Lab4 需要进一步学习 RISC-V 汇编,并对 RISC-V 下的栈帧、用户程序状态保存与状态恢复会有更深入的学习和了解。在开始 Lab4 之前,需要阅读和调试 kernel/trampoline.S 和 kernel/trap.c。
RSIC-V Calling Convention
目前最新版的 RISC-V 的 privileged 和 unprivileged 文档中均已经移除了Calling Convention 这部分,这部分内容已经转移到了 RISC-V ELF psABI Specification。下面是 MIT6.1810 课程提供的 RSIC-V Calling Convention 阅读材料部分内容摘要,仅记录笔者觉得 make sense 或者有用或者自己不太熟悉的部分:
值得注意的是 char 和 unsigned char 类型均是 zero-extended 的,即 char 等于 unsigned char 而不是 signed char。

栈向下生长,并且栈指针总是保持 16-byte 对齐。
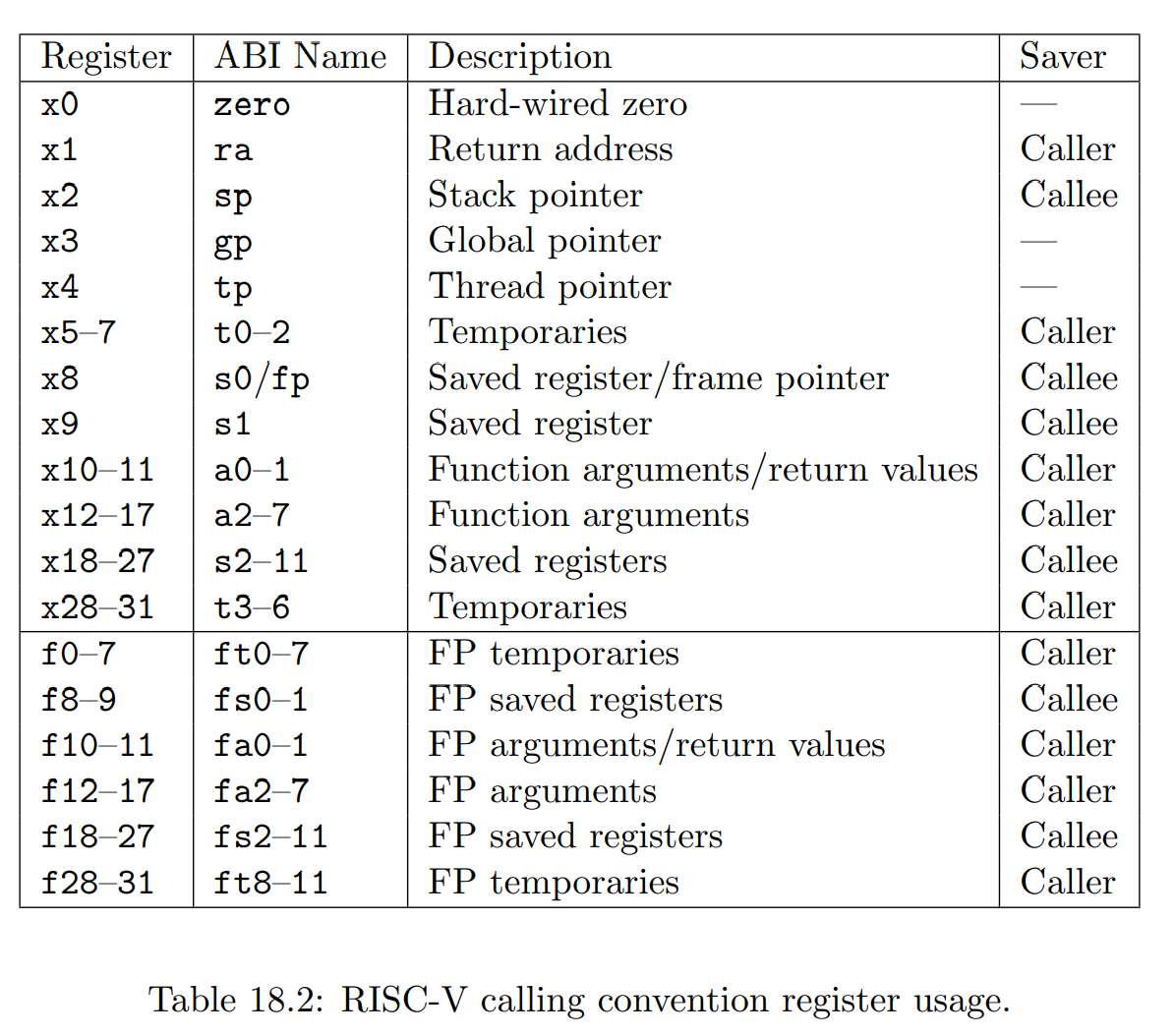
下图是 Caller saved 和 Callee saved 寄存器。值得注意的是 x0 寄存器恒为 0。
补充Stack Frame 示意图:
.
.
+-> .
| +-----------------+ |
| | return address | |
| | previous fp ------+
| | saved registers |
| | local variables |
| | ... | <-+
| +-----------------+ |
| | return address | |
+------ previous fp | |
| saved registers | |
| local variables | |
+-> | ... | |
| +-----------------+ |
| | return address | |
| | previous fp ------+
| | saved registers |
| | local variables |
| | ... | <-+
| +-----------------+ |
| | return address | |
+------ previous fp | |
| saved registers | |
| local variables | |
$fp --> | ... | |
+-----------------+ |
| return address | |
| previous fp ------+
| saved registers |
$sp --> | local variables |
+-----------------+
RISC-V Privileged
这个 Lab 中会涉及到几个和 RISC-V 相关的特权寄存器。在完成 Lab 的过程中时不时需要翻看 riscv-privileged 手册学习,我把这个 Lab 涉及到的相关特权寄存器介绍放在这里。
sscratch

sscratch 是一个供 S-Mode 使用的寄存器,通常用来在处理 trap 时存储信息。执行用户代码时,sscratch 常用于存储指向与当前硬件线程(hart)相关的监督模式上下文的指针。在发生 trap 时,sscratch 的内容会被用于帮助陷阱处理器执行处理。当发生 trap 进入 S-Mode 时,trap 处理程序通常需要用一个寄存器来保存处理器的上下文,以便后续恢复。这时候 sscratch 常用来作为初始的“交换寄存器”,用于与用户寄存器的数据交换。
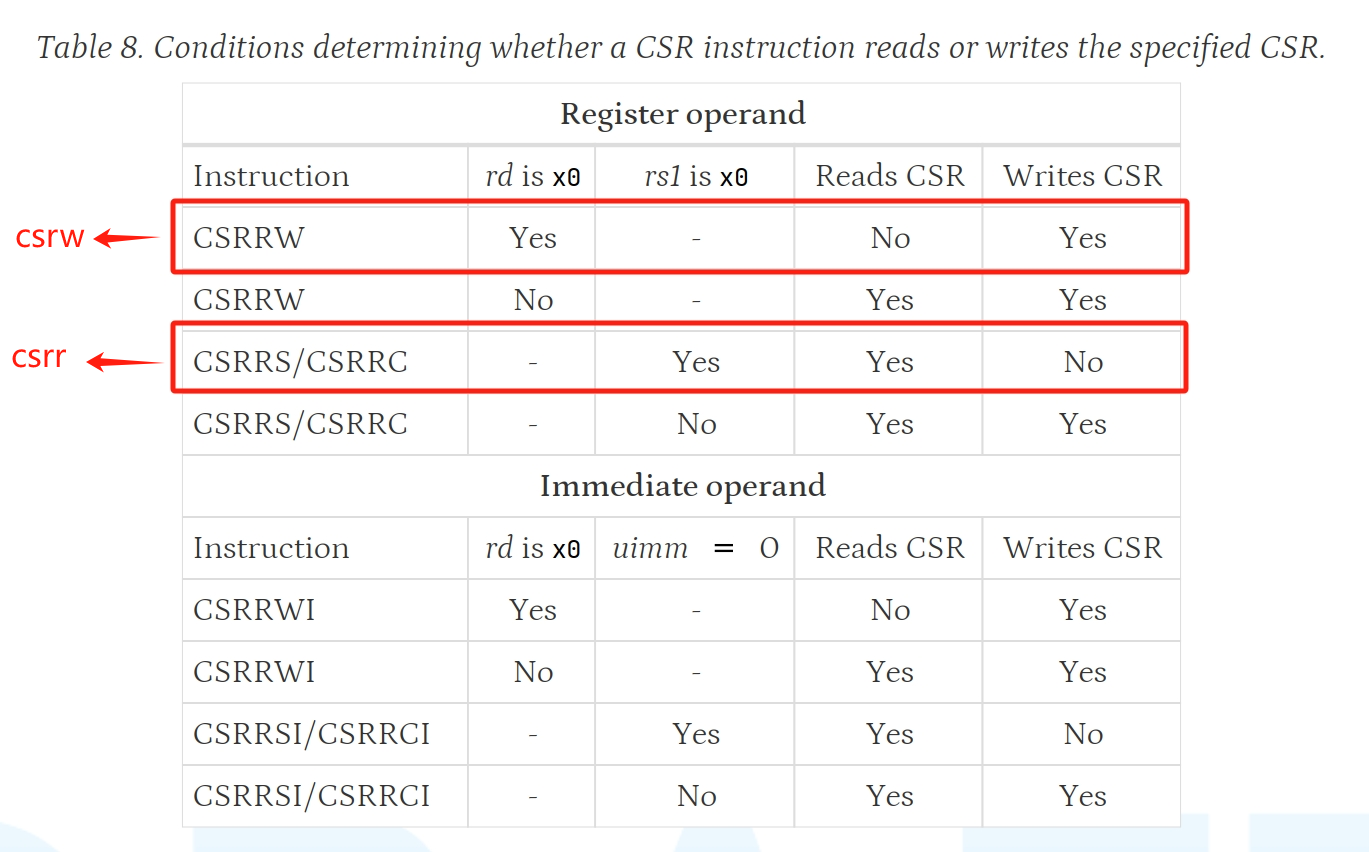
csrw 与 csrr
在 RISC-V 手册中,我们不能直接找到 csrw 与 csrr 两条指令,实际上根据 RISC-V Unprivileged 手册,这两条指令是汇编伪指令(assembler pseudoinstruction),与之对应的指令应该是 CSRRW 和 CSRRS。这两条指令的介绍如下:
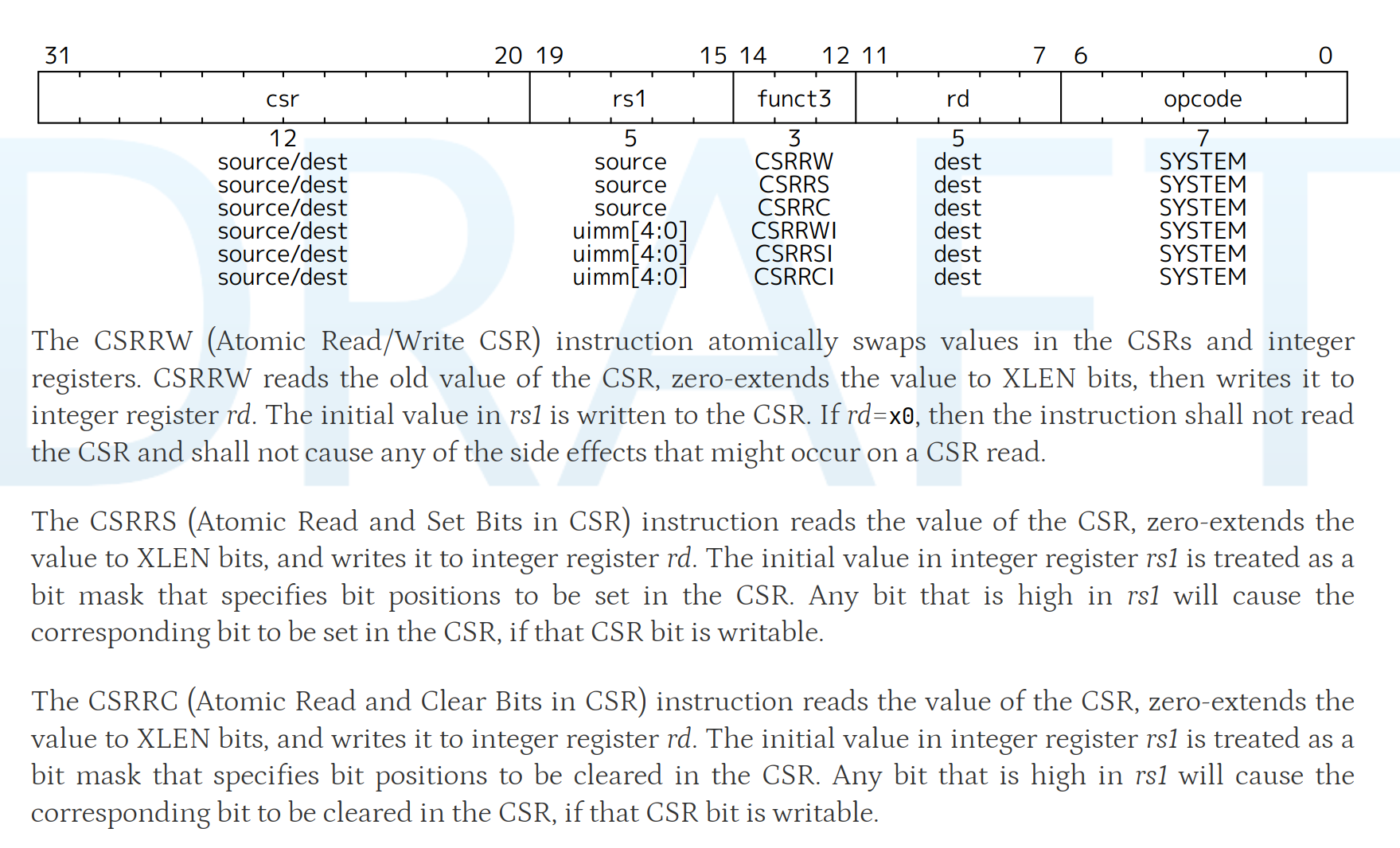
CSRRW 的全称是 Atomic Read/Write CSR,用于原子地读写控制状态寄存器和整数寄存器之间的数据。它的主要功能是读 CSR 的原始值:将指定 CSR 的当前值读取,并将其扩展为 XLEN 位,然后写入整数寄存器 rd。写入新值:将整数寄存器 rs1 中的值写入到指定的 CSR 中。如果目的寄存器 rd 为 x0,则意味着只执行写操作而不需要读取 CSR 的原始值,也不会产生读取的副作用。
CSRRS 的全称是 Atomic Read and Set Bits in CSR,用于原子地读取控制状态寄存器,并将寄存器中的某些位设置为 1。它的主要功能是读 CSR 的当前值:读取指定的 CSR 值,并将其扩展为 XLEN 位,然后写入整数寄存器 rd。设置 CSR 的某些位:rs1 寄存器中的值作为一个位掩码(bitmask),用于指定需要设置的位。rs1 中的每个高位会使得对应位置的 CSR 位被设置为 1。如果源寄存器 rs1 为 x0,则不会对 CSR 进行修改,仅执行读操作。
csrw、csrr 是 CSRRW、CSRRS 指令的特殊情况,具体见下图,

Lab4
RISC-V assembly
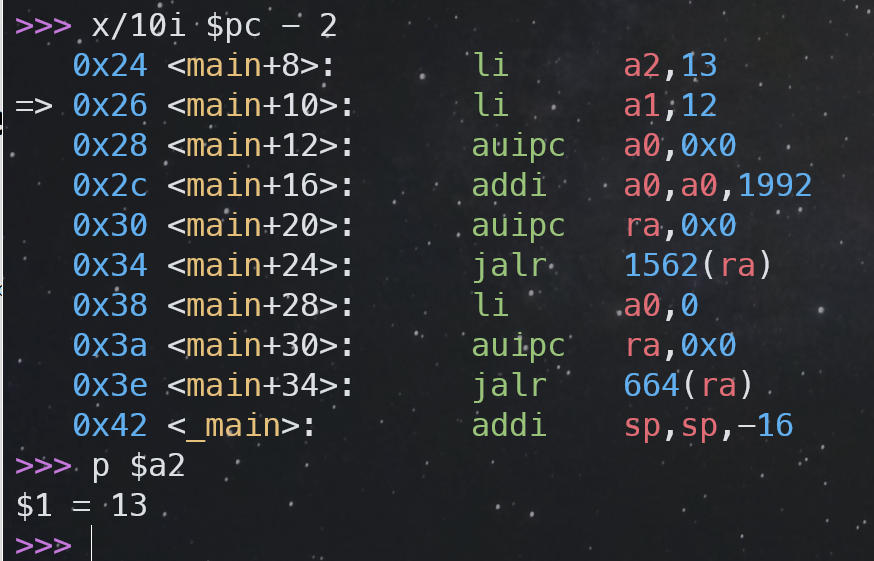
- [x] Which registers contain arguments to functions? For example, which register holds 13 in main’s call to
printf?a1里存 12(第一个参数),a2里存 13(第二个参数),a1、a2包含函数参数。
-
[x] Where is the call to function
fin the assembly code for main? Where is the call tog? (Hint: the compiler may inline functions.)f和g的调用参数由于都是编译期常数,都被编译器直接计算了,a1里存的 12 就是f(8)+1的计算结果。 -
[x] At what address is the function
printflocated?0x64a。 -
[x] What value is in the register
rajust after thejalrtoprintfinmain?ra= 0x38。 -
[x] Run the following code.
unsigned int i = 0x00646c72; printf("H%x Wo%s", 57616, &i);What is the output? Here’s an ASCII table that maps bytes to characters.
The output depends on that fact that the RISC-V is little-endian. If the RISC-V were instead big-endian what would you set
ito in order to yield the same output? Would you need to change57616to a different value? Here’s a description of little- and big-endian and a more whimsical description.如果是大端序,需要把
i修改为0x726c6400,57616不需要修改。 -
[x] In the following code, what is going to be printed after
'y='? (note: the answer is not a specific value.) Why does this happen?printf("x=%d y=%d", 3);y 会打印
a2的值,因为a2是第三个函数传入参数。
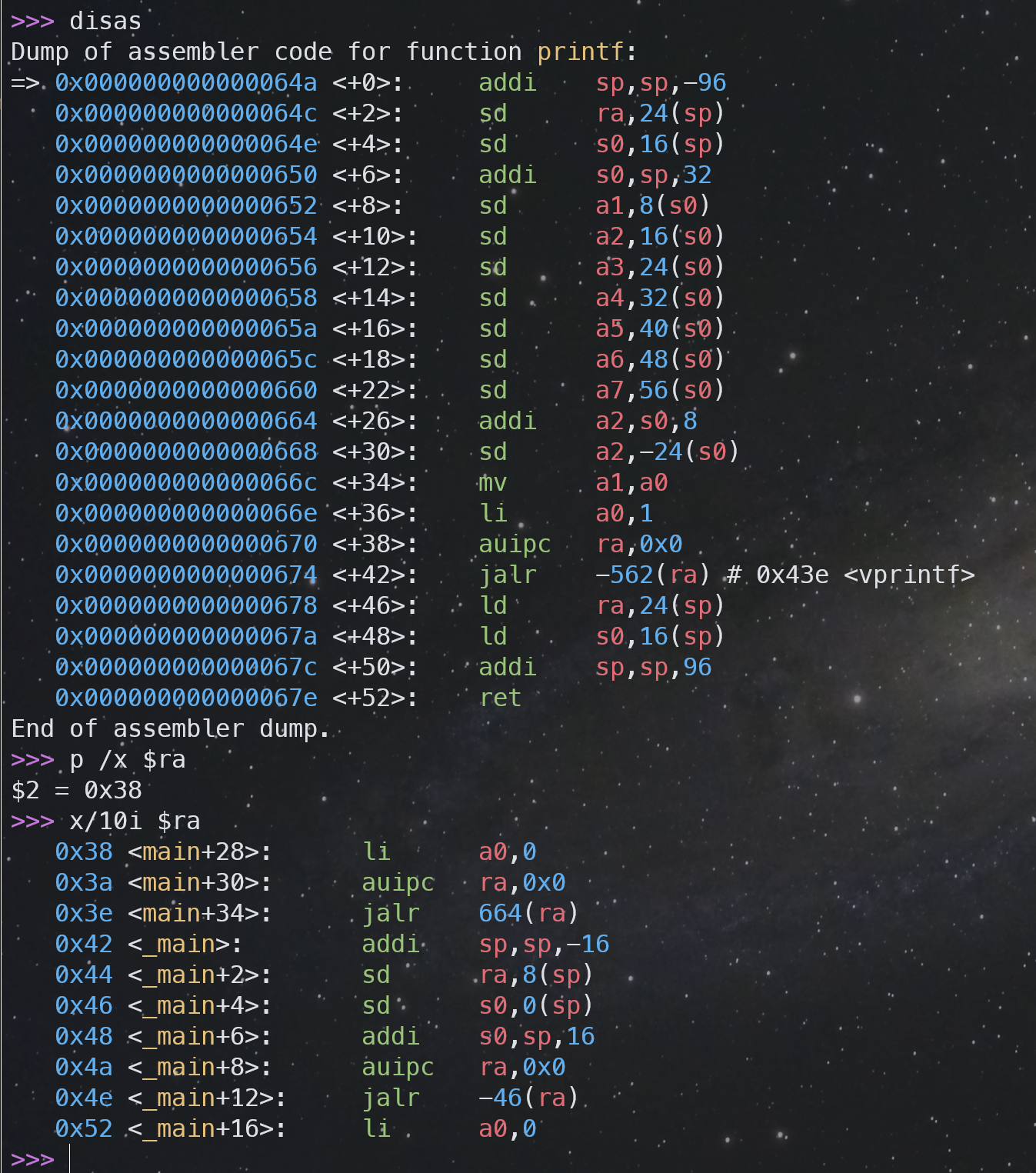
Backtrace
backtrace 查看栈帧是调试非常好用的技巧。关于 RISC-V 的栈帧结构,请查看前文 RSIC-V Calling Convention 部分有栈帧示意图。在完成这个 task 之前,我先使用 gdb 调试程序,通过人脑观察内存数据来学习认识 RISC-V 架构下的栈帧:
在我下面的例子中,当前 gdb 处于内核空间,该 process 的内核栈地址为于 [0x3fffff9000, 0x3fffffa000),高地址0x3fffffa000 为栈底,0x3fffff9000 为栈顶。
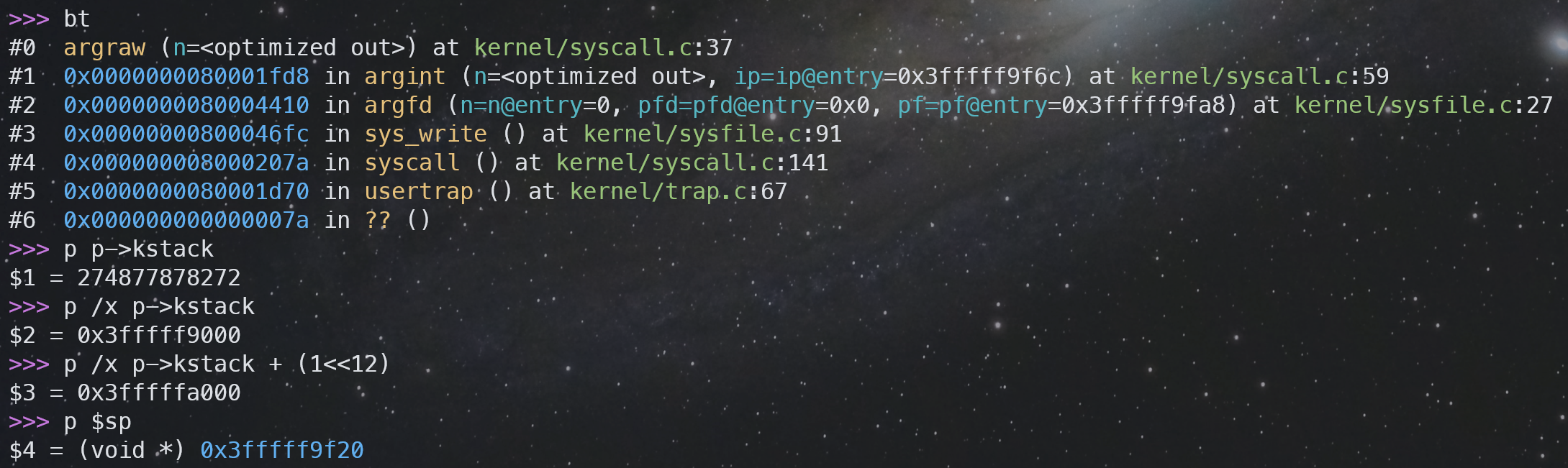
🌟 需要注意的是,RISC-V 中的 sp 指向的是最后一个已入栈元素的地址,而不是下一个入栈元素的位置,即是所谓的“满栈”。
RISC-V 中 fp 栈帧指针寄存器是 s0,通过 gdb 可以看到 fp 和 s0 它们的值是相等的。
当前 fp-8 的位置是返回地址,fp-16的位置是上一个栈帧的 fp,通过人脑模拟跳栈帧,我将跳栈帧的过程截图标注为下图,
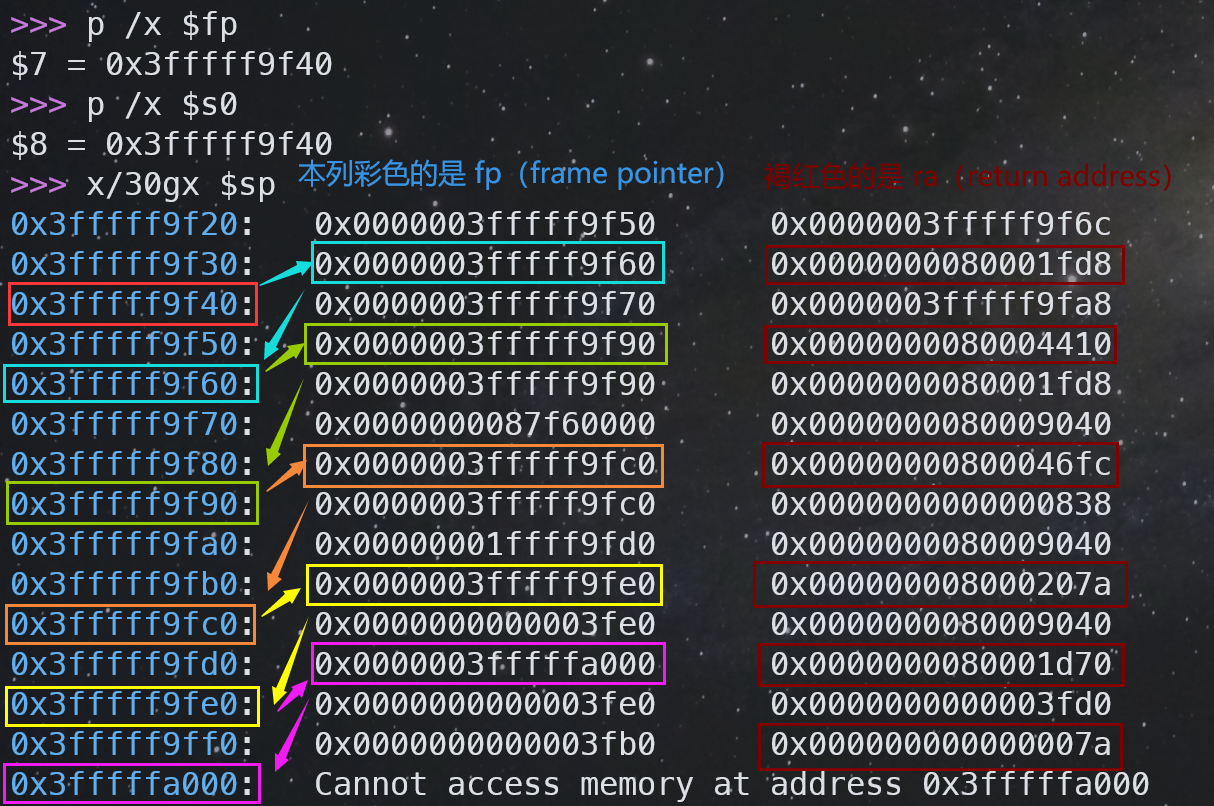
如何判断到达栈底?利用 Xv6 中栈仅位于一个 page 上的特性,当 fp 跳过当前 page 的时候,及时退出循环即可。
代码如下,实现难度不大:
diff --git a/kernel/defs.h b/kernel/defs.h
index a3c962b..4b82fc2 100644
--- a/kernel/defs.h
+++ b/kernel/defs.h
@@ -80,6 +80,7 @@ int pipewrite(struct pipe*, uint64, int);
void printf(char*, ...);
void panic(char*) __attribute__((noreturn));
void printfinit(void);
+void backtrace(void);
// proc.c
int cpuid(void);
diff --git a/kernel/printf.c b/kernel/printf.c
index 1a50203..8ff1e70 100644
--- a/kernel/printf.c
+++ b/kernel/printf.c
@@ -122,6 +122,7 @@ panic(char *s)
printf("panic: ");
printf(s);
printf("\n");
+ backtrace();
panicked = 1; // freeze uart output from other CPUs
for(;;)
;
@@ -133,3 +134,19 @@ printfinit(void)
initlock(&pr.lock, "pr");
pr.locking = 1;
}
+
+
+// Walk up the stack and print the saved
+// return address in each stack frame.
+void
+backtrace(void) {
+ uint64 fp, page_addr;
+
+ printf("backtrace:\n");
+ fp = r_fp();
+ page_addr = PGROUNDDOWN(fp);
+ while (PGROUNDDOWN(fp) == page_addr) {
+ printf("%p\n", *(uint64 *)(fp - 8));
+ fp = *(uint64 *)(fp - 16);
+ }
+}
\ No newline at end of file
diff --git a/kernel/riscv.h b/kernel/riscv.h
index 20a01db..516df7f 100644
--- a/kernel/riscv.h
+++ b/kernel/riscv.h
@@ -295,6 +295,14 @@ r_sp()
return x;
}
+static inline uint64
+r_fp()
+{
+ uint64 x;
+ asm volatile("mv %0, s0" : "=r" (x) );
+ return x;
+}
+
// read and write tp, the thread pointer, which xv6 uses to hold
// this core's hartid (core number), the index into cpus[].
static inline uint64
diff --git a/kernel/sysproc.c b/kernel/sysproc.c
index 3b4d5bd..8b87f68 100644
--- a/kernel/sysproc.c
+++ b/kernel/sysproc.c
@@ -54,6 +54,7 @@ sys_sleep(void)
int n;
uint ticks0;
+ backtrace();
argint(0, &n);
if(n < 0)
n = 0;
Alarm
在这个 task 中,你需要实现一个定时任务(有点 RTOS 的味道了😇)。因此一个用户程序的执行流可能变成这样:用户程序代码正在运行 ==> usertrap ==> 定时任务 A ==> (经过 sigreturn)usertrap ==> 用户程序代码恢复运行。在第二个 usertrap 时,定时任务 A 的 trapframe 会覆盖之前用户代码的 trapframe,因此为了保证用户代码能够恢复之前的执行流,我们需要一个额外的 trampframe 来保存状态。
在 struct proc 中增加如下字段:
// for sigalarm and sigreturn
int nr_ticks;
int remaining_ticks;
int in_alarm_handler;
void (*alarm_handler)();
struct trapframe *alarm_trapframe;
sys_sigalarm 的实现很简单,只需要设置相应的定时任务参数即可。需要注意的是,在任务任务里面再次调用 sys_sigalarm 是可以的,可以再调用 sys_sigalarm 来取消当前的定时任务,或者设置一个新的定时任务,都是 ok 的。代码如下:
// If an application calls sigalarm(n, fn),
// then after every n "ticks" of CPU time that the program consumes,
// the kernel should cause application function fn to be called.
uint64
sys_sigalarm(void) {
int ticks;
void (*handler)();
struct proc *p;
argint(0, &ticks);
argaddr(1, (uint64*)&handler);
p = myproc();
p->nr_ticks = ticks;
p->remaining_ticks = ticks;
p->alarm_handler = handler;
// It' ok to call sigalarm in an alarm handler,
// so current process can be in an alarm handler.
// if (p->in_alarm_handler)
// panic("sys_sigalarm: already in alarm handler");
return 0;
}
修改 usertrap 中 timer interrupt 处理部分的代码,保存 p->trapframe 的内容到 p->alarm_trapframe。
// give up the CPU if this is a timer interrupt.
if(which_dev == 2) {
if (p->nr_ticks > 0 && --p->remaining_ticks <= 0 && !p->in_alarm_handler) {
p->in_alarm_handler = 1;
p->remaining_ticks = p->nr_ticks;
*p->alarm_trapframe = *p->trapframe;
p->trapframe->epc = (uint64)p->alarm_handler;
} else {
yield();
}
}
在 sys_sigreturn 的时候,恢复 p->alarm_trapframe 的内容。同时需要注意的是,sys_sigreturn 的返回值会覆盖 a0 寄存器,因此我们将 sys_sigreturn 的返回值设为 p->trapframe->a0,这样就没有影响了。代码实现如下:
// User alarm handlers are required to call the
// sigreturn system call when they have finished.
uint64
sys_sigreturn(void) {
struct proc *p;
p = myproc();
if (!p->in_alarm_handler)
panic("sys_sigreturn: not in alarm handler");
p->in_alarm_handler = 0;
*p->trapframe = *p->alarm_trapframe;
return p->trapframe->a0;
}
整个 alarm task 的完整代码如下:
diff --git a/Makefile b/Makefile
index 473a471..f6c327b 100644
--- a/Makefile
+++ b/Makefile
@@ -188,6 +188,7 @@ UPROGS=\
$U/_grind\
$U/_wc\
$U/_zombie\
+ $U/_alarmtest\
diff --git a/kernel/proc.c b/kernel/proc.c
index 58a8a0b..8b5cb15 100644
--- a/kernel/proc.c
+++ b/kernel/proc.c
@@ -146,6 +146,16 @@ found:
p->context.ra = (uint64)forkret;
p->context.sp = p->kstack + PGSIZE;
+ if ((p->alarm_trapframe = (struct trapframe *)kalloc()) == 0) {
+ freeproc(p);
+ release(&p->lock);
+ return 0;
+ }
+ p->nr_ticks = 0;
+ p->remaining_ticks = 0;
+ p->in_alarm_handler = 0;
+ p->alarm_handler = 0;
+
return p;
}
@@ -160,6 +170,9 @@ freeproc(struct proc *p)
p->trapframe = 0;
if(p->pagetable)
proc_freepagetable(p->pagetable, p->sz);
+ if (p->alarm_trapframe)
+ kfree((void*)p->alarm_trapframe);
+ p->alarm_trapframe = 0;
p->pagetable = 0;
p->sz = 0;
p->pid = 0;
diff --git a/kernel/proc.h b/kernel/proc.h
index d021857..a5d01e1 100644
--- a/kernel/proc.h
+++ b/kernel/proc.h
@@ -104,4 +104,11 @@ struct proc {
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
+
+ // for sigalarm and sigreturn
+ int nr_ticks;
+ int remaining_ticks;
+ int in_alarm_handler;
+ void (*alarm_handler)();
+ struct trapframe *alarm_trapframe;
};
diff --git a/kernel/syscall.c b/kernel/syscall.c
index ed65409..c34b372 100644
--- a/kernel/syscall.c
+++ b/kernel/syscall.c
@@ -101,6 +101,8 @@ extern uint64 sys_unlink(void);
extern uint64 sys_link(void);
extern uint64 sys_mkdir(void);
extern uint64 sys_close(void);
+extern uint64 sys_sigalarm(void);
+extern uint64 sys_sigreturn(void);
// An array mapping syscall numbers from syscall.h
// to the function that handles the system call.
@@ -126,6 +128,8 @@ static uint64 (*syscalls[])(void) = {
[SYS_link] sys_link,
[SYS_mkdir] sys_mkdir,
[SYS_close] sys_close,
+[SYS_sigalarm] sys_sigalarm,
+[SYS_sigreturn] sys_sigreturn,
};
void
diff --git a/kernel/syscall.h b/kernel/syscall.h
index bc5f356..67ca3a4 100644
--- a/kernel/syscall.h
+++ b/kernel/syscall.h
@@ -20,3 +20,5 @@
#define SYS_link 19
#define SYS_mkdir 20
#define SYS_close 21
+#define SYS_sigalarm 22
+#define SYS_sigreturn 23
diff --git a/kernel/sysproc.c b/kernel/sysproc.c
index 8b87f68..ae0c82f 100644
--- a/kernel/sysproc.c
+++ b/kernel/sysproc.c
@@ -92,3 +92,42 @@ sys_uptime(void)
release(&tickslock);
return xticks;
}
+
+// If an application calls sigalarm(n, fn),
+// then after every n "ticks" of CPU time that the program consumes,
+// the kernel should cause application function fn to be called.
+uint64
+sys_sigalarm(void) {
+ int ticks;
+ void (*handler)();
+ struct proc *p;
+
+ argint(0, &ticks);
+ argaddr(1, (uint64*)&handler);
+
+ p = myproc();
+ p->nr_ticks = ticks;
+ p->remaining_ticks = ticks;
+ p->alarm_handler = handler;
+ // It' ok to call sigalarm in an alarm handler,
+ // so current process can be in an alarm handler.
+ // if (p->in_alarm_handler)
+ // panic("sys_sigalarm: already in alarm handler");
+
+ return 0;
+}
+
+// User alarm handlers are required to call the
+// sigreturn system call when they have finished.
+uint64
+sys_sigreturn(void) {
+ struct proc *p;
+
+ p = myproc();
+ if (!p->in_alarm_handler)
+ panic("sys_sigreturn: not in alarm handler");
+ p->in_alarm_handler = 0;
+ *p->trapframe = *p->alarm_trapframe;
+
+ return p->trapframe->a0;
+}
\ No newline at end of file
diff --git a/kernel/trap.c b/kernel/trap.c
index 512c850..66983d6 100644
--- a/kernel/trap.c
+++ b/kernel/trap.c
@@ -77,8 +77,16 @@ usertrap(void)
exit(-1);
// give up the CPU if this is a timer interrupt.
- if(which_dev == 2)
- yield();
+ if(which_dev == 2) {
+ if (p->nr_ticks > 0 && --p->remaining_ticks <= 0 && !p->in_alarm_handler) {
+ p->in_alarm_handler = 1;
+ p->remaining_ticks = p->nr_ticks;
+ *p->alarm_trapframe = *p->trapframe;
+ p->trapframe->epc = (uint64)p->alarm_handler;
+ } else {
+ yield();
+ }
+ }
usertrapret();
}
diff --git a/user/user.h b/user/user.h
index 4d398d5..9426153 100644
--- a/user/user.h
+++ b/user/user.h
@@ -22,6 +22,8 @@ int getpid(void);
char* sbrk(int);
int sleep(int);
int uptime(void);
+int sigalarm(int ticks, void (*handler)());
+int sigreturn(void);
// ulib.c
int stat(const char*, struct stat*);
diff --git a/user/usys.pl b/user/usys.pl
index 01e426e..fa548b0 100755
--- a/user/usys.pl
+++ b/user/usys.pl
@@ -36,3 +36,5 @@ entry("getpid");
entry("sbrk");
entry("sleep");
entry("uptime");
+entry("sigalarm");
+entry("sigreturn");
测试

Xv6 Book Chapter 4
Xv6 金句摘录,以下仅记录 Xv6 book 中笔者觉得 make sense 或者有用或者自己不太熟悉的部分:
There are three kinds of event which cause the CPU to set aside ordinary execution of instructions and force a transfer of control to special code that handles the event:
- ecall: when A user program executes the ecall instruction to ask the kernel to do something for it.
- exception: An instruction (user or kernel) does something illegal, such as divide by zero or use an invalid virtual address.
- interrupt: A device signals that it needs attention, for example when the disk hardware finishes a read or write request.
It also makes sense for exceptions since xv6 responds to all exceptions from user space by killing the offending program. (Xv6 对用户态发出 exception 的处理办法是 kill)
There is a similar set of control registers for traps handled in machine mode; xv6 uses them only for the special case of timer interrupts.
The csrw instruction at the start of uservec saves a0 in sscratch.
The process’s p->trapframe also points to the trapframe, though at its physical address so the kernel can use it through the kernel page table.
kernelvec saves the registers on the stack of the interrupted kernel thread, which makes sense because the register values belong to that thread.
Luckily the RISC-V always disables interrupts when it starts to take a trap, and xv6 doesn’t enable them again until after it sets stvec.
RISC-V distinguishes three kinds of page fault:
- load page faults (when a load instruction cannot translate its virtual address)
- store page faults (when a store instruction cannot translate its virtual address)
- instruction page faults (when the address in the program counter doesn’t translate)
Copy-on-write requires book-keeping to help decide when physical pages can be freed, since each page can be referenced by a varying number of page tables depending on the history of forks, page faults, execs, and exits.
A common example is fork followed by exec: a few pages may be written after the fork, but then the child’s exec releases the bulk of the memory inherited from the parent. Copy-on-write fork eliminates the need to ever copy this memory.
lazy allocation: Operating systems can reduce this cost by allocating a batch of consecutive pages per page fault instead of one page and by specializing the kernel entry/exit code for such page-faults.
demand paging: On a page fault, the kernel reads the content of the page from disk and maps it into the user address space.
Other features that combine paging and page-fault exceptions include automatically extending stacks and memory-mapped files.
Production operating systems implement copy-on-write fork, lazy allocation, demand paging, paging to disk, memory-mapped files, etc.
Production operating systems will try to use all of physical memory, either for applications or caches (e.g., the buffer cache of the file system, which we will cover later in Section 8.2).
References
RISC-V ELF psABI Specification
