先吐槽一下 ,cow lab 后看了 4 节课 + 3 章节 textbook 才能开始完成 lab,因此这个 Lab 看课和看 textbook 花费的时间比较多。这个 lab 是比较水的,本以为会自己实现内核的多进程/多线程机制,但 xv6 已经实现好了 RR 算法。而这个 lab 的三个 task 竟然都是在用户态下完成的,所以比较水了。
Lab6
Uthread: switching between threads
实现用户态下的多线程调度。
Hint 已经提示我们了,和内核里的 context switch 一样,只需要报存 callee-saved 寄存器即可。因为这是正常的函数调用,switch 后一段时间后还会返回当前函数的调用栈,剩下的 caller-saved 寄存器,编译器会自动生成恰当的汇编代码帮你保存在栈上。
这部分没有什么难度,把 xv6 中切换的代码抄过来即可。
直接借用内核中定义的 struct context 结构,添加在 struct thread 里,
struct thread {
struct context context; /* context for thread_switch */
char stack[STACK_SIZE]; /* the thread's stack */
int state; /* FREE, RUNNING, RUNNABLE */
};
完整代码如下:
diff --git a/user/uthread.c b/user/uthread.c
index 18b773d..63d19e4 100644
--- a/user/uthread.c
+++ b/user/uthread.c
@@ -1,5 +1,9 @@
#include "kernel/types.h"
#include "kernel/stat.h"
+#include "kernel/param.h"
+#include "kernel/riscv.h"
+#include "kernel/spinlock.h"
+#include "kernel/proc.h"
#include "user/user.h"
/* Possible states of a thread: */
@@ -12,6 +16,7 @@
struct thread {
+ struct context context; /* context for thread_switch */
char stack[STACK_SIZE]; /* the thread's stack */
int state; /* FREE, RUNNING, RUNNABLE */
};
@@ -60,6 +65,7 @@ thread_schedule(void)
* Invoke thread_switch to switch from t to next_thread:
* thread_switch(??, ??);
*/
+ thread_switch((uint64)&t->context, (uint64)&next_thread->context);
} else
next_thread = 0;
}
@@ -74,6 +80,9 @@ thread_create(void (*func)())
}
t->state = RUNNABLE;
// YOUR CODE HERE
+ memset(&t->context, 0, sizeof(t->context));
+ t->context.ra = (uint64)func;
+ t->context.sp = (uint64)(t->stack + STACK_SIZE);
}
void
diff --git a/user/uthread_switch.S b/user/uthread_switch.S
index 5defb12..94c4810 100644
--- a/user/uthread_switch.S
+++ b/user/uthread_switch.S
@@ -8,4 +8,34 @@
.globl thread_switch
thread_switch:
/* YOUR CODE HERE */
+ sd ra, 0(a0)
+ sd sp, 8(a0)
+ sd s0, 16(a0)
+ sd s1, 24(a0)
+ sd s2, 32(a0)
+ sd s3, 40(a0)
+ sd s4, 48(a0)
+ sd s5, 56(a0)
+ sd s6, 64(a0)
+ sd s7, 72(a0)
+ sd s8, 80(a0)
+ sd s9, 88(a0)
+ sd s10, 96(a0)
+ sd s11, 104(a0)
+
+ ld ra, 0(a1)
+ ld sp, 8(a1)
+ ld s0, 16(a1)
+ ld s1, 24(a1)
+ ld s2, 32(a1)
+ ld s3, 40(a1)
+ ld s4, 48(a1)
+ ld s5, 56(a1)
+ ld s6, 64(a1)
+ ld s7, 72(a1)
+ ld s8, 80(a1)
+ ld s9, 88(a1)
+ ld s10, 96(a1)
+ ld s11, 104(a1)
+
ret /* return to ra */
Using threads
这个 lab 让我们使用 UNIX pthread threading library 来加速一个多线程的哈希表程序,并且最终提速比要在 1.25 倍以上。
真就梦回大二下学校课程的 OS 实验了,学校里的 OS 实验课就相当于 xv6 的 lab1 和 lab6 的部分任务,只是浅浅学下如何调用 OS 的 API,但是背后的实现原理和细节都不知道。
这个 task 没有任何难度,直接放代码了(甚至代码也少得可怜):
diff --git a/notxv6/ph.c b/notxv6/ph.c
index 82afe76..a08ed37 100644
--- a/notxv6/ph.c
+++ b/notxv6/ph.c
@@ -14,6 +14,7 @@ struct entry {
struct entry *next;
};
struct entry *table[NBUCKET];
+pthread_mutex_t lock[NBUCKET];
int keys[NKEYS];
int nthread = 1;
@@ -52,7 +53,9 @@ void put(int key, int value)
e->value = value;
} else {
// the new is new.
+ pthread_mutex_lock(&lock[i]);
insert(key, value, &table[i], table[i]);
+ pthread_mutex_unlock(&lock[i]);
}
}
@@ -118,6 +121,10 @@ main(int argc, char *argv[])
keys[i] = random();
}
+ for (int i = 0; i < NBUCKET; ++i) {
+ pthread_mutex_init(&lock[i], NULL);
+ }
+
//
// first the puts
//
Barrier
这个 task 要求我们实现一个多线程的同步屏障(barrier),注意不是内存屏障。也就是说,在多线程的循环中,每一次循环都会在 barrier 同步一下进度。我们需要通过 pthread 提供的条件变量唤醒机制来实现。(感谢 xv6 的课程,让我对 sleep 和 wake 有了更深刻的理解,明白了为什么条件变量和唤醒需要 lock)
barrier 对象的结构如下:
struct barrier {
pthread_mutex_t barrier_mutex;
pthread_cond_t barrier_cond;
int nthread; // Number of threads that have reached this round of the barrier
int round; // Barrier round
} bstate;
nthread 用于计数,当前 round 已经到达 barrier 的线程数;round 用于表示当前是第几轮。
关于 pthread_cond_t 的简单使用示例如下:
pthread_cond_wait(&cond, &mutex); // go to sleep on cond, releasing lock mutex, acquiring upon wake up
pthread_cond_broadcast(&cond); // wake up every thread sleeping on cond
这其中稍微麻烦的是存在一个竞争:先从 barrier 里出来的线程可能会很快再次进入 barrier,此时可能还有线程还未完全从 cond_wait 中唤醒(虽然已经被 broadcast 唤醒了,但是还需要争抢到 mutex 才会继续执行后面的代码),所以这时它们都会去争抢 mutex。如果这时候 bstate.nthread 使用不当就会造成错误。
我思考了一会,该如何区分当前 round 还未从 barrier 里出去的线程,和出去后已经再次进入下一轮 barrier 的线程?同时我的实现不能依赖于外部的 round 变量,这样破坏了封装性。
我们可以通过 bstate.nthread 的正负来表示当前 round 的 barrier 状态:
bstate.nthread >= 0:表示当前正在等待所有线程进入 barrier,bstate.nthread代表已经进入 barrier 的线程数bstate.nthread < 0:表示当前轮所有线程已经进入 barrier,正在等待线程全部离开 barrier,bstate.nthread的绝对值代表当且还未离开 barrier 的线程数
自我感觉这个实现还是比较巧妙的,一变量多用,实现代码如下:
static void
barrier()
{
// YOUR CODE HERE
//
// Block until all threads have called barrier() and
// then increment bstate.round.
//
pthread_mutex_lock(&bstate.barrier_mutex);
if (bstate.nthread < 0)
pthread_cond_wait(&bstate.barrier_cond, &bstate.barrier_mutex);
++bstate.nthread;
if (bstate.nthread < nthread) {
pthread_cond_wait(&bstate.barrier_cond, &bstate.barrier_mutex);
} else {
bstate.nthread = -bstate.nthread;
++bstate.round;
pthread_cond_broadcast(&bstate.barrier_cond);
}
++bstate.nthread;
if (bstate.nthread == 0)
pthread_cond_broadcast(&bstate.barrier_cond);
pthread_mutex_unlock(&bstate.barrier_mutex);
}
不过上述通过正负区分是多此一举,实际上代码可以更简单。因为我们用 if 来 wrap 的pthread_cond_wait,而不是用的 while,因此后苏醒的线程不会(也不需要)再去检查条件 bstate.nthread < nthread,不需要是因为唤醒后一定是满足条件的。
更简单的代码如下:
static void
barrier()
{
// YOUR CODE HERE
//
// Block until all threads have called barrier() and
// then increment bstate.round.
//
pthread_mutex_lock(&bstate.barrier_mutex);
++bstate.nthread;
if (bstate.nthread < nthread) {
pthread_cond_wait(&bstate.barrier_cond, &bstate.barrier_mutex);
} else {
bstate.nthread = 0;
++bstate.round;
pthread_cond_broadcast(&bstate.barrier_cond);
}
pthread_mutex_unlock(&bstate.barrier_mutex);
}
测试
Xv6 Book Chapter
因为这个 lab 读了三节的 textbook,这里就有三节的笔记摘录。
Xv6 Book Chapter 5
This code configures the UART to generate a receive interrupt when the UART receives each byte of input, and a transmit complete interrupt each time the UART finishes sending a byte of output.(即 Each time the UART finishes sending a byte, it generates an interrupt.)
Thus if a process writes multiple bytes to the console, typically the first byte will be sent by uartputc’s call to uartstart, and the remaining buffered bytes will be sent by uartstart calls from uartintr as transmit complete interrupts arrive.
RISC-V requires that timer interrupts be taken in machine mode, not supervisor mode. As a result, xv6 handles timer interrupts completely separately from the trap mechanism laid out above.
There’s no way for the kernel to disable timer interrupts during critical operations. (即 A timer interrupt can occur at any point when user or kernel code is executing)
The machine-mode timer interrupt handler is timervec (kernel/kernelvec.S:95). It saves a few registers in the scratch area prepared by start, tells the CLINT when to generate the next timer interrupt, asks the RISC-V to raise a software interrupt, restores registers, and returns. There’s no C code in the timer interrupt handler.
Timer interrupts force a thread switch (a call to yield) from the timer interrupt handler, even when executing in the kernel.
However, the need for kernel code to be mindful that it might be suspended (due to a timer interrupt) and later resume on a different CPU is the source of some complexity in xv6 (see Section 6.6).
In many operating systems, the drivers account for more code than the core kernel.
高速设备对于中断的优化处理办法:One trick is to raise a single interrupt for a whole batch of incoming or outgoing requests. Another trick is for the driver to disable interrupts entirely, and to check the device periodically to see if it needs attention.
Applications may want to control aspects of a device that cannot be expressed through the standard file system calls (e.g., enabling/disabling line buffering in the console driver). Unix operating systems support the ioctl system call for such cases.
Xv6 Book Chapter 6
Although locks are an easy-to-understand concurrency control mechanism, the downside of locks is that they can limit performance, because they serialize concurrent operations.
In the list example, a kernel may maintain a separate free list per CPU and only touch another CPU’s free list if the current CPU’s list is empty and it must steal memory from another CPU.
Xv6 has two types of locks: spinlocks and sleep-locks.
Xv6’s acquire (kernel/spinlock.c:22) uses the portable C library call __sync_lock_test_and_set, which boils down to the amoswap instruction.
The C standard allows compilers to implement an assignment with multiple store instructions, so a C assignment might be non-atomic with respect to concurrent code. Instead, release uses the C library function __sync_lock_release that performs an atomic assignment.

It might appear that some deadlocks and lock-ordering challenges could be avoided by using re-entrant locks, which are also called recursive locks.
Re-entrant locks break the intuition that locks cause critical sections to be atomic with respect to other critical sections.
解决锁与中断导致的死锁问题:To avoid this situation, if a spinlock is used by an interrupt handler, a CPU must never hold that lock with interrupts enabled. Xv6 is more conservative: when a CPU acquires any lock, xv6 always disables interrupts on that CPU.
One reason is that compilers emit load and store instructions in orders different from those implied by the source code, and may entirely omit them (for example by caching data in registers).(编译期指令乱序) Another reason is that the CPU may execute instructions out of order to increase performance.(运行时乱序发射)
__sync_synchronize() is a memory barrier: it tells the compiler and CPU to not reorder loads or stores across the barrier.
We’d like a type of lock that yields the CPU while waiting to acquire, and allows yields (and interrupts) while the lock is held. (睡眠锁)
Because sleep-locks leave interrupts enabled, they cannot be used in interrupt handlers.
It is possible to implement locks without atomic instructions [10](不用原子指令能实现自旋锁?后面有空看看), but it is expensive, and most operating systems use atomic instructions.([10] L Lamport. A new solution of dijkstra’s concurrent programming problem. Communications of the ACM, 1974.)
Lock-free programming is more complicated, however, than programming locks.
Xv6 Book Chapter 7
Xv6 内核的调度实现很巧妙,每个处理器有一个 scheduler thread。线程切换时,当前 kthread 先切换到 scheduler thread,再经过选择能调度的线程,切换到另一个 kthread。在这个过程中,线程本身锁的获取和释放也是交替的,yield获取的锁会在 scheduler 里释放,scheduler 里获取的锁会在 yield 里释放。
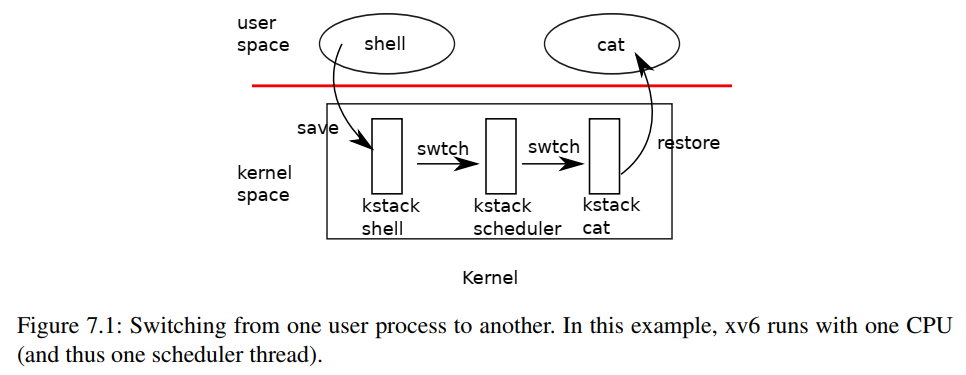
swtch (kernel/swtch.S:3) saves only callee-saved registers; the C compiler generates code in the caller to save caller-saved registers on the stack.
It does not save the program counter. Instead, swtch saves the ra register, which holds the return address from which swtch was called.
Procedures that intentionally transfer control to each other via thread switch are sometimes referred to as coroutines; in this example, sched and scheduler are co-routines of each other. (协程)
Xv6 ensures that each CPU’s hartid is stored in that CPU’s tp register while in the kernel. The compiler guarantees never to use the tp register.
解决获取 CPU id 时线程在 CPU 间发生迁移的问题:To avoid this problem, xv6 requires that callers disable interrupts, and only enable them after they finish using the returned struct cpu.
Sleep and wakeup are often called sequence coordination or conditional synchronization mechanisms.
It’s important that wakeup is called while holding the condition lock. [Strictly speaking it is sufficient if wakeup merely follows the acquire (that is, one could call wakeup after the release). ]
The other processes will find that, despite being woken up, there is no data to be read. From their point of view the wakeup was “spurious,” and they must sleep again. For this reason sleep is always called inside a loop that checks the condition.
Wait starts by acquiring wait_lock (kernel/proc.c:391). The reason is that wait_lock acts as the condition lock that helps ensure that the parent doesn’t miss a wakeup from an exiting child.
Thus kill does very little: it just sets the victim’s p->killed and, if it is sleeping, wakes it up.
Some xv6 sleep loops do not check p->killed because the code is in the middle of a multistep system call that should be atomic.
The p->parent field is protected by the global lock wait_lock rather than by p->lock. Only a process’s parent modifies p->parent, though the field is read both by the process itself and by other processes searching for their children.
The xv6 scheduler implements a simple scheduling policy, which runs each process in turn. This policy is called round robin.
In addition, complex policies may lead to unintended interactions such as priority inversion and convoys.
The Linux kernel’s sleep uses an explicit process queue, called a wait queue, instead of a wait channel; the queue has its own internal lock.
The operating system will schedule all these processes and they will race to check the sleep condition. Processes that behave in this way are sometimes called a thundering herd, and it is best avoided. (惊群效应)
