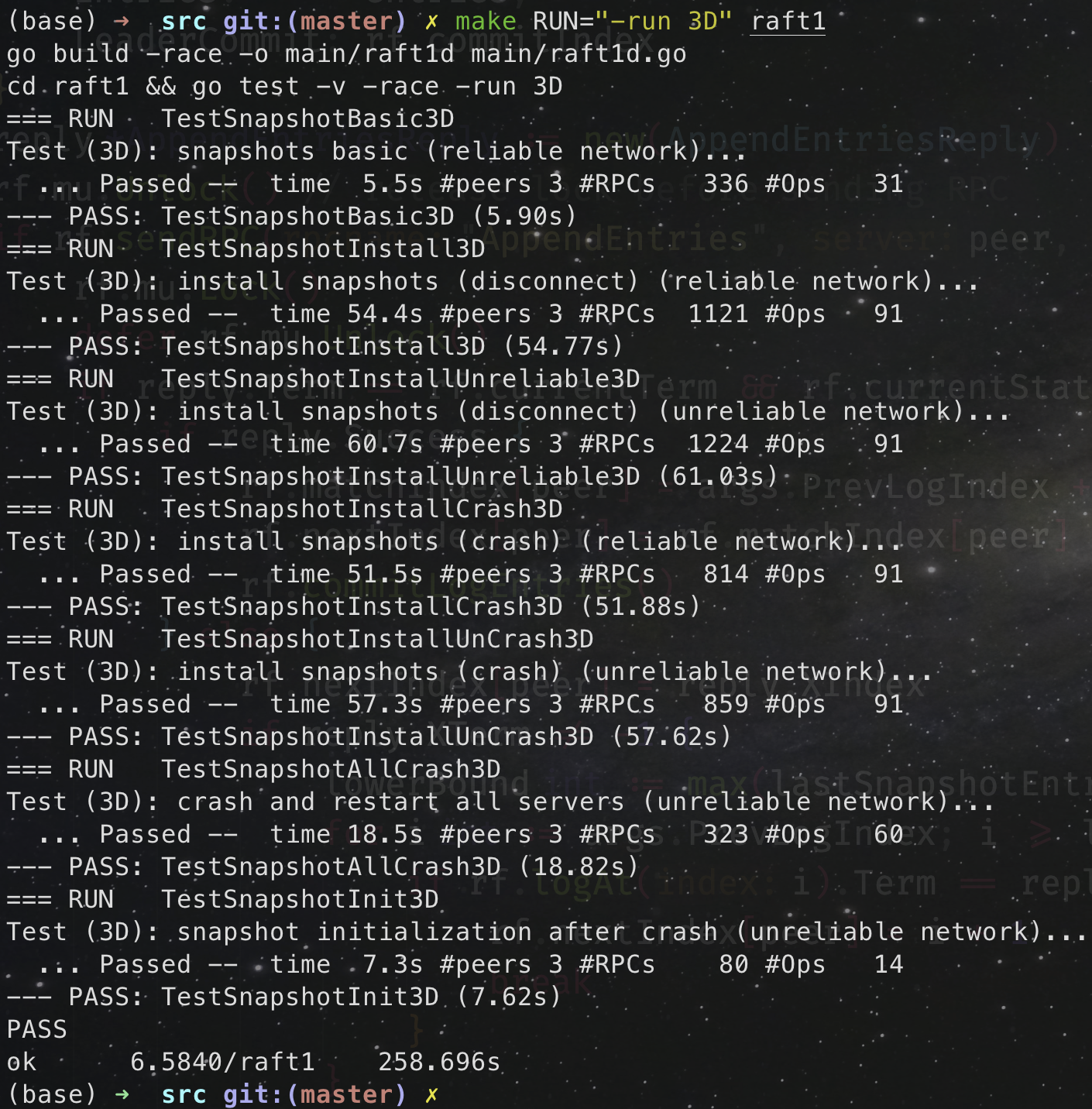
5.17 跑了一晚上 100+ 轮没有 FAIL,总算是通过了

References
DDIA 作者 Martin Kleppmann 讲分布式系统
