由于 CS285 2023 Fall 版本有 video recordings,因此选择该版本尝试完成作业。本人仓库传送门。
希望这学期能够有时间尽可能学一点 DRL 吧,目前上课又不太能跟得上了🤡,亟需动手实践下代码。以下内容大部分为 AIGC,代码实现也为 AIGC(博主实在太菜了,对 python/RL 相关库完全不会,只能靠 vibe coding 了),已经过个人校对和修补,希望没有大锅。
证明题解答
1.1 证明 $\sum_{s_t}|p_{\pi_\theta}(s_t) – p_{\pi^*}(s_t)| \leq 2T\varepsilon$
这个求和 $\sum_{s_t}$ 是对某一个时间步 t 上所有可能状态求和。题目要证明的是:在任意时间步 t,模仿策略和专家策略的状态分布的 L1 距离(即两倍总变差距离)不超过 $2T\varepsilon$。
已知条件
$$\frac{1}{T}\sum_{t=1}^{T} \underbrace{E_{p_{\pi^*}(s_t)}[\pi_\theta(a_t \neq \pi^{*}(s_t)|s_t)]}_{\text{定义为 } \varepsilon_t} \leq \varepsilon$$
即 $\sum_{t=1}^{T} \varepsilon_t \leq T\varepsilon$,其中 $\varepsilon_t$ 是在专家第 t 步状态分布下、模仿策略选错动作的概率。
证明:
第一步:构造耦合过程(Coupling)
想象同时运行 $\pi^*$ 和 $\pi_\theta$,让它们从同一个初始状态出发:
- 如果到目前为止 $\pi_\theta$ 的每一步都选了和 $\pi^*$ 相同的动作,那么两者处于完全相同的状态(”耦合中”)
- 一旦 $\pi_\theta$ 在某一步选了不同的动作,两者解耦,之后状态可以完全不同
第二步:计算”仍在耦合中”时犯错的概率
在耦合过程中,如果到第 $t’$ 步仍未解耦,那么 $\pi_\theta$ 当前的状态分布就是 $p_{\pi^*}(s_{t’})$(因为两者走的是同一条路径)。此时犯错的概率恰好是:
$$P(\text{第 } t’ \text{ 步犯错} \mid \text{之前未解耦}) = E_{p_{\pi^*}(s_{t’})}[\pi_\theta(a \neq \pi^*(s_{t’})|s_{t’})] = \varepsilon_{t’}$$
第三步:用联合界(Union Bound)界定解耦概率
到时间步 $t$ 之前已经解耦的概率(即在步骤 $1, 2, \ldots, t-1$ 中至少犯过一次错):
$$P(\text{到第 } t \text{ 步已解耦}) = P\left(\bigcup_{t’=1}^{t-1} E_{t’}\right) \leq \sum_{t’=1}^{t-1} P(E_{t’})$$
其中严格来说,$P(E_{t’})$ 应该是条件概率(在之前未犯错的前提下犯错),但联合界给出的是一个上界,将每一步犯错视为独立事件来放缩:
$$P(\text{到第 } t \text{ 步已解耦}) \leq \sum_{t’=1}^{t-1} \varepsilon_{t’}$$
第四步:用耦合不等式界定总变差距离
由耦合引理(Coupling Lemma),两个分布的总变差距离不超过耦合过程中两者不同的概率:
$$\frac{1}{2}\sum_{s}|p_{\pi_\theta}(s_t = s) – p_{\pi^*}(s_t = s)| \leq P(\text{到第 } t \text{ 步已解耦}) \leq \sum_{t’=1}^{t-1} \varepsilon_{t’}$$
所以:
$$\sum_{s}|p_{\pi_\theta}(s_t = s) – p_{\pi^*}(s_t = s)| \leq 2\sum_{t’=1}^{t-1} \varepsilon_{t’}$$
第五步:利用已知条件完成放缩
$$2\sum_{t’=1}^{t-1}\varepsilon_{t’} \leq 2\sum_{t’=1}^{T}\varepsilon_{t’} \leq 2T\varepsilon$$
$$\boxed{\sum_{s_t}|p_{\pi_\theta}(s_t) – p_{\pi^*}(s_t)| \leq 2T\varepsilon} \quad \blacksquare$$
1.2(a) 奖励仅在最后一步时,$J(\pi^*) – J(\pi_\theta) = O(T\varepsilon)$
条件
$r(s_t) = 0$ 对所有 $t < T$,只有 $r(s_T)$ 可能非零,且 $|r(s_T)| \leq R_{\max}$。
证明:
$$J(\pi^*) – J(\pi_\theta) = \sum_{t=1}^{T}E_{p_{\pi^*}(s_t)}[r(s_t)] – \sum_{t=1}^{T}E_{p_{\pi_\theta}(s_t)}[r(s_t)]$$
因为 $t < T$ 时 $r(s_t) = 0$,所以只剩最后一项:
$$= E_{p_{\pi^*}(s_T)}[r(s_T)] – E_{p_{\pi_\theta}(s_T)}[r(s_T)]$$
$$= \sum_{s} \big(p_{\pi^*}(s_T = s) – p_{\pi_\theta}(s_T = s)\big) \cdot r(s)$$
取绝对值并放缩:
$$|J(\pi^*) – J(\pi_\theta)| \leq \sum_{s} |p_{\pi^*}(s_T = s) – p_{\pi_\theta}(s_T = s)| \cdot |r(s)|$$
$$\leq R_{\max} \cdot \sum_{s}|p_{\pi^*}(s_T = s) – p_{\pi_\theta}(s_T = s)|$$
由 1.1 的结论:
$$\leq R_{\max} \cdot 2T\varepsilon$$
$$\boxed{J(\pi^*) – J(\pi_\theta) = O(T\varepsilon)} \quad \blacksquare$$
1.2(b) 任意奖励时,$J(\pi^*) – J(\pi_\theta) = O(T^2\varepsilon)$
条件
$r(s_t)$ 在每个时间步都可能非零,$|r(s_t)| \leq R_{\max}$。
证明:
$$J(\pi^*) – J(\pi_\theta) = \sum_{t=1}^{T}\left(E_{p_{\pi^*}(s_t)}[r(s_t)] – E_{p_{\pi_\theta}(s_t)}[r(s_t)]\right)$$
对每一项取绝对值(三角不等式):
$$|J(\pi^*) – J(\pi_\theta)| \leq \sum_{t=1}^{T}\left|E_{p_{\pi^*}(s_t)}[r(s_t)] – E_{p_{\pi_\theta}(s_t)}[r(s_t)]\right|$$
对每个时间步 $t$,和 1.2(a) 中同样的方法:
$$\left|E_{p_{\pi^*}(s_t)}[r(s_t)] – E_{p_{\pi_\theta}(s_t)}[r(s_t)]\right| \leq R_{\max}\sum_{s}|p_{\pi^*}(s_t = s) – p_{\pi_\theta}(s_t = s)|$$
由 1.1 的结论:
$$\leq R_{\max} \cdot 2T\varepsilon$$
对 $T$ 个时间步求和:
$$|J(\pi^*) – J(\pi_\theta)| \leq \sum_{t=1}^{T} R_{\max} \cdot 2T\varepsilon = 2T^2\varepsilon \cdot R_{\max}$$
$$\boxed{J(\pi^*) – J(\pi_\theta) = O(T^2\varepsilon)} \quad \blacksquare$$
这三个结果揭示了行为克隆的根本缺陷:
- 1.1:即使平均犯错率很小(ε),每个时间步的状态分布偏差可以达到 $O(T\varepsilon)$——与轨迹长度成正比
- 1.2(a):如果只关心最终状态,性能损失是 $O(T\varepsilon)$
- 1.2(b):如果每步都有奖励,性能损失是 $O(T^2\varepsilon)$——误差随轨迹长度的平方增长
这就是为什么在长时间步的任务中,纯行为克隆效果很差,而 DAgger 算法通过不断让专家在模仿策略实际访问的状态上重新标注数据,可以打破这个平方级的误差累积。
框架代码解读
Overview: 总体架构
HW1 的框架代码实现了 Imitation Learning(模仿学习) 的两种经典算法:
1. Behavior Cloning (BC): 直接从专家数据中学习策略
2. DAgger (Dataset Aggregation): 迭代式地收集数据并用专家标注,解决分布偏移问题
核心架构组件
整个框架采用模块化设计,主要包含以下几个层次:
run_hw1.py (主训练循环)
↓
├── MLPPolicySL (策略网络)
│ ├── forward(): 前向传播,输出动作分布
│ └── update(): 监督学习更新策略参数
│
├── ReplayBuffer (经验回放缓冲区)
│ └── add_rollouts(): 存储轨迹数据
│
├── utils (工具函数)
│ ├── sample_trajectory(): 采样单条轨迹
│ └── sample_trajectories(): 采样多条轨迹
│
└── Logger (日志记录)
├── log_scalar(): 记录标量指标
└── log_paths_as_videos(): 记录视频
训练流程
Behavior Cloning (n_iter=1):
1. 加载专家数据 → 2. 添加到 replay buffer → 3. 采样 mini-batch → 4. 监督学习更新策略
DAgger (n_iter>1):
1. 第 0 轮:从专家数据初始化(同 BC)
2. 第 i 轮 (i>0):
– 用当前策略采样轨迹
– 用专家策略重新标注动作
– 添加到 replay buffer
– 采样 mini-batch 更新策略
3. 重复直到收敛
数据流
Environment → sample_trajectory() → paths (轨迹列表)
↓
ReplayBuffer.add_rollouts()
↓
[obs, acs] 数组
↓
随机采样 mini-batch
↓
MLPPolicySL.update()
实验环境:OpenAI Gym 与 MuJoCo
OpenAI Gym 简介
OpenAI Gym 是一个用于开发和比较强化学习算法的工具包,提供了标准化的环境接口。在本作业中,我们使用 Gym 的核心 API 与 MuJoCo 物理引擎进行交互。Gym 环境遵循统一的接口设计,主要包含以下几个核心方法:
import gym
# 创建环境
env = gym.make('Ant-v4', render_mode=None)
# 重置环境,返回初始观测
observation = env.reset(seed=42) # observation: numpy array
# 执行动作,返回转移信息
next_observation, reward, done, info = env.step(action)
# - next_observation: 下一个状态的观测
# - reward: 即时奖励
# - done: 是否终止(布尔值)
# - info: 额外的调试信息(字典)
# 获取环境属性
env.observation_space # 观测空间(Box 或 Discrete)
env.action_space # 动作空间(Box 或 Discrete)
env.spec.max_episode_steps # 最大步数限制
Gym 的设计哲学是将环境与算法解耦,使得同一套算法代码可以无缝切换到不同的环境中。观测空间和动作空间通过 gym.spaces 模块定义,常见的类型包括 Box(连续空间)和 Discrete(离散空间)。本作业中的所有环境都使用连续的观测空间和动作空间。
MuJoCo 物理引擎
MuJoCo (Multi-Joint dynamics with Contact) 是一个高性能的物理仿真引擎,专门用于机器人控制和生物力学研究。它能够高效地模拟多关节系统的动力学,包括接触、摩擦和约束。MuJoCo 的主要特点包括高精度仿真(使用先进的数值积分方法)、高效计算(优化的 C/C++ 实现,支持实时仿真)、丰富的传感器(提供关节位置、速度、力矩等信息)以及可视化支持(内置渲染器可生成训练视频)。在 Gym 中,MuJoCo 环境通过 mujoco 库与物理引擎交互,环境的观测通常包含机器人的关节角度、角速度、身体位置、速度等信息,动作则对应于关节的力矩控制信号。
本作业使用的四个环境
本作业支持四个经典的 MuJoCo 连续控制环境,它们在机器人形态、控制难度和任务目标上各有特点:
1. Ant-v4(四足蚂蚁)
Ant 是一个四足机器人,拥有 8 个自由度(每条腿 2 个关节)。任务目标是让蚂蚁尽可能快地向前移动,同时保持身体稳定不倒下。
- 观测空间维度:27 维,包括躯干的位置、方向、线速度、角速度,以及 8 个关节的角度和角速度
- 动作空间维度:8 维,对应 8 个关节的力矩控制
- 奖励函数:主要由前进速度决定,同时惩罚能量消耗和不稳定的动作
- 难度特点:四足协调控制难度较高,需要学习稳定的步态模式,容易出现翻倒或原地打转的失败模式
2. Walker2d-v4(双足行走者)
Walker2d 是一个二维平面上的双足机器人,拥有 6 个自由度。任务目标是让机器人直立行走,尽可能快地向前移动。
- 观测空间维度:17 维,包括躯干高度、角度、线速度、角速度,以及 6 个关节的角度和角速度
- 动作空间维度:6 维,对应 6 个关节的力矩控制
- 奖励函数:奖励前进速度,惩罚能量消耗,如果躯干高度过低或倾斜过大则终止
- 难度特点:需要学习动态平衡,保持直立姿态的同时向前移动,比四足机器人更容易失去平衡
3. HalfCheetah-v4(半猎豹)
HalfCheetah 是一个二维平面上的四足机器人(简化的猎豹模型),拥有 6 个自由度。任务目标是让猎豹尽可能快地向前奔跑。
- 观测空间维度:17 维,包括躯干的位置、角度、线速度、角速度,以及 6 个关节的角度和角速度
- 动作空间维度:6 维,对应 6 个关节的力矩控制
- 奖励函数:主要奖励前进速度,轻微惩罚能量消耗,没有倒地终止条件
- 难度特点:相对容易学习,因为没有平衡约束(不会倒地),主要挑战是学习高效的奔跑步态
4. Hopper-v4(单足跳跃者)
Hopper 是一个二维平面上的单足机器人,拥有 3 个自由度。任务目标是让机器人单腿跳跃前进。
- 观测空间维度:11 维,包括躯干高度、角度、线速度、角速度,以及 3 个关节的角度和角速度
- 动作空间维度:3 维,对应 3 个关节的力矩控制
- 奖励函数:奖励前进速度和存活时间,惩罚能量消耗,如果躯干高度过低或倾斜过大则终止
- 难度特点:平衡难度最高,需要通过跳跃维持动态平衡,容易倒地,但由于自由度少,动作空间相对简单
环境选择建议
对于初学者,建议按照以下顺序进行实验:
- HalfCheetah-v4:最容易上手,没有倒地约束,适合验证算法基本功能
- Ant-v4:中等难度,四足稳定性较好,但需要协调控制
- Walker2d-v4:较高难度,需要学习动态平衡
- Hopper-v4:最具挑战性,平衡难度最高
在本作业中,这些环境主要用于测试模仿学习算法的泛化能力。专家策略已经预先训练好并保存在 cs285/policies/experts/ 目录下,对应的专家数据保存在 cs285/expert_data/ 目录下。
模块 1: 策略网络 (MLPPolicySL)
文件: cs285/policies/MLP_policy.py
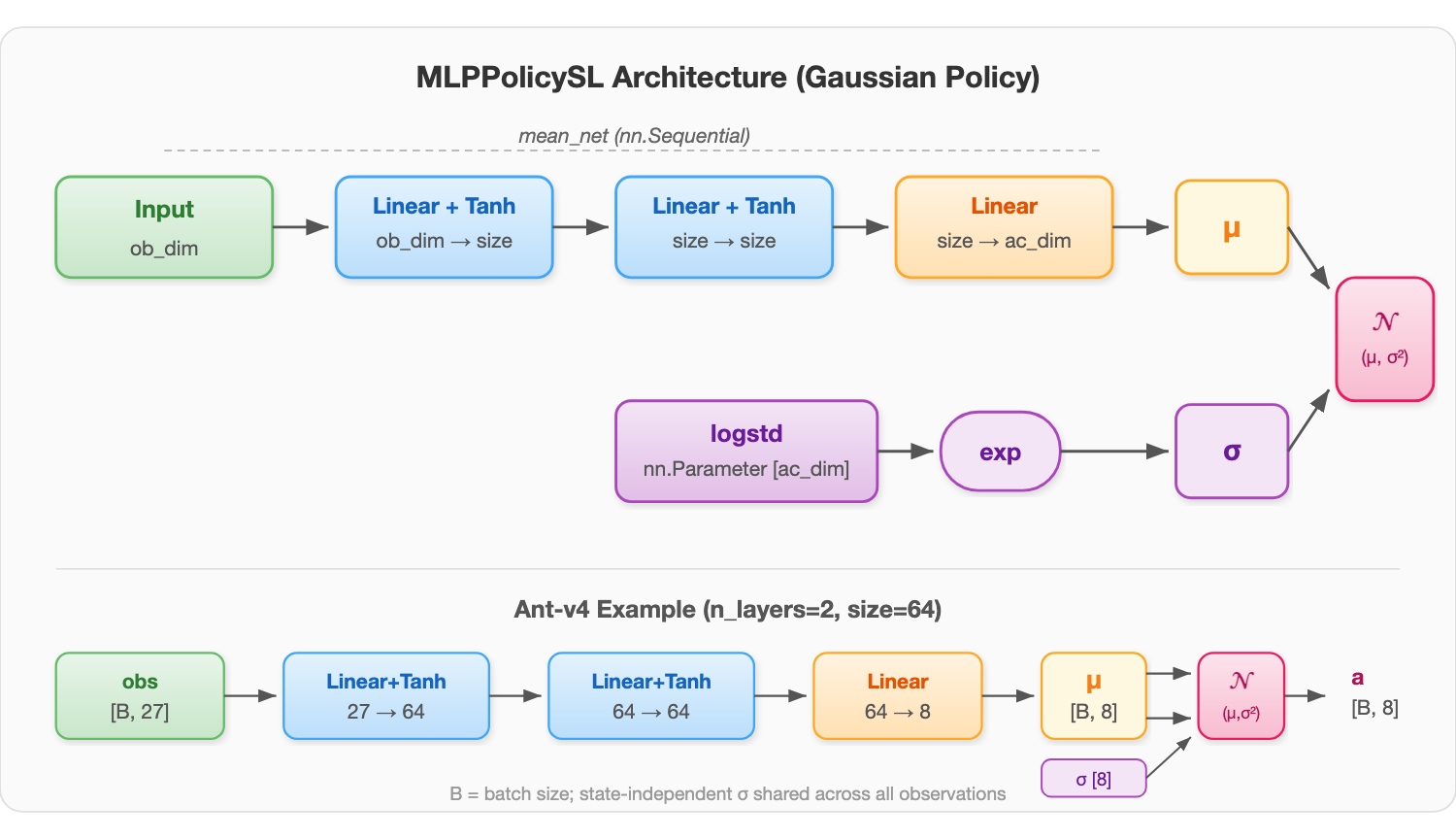
上图展示了 MLPPolicySL 的整体架构。网络由两个独立的参数组件构成:mean_net 和 logstd。mean_net 是一个标准的多层感知机,将观测 $s$ 映射为动作均值 $\mu_\theta(s)$,由 n_layers 个隐藏层组成,每层包含一个全连接层和 Tanh 激活函数,最后一层为无激活函数的线性输出层。logstd 是一个与状态无关的可学习参数向量,经过指数变换得到标准差 $\sigma = \exp(\text{logstd})$。两者共同定义了高斯策略 $\pi(a|s) = \mathcal{N}(\mu_\theta(s),\, \sigma^2)$,前向传播时从该分布中采样动作。图中下半部分以 Ant-v4 环境为例(ob_dim=27, ac_dim=8, n_layers=2, size=64)展示了具体的张量维度流。
1.1 网络构建函数 build_mlp()
该函数构建一个多层感知机(MLP),用于策略网络的主干。
def build_mlp(
input_size: int, # 输入维度(观测空间维度)
output_size: int, # 输出维度(动作空间维度)
n_layers: int, # 隐藏层数量
size: int # 每个隐藏层的神经元数量
) -> nn.Module:
"""构建前馈神经网络"""
layers = []
in_size = input_size
# 构建 n_layers 个隐藏层
for _ in range(n_layers):
layers.append(nn.Linear(in_size, size)) # 全连接层
layers.append(nn.Tanh()) # Tanh 激活函数
in_size = size
# 输出层(无激活函数)
layers.append(nn.Linear(in_size, output_size))
mlp = nn.Sequential(*layers)
return mlp
设计要点:
– 使用 Tanh 激活函数(适合连续控制任务)
– 输出层无激活函数,输出原始 logits
– 返回 nn.Sequential 对象,便于前向传播
1.2 策略类 MLPPolicySL
该类继承自 BasePolicy 和 nn.Module,实现监督学习的策略网络。
核心属性:
class MLPPolicySL(BasePolicy, nn.Module):
def __init__(self, ac_dim, ob_dim, n_layers, size, learning_rate=1e-4, ...):
super().__init__(**kwargs)
# 策略网络:输出动作均值
self.mean_net = build_mlp(
input_size=self.ob_dim,
output_size=self.ac_dim,
n_layers=self.n_layers,
size=self.size,
)
# 对数标准差:可学习参数(与状态无关)
self.logstd = nn.Parameter(
torch.zeros(self.ac_dim, dtype=torch.float32, device=ptu.device)
)
# 优化器:同时优化均值网络和标准差
self.optimizer = optim.Adam(
itertools.chain([self.logstd], self.mean_net.parameters()),
self.learning_rate
)
设计要点:
– 高斯策略: 策略输出为高斯分布 $\pi(a|s) = \mathcal{N}(\mu_\theta(s), \sigma)$
– mean_net: 神经网络输出均值 $\mu_\theta(s)$
– logstd: 对数标准差 $\log \sigma$,与状态无关(state-independent)
– 使用 itertools.chain 将两部分参数合并优化
在策略网络的初始化阶段,优化器的构建采用了一个关键设计:
self.optimizer = optim.Adam(
itertools.chain([self.logstd], self.mean_net.parameters()),
self.learning_rate
)
这里 itertools.chain 将两组参数合并为一个统一的迭代器。第一组是 self.logstd,这是一个形状为 [ac_dim] 的独立参数向量,表示每个动作维度的对数标准差;第二组是 self.mean_net.parameters(),包含神经网络中所有层的权重矩阵和偏置向量。通过这种方式,Adam 优化器能够同时更新均值网络参数 $\theta$ 和标准差参数 $\log\sigma$,使得模型在学习如何预测动作的同时,也能自适应地调整策略的随机性程度。
1.3 需要实现的方法
forward() 方法 (TODO):
def forward(self, observation: torch.FloatTensor) -> Any:
"""
前向传播:根据观测输出动作
Args:
observation: 形状为 [batch_size, ob_dim] 的观测张量
Returns:
可以返回多种形式:
- torch.FloatTensor: 直接返回采样的动作
- torch.distributions.Distribution: 返回动作分布对象(推荐)
"""
# TODO: 实现前向传播
# 1. 通过 mean_net 计算均值
# 2. 通过 logstd 计算标准差
# 3. 构建高斯分布并采样动作
实现思路:
– 计算均值: mean = self.mean_net(observation)
– 计算标准差: std = torch.exp(self.logstd)
– 构建分布: dist = torch.distributions.Normal(mean, std)
– 返回分布对象或采样动作
update() 方法 (TODO):
def update(self, observations, actions):
"""
监督学习更新策略
Args:
observations: 形状为 [batch_size, ob_dim]
actions: 形状为 [batch_size, ac_dim],专家动作标签
Returns:
dict: 包含 'Training Loss' 的字典
"""
# TODO: 实现监督学习
# 1. 将数据转换为 PyTorch 张量
# 2. 前向传播得到预测动作分布
# 3. 计算负对数似然损失(NLL Loss)
# 4. 反向传播并更新参数
模块 2: 轨迹采样 (utils.py)
文件: cs285/infrastructure/utils.py
2.1 单轨迹采样 sample_trajectory()
该函数在环境中执行一条完整的轨迹(episode),直到终止或达到最大长度。
def sample_trajectory(env, policy, max_path_length, render=False):
"""在环境中采样一条轨迹"""
# TODO: 重置环境,获取初始观测
ob = env.reset() # 返回初始状态 s_0
# 初始化存储列表
obs, acs, rewards, next_obs, terminals = [], [], [], [], []
steps = 0
while True:
# TODO: 使用策略选择动作
ac = policy.get_action(ob) # 调用策略的 get_action 方法
ac = ac[0] # 提取动作(去除 batch 维度)
# TODO: 在环境中执行动作
next_ob, rew, done, _ = env.step(ac) # 执行动作,获取转移
# TODO: 判断轨迹是否结束
steps += 1
rollout_done = done or (steps >= max_path_length) # 终止条件
# 记录转移 (s_t, a_t, r_t, s_{t+1}, done_t)
obs.append(ob)
acs.append(ac)
rewards.append(rew)
next_obs.append(next_ob)
terminals.append(rollout_done)
ob = next_ob # 更新当前状态
if rollout_done:
break
# 返回轨迹字典
return {
"observation": np.array(obs, dtype=np.float32),
"action": np.array(acs, dtype=np.float32),
"reward": np.array(rewards, dtype=np.float32),
"next_observation": np.array(next_obs, dtype=np.float32),
"terminal": np.array(terminals, dtype=np.float32)
}
关键点:
– 终止条件: done=True (环境终止) 或 steps >= max_path_length (超时)
– 数据格式: 返回字典,每个键对应一个 numpy 数组
– 轨迹长度: 可变长度,取决于任务和终止条件
2.2 批量轨迹采样 sample_trajectories()
该函数持续采样轨迹,直到收集到足够的时间步数。
def sample_trajectories(env, policy, min_timesteps_per_batch, max_path_length, render=False):
"""采样轨迹直到达到最小时间步数"""
timesteps_this_batch = 0
paths = []
# 持续采样直到收集足够的时间步
while timesteps_this_batch < min_timesteps_per_batch:
# 采样一条轨迹
path = sample_trajectory(env, policy, max_path_length, render)
paths.append(path)
# 累计时间步数
timesteps_this_batch += get_pathlength(path)
return paths, timesteps_this_batch
设计要点:
– 以时间步数为单位(而非轨迹数量)
– 返回轨迹列表和总时间步数
– 用于 DAgger 中每轮收集固定数量的数据
2.3 辅助函数
convert_listofrollouts(): 将轨迹列表转换为拼接的数组
def convert_listofrollouts(paths, concat_rew=True):
"""
将多条轨迹拼接成单个数组
输入: paths = [path1, path2, ...]
输出: (observations, actions, rewards, next_observations, terminals)
每个都是拼接后的 numpy 数组
"""
observations = np.concatenate([path["observation"] for path in paths])
actions = np.concatenate([path["action"] for path in paths])
# ... 其他字段类似
return observations, actions, rewards, next_observations, terminals
compute_metrics(): 计算训练和评估指标
def compute_metrics(paths, eval_paths):
"""计算平均回报、标准差、最大/最小回报、平均轨迹长度等"""
train_returns = [path["reward"].sum() for path in paths]
eval_returns = [eval_path["reward"].sum() for eval_path in eval_paths]
# 返回包含各种统计量的字典
模块 3: 经验回放缓冲区 (ReplayBuffer)
文件: cs285/infrastructure/replay_buffer.py
ReplayBuffer 用于存储和管理收集到的轨迹数据。
class ReplayBuffer(object):
def __init__(self, max_size=1000000):
self.max_size = max_size # 最大容量
# 存储原始轨迹列表
self.paths = []
# 存储拼接后的数组(用于高效采样)
self.obs = None
self.acs = None
self.rews = None
self.next_obs = None
self.terminals = None
3.1 添加轨迹 add_rollouts()
def add_rollouts(self, paths, concat_rew=True):
"""将新轨迹添加到缓冲区"""
# 1. 添加到轨迹列表
for path in paths:
self.paths.append(path)
# 2. 转换为拼接数组
observations, actions, rewards, next_observations, terminals = \
convert_listofrollouts(paths, concat_rew)
# 3. 拼接到现有数据(保持最大容量限制)
if self.obs is None:
# 首次添加
self.obs = observations[-self.max_size:]
self.acs = actions[-self.max_size:]
# ... 其他字段
else:
# 追加并保留最新的 max_size 个样本
self.obs = np.concatenate([self.obs, observations])[-self.max_size:]
self.acs = np.concatenate([self.acs, actions])[-self.max_size:]
# ... 其他字段
设计要点:
– 双重存储: 既保存原始轨迹(用于日志),也保存拼接数组(用于采样)
– 容量管理: 使用 [-self.max_size:] 切片保留最新数据
– DAgger 友好: 支持累积多轮数据,实现 dataset aggregation
模块 4: 主训练循环 (run_hw1.py)
文件: cs285/scripts/run_hw1.py
4.1 初始化阶段
def run_training_loop(params):
# 1. 创建日志记录器
logger = Logger(params['logdir'])
# 2. 设置随机种子(保证可复现性)
seed = params['seed']
np.random.seed(seed)
torch.manual_seed(seed)
ptu.init_gpu(use_gpu=not params['no_gpu'], gpu_id=params['which_gpu'])
# 3. 创建环境
env = gym.make(params['env_name'], render_mode=None)
env.reset(seed=seed)
ob_dim = env.observation_space.shape[0] # 观测维度
ac_dim = env.action_space.shape[0] # 动作维度
# 4. 创建策略网络
actor = MLPPolicySL(
ac_dim, ob_dim,
params['n_layers'],
params['size'],
learning_rate=params['learning_rate'],
)
# 5. 创建 replay buffer
replay_buffer = ReplayBuffer(params['max_replay_buffer_size'])
# 6. 加载专家策略(用于 DAgger 重标注)
expert_policy = LoadedGaussianPolicy(params['expert_policy_file'])
关键参数:
– n_layers, size: 策略网络的深度和宽度
– learning_rate: 学习率(默认 5e-3)
– max_replay_buffer_size: 缓冲区容量(默认 1M)
4.2 训练循环主体
训练循环的数据收集部分根据当前迭代轮次采用不同的策略。在第 0 轮(BC 阶段),直接从文件中加载预先收集好的专家数据;从第 1 轮开始(DAgger 阶段),则使用当前学习的策略在环境中采样新的轨迹,并用专家策略对收集到的观测重新标注动作。这种设计使得同一套代码可以通过 n_iter=1 运行纯 BC,也可以通过 n_iter>1 配合 --do_dagger 运行 DAgger 算法。
if itr == 0:
# BC: 从专家数据文件加载
paths = pickle.load(open(params['expert_data'], 'rb'))
envsteps_this_batch = 0
else:
# DAgger: 用当前策略采样并用专家重标注
assert params['do_dagger']
# TODO: 使用 utils.sample_trajectories 收集 batch_size 个时间步的轨迹
paths, envsteps_this_batch = TODO
if params['do_dagger']:
# TODO: 用专家策略重新标注动作
# HINT: 用 expert_policy.get_action(path["observation"]) 替换 path["action"]
paths = TODO
4.3 训练阶段
收集到的数据添加到 replay buffer 后,进入训练阶段。每轮迭代执行 num_agent_train_steps_per_iter 次梯度更新(默认 1000),每次更新从 replay buffer 中随机采样一个大小为 train_batch_size 的 mini-batch(默认 100),然后调用策略网络的 update() 方法进行参数更新。
# 添加数据到 replay buffer
total_envsteps += envsteps_this_batch
replay_buffer.add_rollouts(paths)
# 训练策略
training_logs = []
for _ in range(params['num_agent_train_steps_per_iter']):
# TODO: 从 replay buffer 中随机采样 mini-batch 并更新策略
...
4.4 日志记录阶段
# ========== 第四步:评估和日志 ==========
if log_video:
# 保存视频:用当前策略采样轨迹并渲染
eval_video_paths = utils.sample_n_trajectories(
env, actor, MAX_NVIDEO, MAX_VIDEO_LEN, render=True
)
logger.log_paths_as_videos(
eval_video_paths, itr, fps=fps,
max_videos_to_save=MAX_NVIDEO,
video_title='eval_rollouts'
)
if log_metrics:
# 评估当前策略性能
eval_paths, eval_envsteps_this_batch = utils.sample_trajectories(
env, actor,
params['eval_batch_size'],
params['ep_len']
)
# 计算指标
logs = utils.compute_metrics(paths, eval_paths)
logs.update(training_logs[-1]) # 添加训练损失
logs["Train_EnvstepsSoFar"] = total_envsteps
logs["TimeSinceStart"] = time.time() - start_time
# 记录到 TensorBoard
for key, value in logs.items():
logger.log_scalar(value, key, itr)
logger.flush()
日志内容:
– 标量指标: 平均回报、标准差、最大/最小回报、轨迹长度、训练损失
– 视频: 当前策略的执行效果(可视化)
– 频率控制: video_log_freq, scalar_log_freq 控制记录频率
模块 5: 日志系统 (Logger)
文件: cs285/infrastructure/logger.py
Logger 类封装了 TensorBoard 的日志记录功能。
class Logger:
def __init__(self, log_dir, n_logged_samples=10, summary_writer=None):
self._log_dir = log_dir
# 使用 TensorBoardX 创建 SummaryWriter
self._summ_writer = SummaryWriter(log_dir, flush_secs=1, max_queue=1)
def log_scalar(self, scalar, name, step_):
"""记录标量值(如损失、回报)"""
self._summ_writer.add_scalar('{}'.format(name), scalar, step_)
def log_paths_as_videos(self, paths, step, max_videos_to_save=2, fps=10, video_title='video'):
"""将轨迹渲染为视频并记录"""
# 1. 提取图像观测
videos = [np.transpose(p['image_obs'], [0, 3, 1, 2]) for p in paths]
# 2. 填充到相同长度(TensorBoard 要求)
max_length = max(v.shape[0] for v in videos[:max_videos_to_save])
for i in range(max_videos_to_save):
if videos[i].shape[0] < max_length:
# 用最后一帧填充
padding = np.tile([videos[i][-1]], (max_length - videos[i].shape[0], 1, 1, 1))
videos[i] = np.concatenate([videos[i], padding], 0)
# 3. 堆叠并记录
videos = np.stack(videos[:max_videos_to_save], 0)
self.log_video(videos, video_title, step, fps=fps)
设计要点:
– 使用 TensorBoardX 库(兼容 PyTorch)
– 视频格式: [N, T, C, H, W] (批次, 时间, 通道, 高, 宽)
– 自动填充不同长度的视频
模块 6: 基类和工具
6.1 BasePolicy 抽象类
class BasePolicy(object, metaclass=abc.ABCMeta):
def get_action(self, obs: np.ndarray) -> np.ndarray:
"""根据观测返回动作(推理模式)"""
raise NotImplementedError
def update(self, obs: np.ndarray, acs: np.ndarray, **kwargs) -> dict:
"""更新策略参数(训练模式)"""
raise NotImplementedError
def save(self, filepath: str):
"""保存模型参数"""
raise NotImplementedError
设计模式:
– 使用抽象基类定义接口
– 所有策略类必须实现这三个方法
– 便于扩展到其他算法(如 Policy Gradient)
6.2 PyTorch 工具 (pytorch_util.py)
# 设备管理
device = None # 全局设备变量
def init_gpu(use_gpu=True, gpu_id=0):
"""初始化 GPU/CPU 设备"""
global device
if use_gpu and torch.cuda.is_available():
device = torch.device(f'cuda:{gpu_id}')
else:
device = torch.device('cpu')
def to_numpy(tensor):
"""将 PyTorch 张量转换为 numpy 数组"""
return tensor.detach().cpu().numpy()
总结:需要实现的 TODO 部分
根据框架代码分析,本次作业需要实现以下几个关键部分:
TODO 1: MLPPolicySL.forward() (policies/MLP_policy.py)
任务: 实现策略的前向传播
– 输入观测,输出动作分布或采样的动作
– 构建高斯分布 $\mathcal{N}(\mu_\theta(s), \sigma)$
TODO 2: MLPPolicySL.update() (policies/MLP_policy.py)
任务: 实现监督学习更新
– 计算负对数似然损失
– 反向传播并更新参数
– 返回训练损失
TODO 3: sample_trajectory() (infrastructure/utils.py)
任务: 完成轨迹采样的三个空缺
– 重置环境获取初始观测
– 使用策略选择动作并执行
– 判断轨迹终止条件
TODO 4: run_training_loop() – 数据收集 (scripts/run_hw1.py)
任务: 在 DAgger 中收集数据
– 使用 utils.sample_trajectories() 采样轨迹
– 用专家策略重新标注动作
TODO 5: run_training_loop() – 采样 mini-batch (scripts/run_hw1.py)
任务: 从 replay buffer 采样训练数据
– 使用 np.random.permutation() 生成随机索引
– 提取对应的观测和动作
框架设计亮点
- 模块化设计: 策略、环境交互、数据存储、日志记录各司其职
- 可扩展性: 通过
BasePolicy抽象类便于扩展到其他算法 - 数据效率: ReplayBuffer 支持数据累积,适合 DAgger 的迭代学习
- 可视化友好: 集成 TensorBoard,支持标量和视频日志
- 设备无关: 通过
pytorch_util统一管理 GPU/CPU
作业思路与实现
Behavioral Cloning 实现
Behavioral Cloning (BC) 是一种监督学习方法,通过模仿专家的行为来学习策略。本次实现需要完成三个文件中的 TODO 部分。
实现 1: 轨迹采样 (utils.py)
文件: cs285/infrastructure/utils.py
任务: 实现 sample_trajectory 函数,用于在环境中采样一条完整的轨迹。
实现代码:
def sample_trajectory(env, policy, max_path_length, render=False):
"""Sample a rollout in the environment from a policy."""
# 重置环境,获取初始观测
ob = env.reset()
# 初始化存储列表
obs, acs, rewards, next_obs, terminals, image_obs = [], [], [], [], [], []
steps = 0
while True:
# 渲染图像(如果需要)
if render:
if hasattr(env, 'sim'):
img = env.sim.render(camera_name='track', height=500, width=500)[::-1]
else:
img = env.render(mode='single_rgb_array')
image_obs.append(cv2.resize(img, dsize=(250, 250), interpolation=cv2.INTER_CUBIC))
# 使用策略选择动作
ac = policy.get_action(ob)
ac = ac[0]
# 在环境中执行动作
next_ob, rew, done, _ = env.step(ac)
# 判断轨迹是否结束
steps += 1
rollout_done = done or (steps >= max_path_length)
# 记录转移
obs.append(ob)
acs.append(ac)
rewards.append(rew)
next_obs.append(next_ob)
terminals.append(rollout_done)
ob = next_ob
if rollout_done:
break
return {"observation": np.array(obs, dtype=np.float32),
"image_obs": np.array(image_obs, dtype=np.uint8),
"reward": np.array(rewards, dtype=np.float32),
"action": np.array(acs, dtype=np.float32),
"next_observation": np.array(next_obs, dtype=np.float32),
"terminal": np.array(terminals, dtype=np.float32)}
实现要点:
– 使用 policy.get_action(ob) 获取动作,注意需要提取第一个元素 ac[0]
– 终止条件为 done or (steps >= max_path_length),即环境终止或达到最大步数
– 返回包含完整轨迹信息的字典
实现 2: 策略网络 (MLP_policy.py)
文件: cs285/policies/MLP_policy.py
任务: 实现 forward 和 update 方法,构建高斯策略并进行监督学习。
2.1 forward() 方法
实现代码:
def forward(self, observation: torch.FloatTensor) -> Any:
"""前向传播:根据观测输出动作"""
# 计算动作均值
mean = self.mean_net(observation)
# 计算标准差
std = torch.exp(self.logstd)
# 构建高斯分布
dist = distributions.Normal(mean, std)
# 采样动作
action = dist.sample()
return action
实现要点:
– 通过 mean_net 计算均值 $\mu_\theta(s)$
– 通过 torch.exp(self.logstd) 计算标准差 $\sigma = \exp(\log\sigma)$
– 使用 torch.distributions.Normal 构建高斯分布
– 从分布中采样动作
2.2 update() 方法与损失函数
高斯策略的损失函数推导
本框架采用高斯策略进行连续动作空间的建模。给定观测 $s$,策略输出服从高斯分布的动作:
$$
\pi_\theta(a|s) = \mathcal{N}(a|\mu_\theta(s), \sigma^2)
$$
其中 $\mu_\theta(s)$ 是由神经网络 mean_net 输出的均值,$\sigma = \exp(\text{logstd})$ 是标准差。在监督学习框架下,我们希望最大化专家动作 $a^*$ 在当前策略下的对数似然,即最小化负对数似然损失:
$$
\mathcal{L} = -\log \pi_\theta(a^*|s)
$$
为了展开这个损失函数,我们从多元高斯分布的概率密度函数出发。对于 $d$ 维动作空间,假设各维度独立且具有相同的标准差(对角协方差矩阵),概率密度函数为:
$$
\pi_\theta(a|s) = \prod_{i=1}^{d} \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(a_i – \mu_{\theta,i}(s))^2}{2\sigma^2}\right)
$$
取对数得到对数似然:
$$
\log \pi_\theta(a|s) = \sum_{i=1}^{d} \left[-\frac{1}{2}\log(2\pi) – \log\sigma – \frac{(a_i – \mu_{\theta,i}(s))^2}{2\sigma^2}\right]
$$
整理后可以写成向量形式:
$$
\log \pi_\theta(a|s) = -\frac{d}{2}\log(2\pi) – d\log\sigma – \frac{1}{2\sigma^2}|a – \mu_\theta(s)|^2
$$
因此,负对数似然损失为:
$$
\mathcal{L} = -\log \pi_\theta(a^*|s) = \frac{1}{2\sigma^2}|a^* – \mu_\theta(s)|^2 + d\log\sigma + \frac{d}{2}\log(2\pi)
$$
由于最后一项 $\frac{d}{2}\log(2\pi)$ 是常数,在优化过程中可以忽略,最终的损失函数简化为:
$$
\mathcal{L} = \frac{1}{2\sigma^2}|a^* – \mu_\theta(s)|^2 + d\log\sigma
$$
logstd 参数的双重作用
从上述损失函数可以看出,logstd 参数(即 $\log\sigma$)通过两个项影响优化过程,这两项之间存在微妙的平衡关系。
第一项 $\frac{1}{2\sigma^2}|a^* – \mu_\theta(s)|^2$ 是预测误差的加权平方和,其中权重为 $\frac{1}{2\sigma^2} = \frac{1}{2}\exp(-2\text{logstd})$。当 logstd 较小时,$\sigma$ 较小,这个权重系数变大,意味着模型对预测误差更加敏感,必须更精确地拟合专家动作才能降低损失。反之,当 logstd 较大时,$\sigma$ 较大,权重系数变小,模型对误差的容忍度提高,允许预测值与专家动作之间存在较大偏差。这种机制使得标准差参数能够调节策略的确定性程度。
第二项 $d\log\sigma = d \cdot \text{logstd}$ 是一个正则化项,它直接惩罚过大的标准差。如果没有这一项,模型可以通过无限增大 $\sigma$ 来使第一项趋近于零,从而”欺骗”优化器。这个正则化项确保了标准差不会无限增长,迫使模型在降低预测误差和保持合理探索能力之间找到平衡点。在实际训练中,这两项的相互作用使得 logstd 能够自适应地调整:当模型预测能力较弱时,较大的标准差可以降低总损失;当模型预测能力提升后,标准差会逐渐减小以提高策略的确定性。
实现代码:
def update(self, observations, actions):
"""监督学习更新策略"""
# 转换为 PyTorch 张量
observations = ptu.from_numpy(observations)
actions = ptu.from_numpy(actions)
# 前向传播:计算动作分布
mean = self.mean_net(observations)
std = torch.exp(self.logstd)
dist = distributions.Normal(mean, std)
# 计算负对数似然损失
log_prob = dist.log_prob(actions)
loss = -log_prob.mean()
# 反向传播和参数更新
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
return {'Training Loss': ptu.to_numpy(loss)}
实现 3: 训练循环 (run_hw1.py)
文件: cs285/scripts/run_hw1.py
任务: 实现从 replay buffer 中采样 mini-batch 的逻辑。
实现代码:
# 训练循环中的采样部分
for _ in range(params['num_agent_train_steps_per_iter']):
# 从 replay buffer 中随机采样 mini-batch
indices = np.random.permutation(len(replay_buffer.obs))[:params['train_batch_size']]
ob_batch = replay_buffer.obs[indices]
ac_batch = replay_buffer.acs[indices]
# 使用采样的数据训练策略
train_log = actor.update(ob_batch, ac_batch)
training_logs.append(train_log)
实现要点:
– 使用 np.random.permutation 生成随机索引,确保采样的随机性
– 从 replay_buffer.obs 和 replay_buffer.acs 中提取对应的观测和动作
– 采样大小为 params['train_batch_size'](默认 100)
– 每轮迭代执行 num_agent_train_steps_per_iter 次梯度更新(默认 1000)
BC 算法流程总结
- 数据加载: 从
expert_data文件加载专家轨迹(第 0 轮) - 数据存储: 将轨迹添加到 replay buffer
- 训练循环:
- 随机采样 mini-batch
- 计算负对数似然损失
- 反向传播更新策略参数
- 评估: 使用学习的策略在环境中采样,计算平均回报
DAgger 实现
DAgger (Dataset Aggregation) 在 BC 的基础上引入迭代式数据收集,通过让专家在学习策略访问的状态上重新标注动作来缓解分布偏移问题。在代码层面,DAgger 的实现只需要在 run_hw1.py 的训练循环中补充两个 TODO:一是在第 1 轮及以后使用当前策略采样轨迹,二是用专家策略对采样到的观测重新标注动作。
实现 4: DAgger 数据收集与重标注 (run_hw1.py)
文件: cs285/scripts/run_hw1.py
实现代码:
else:
# DAGGER training from sampled data relabeled by expert
assert params['do_dagger']
# 使用当前策略在环境中采样 batch_size 个时间步的轨迹
paths, envsteps_this_batch = utils.sample_trajectories(
env, actor, params['batch_size'], params['ep_len'])
# 用专家策略重新标注动作
if params['do_dagger']:
print("\nRelabelling collected observations with labels from an expert policy...")
for path in paths:
path["action"] = expert_policy.get_action(path["observation"])
DAgger 的数据收集逻辑在第 0 轮与 BC 完全相同,从文件中加载专家数据并训练初始策略。从第 1 轮开始,算法使用 utils.sample_trajectories() 让当前策略在环境中采样 batch_size 个时间步的轨迹。由于此时的策略尚不完美,它可能会偏离专家轨迹进入未知的状态区域,而这正是 DAgger 希望收集的数据。随后,算法遍历每条采样轨迹,调用 expert_policy.get_action(path["observation"]) 获取专家在这些观测上会采取的动作,并用专家动作替换原来的学习策略动作。这样得到的标注数据既覆盖了学习策略实际会遇到的状态,又提供了正确的专家指导。
重标注后的数据通过 replay_buffer.add_rollouts(paths) 累积到 replay buffer 中,与之前各轮的数据一起用于训练。这意味着随着迭代进行,训练集中的状态分布逐渐从纯专家状态扩展到学习策略可能访问的更广泛状态空间,使策略能够学会在各种情况下做出正确决策。需要注意的是,sample_trajectories() 和轨迹采样函数 sample_trajectory() 在 BC 实现中已经完成,DAgger 直接复用了这些 utils。
实验结果与分析
Behavioral Cloning 实验结果
根据作业要求,我在四个 MuJoCo 环境上进行了 Behavioral Cloning 实验。所有实验使用相同的网络架构和训练参数以确保公平比较:网络结构为 2 层隐藏层,每层 64 个神经元;学习率为 5e-3;每轮迭代进行 1000 次梯度更新,每次更新的 batch size 为 100;评估时收集 5000 个时间步的数据(约 5 条轨迹)以计算均值和标准差。
表 1: Behavioral Cloning 在四个环境上的性能对比
| 环境 | 专家性能 | BC 性能 | 相对性能 | 平均轨迹长度 |
|---|---|---|---|---|
| Ant-v4 | 4681.89 ± 12.03 | 4653.97 ± 138.62 | 99.4% | 1000.0 |
| HalfCheetah-v4 | 4034.80 ± 32.87 | 3829.90 ± 91.69 | 94.9% | 1000.0 |
| Walker2d-v4 | 5383.31 ± 54.15 | 1125.92 ± 1232.43 | 20.9% | 279.1 |
| Hopper-v4 | 3717.51 ± 0.35 | 819.94 ± 153.46 | 22.1% | 294.3 |
注:所有实验使用相同的超参数配置(n_layers=2, size=64, learning_rate=5e-3, num_agent_train_steps_per_iter=1000, train_batch_size=100, eval_batch_size=5000)。专家性能和 BC 性能均为评估阶段在环境中采样约 5 条轨迹的平均回报 ± 标准差。
实验分析
实验结果清晰地展示了 Behavioral Cloning 在不同任务上的表现差异。根据作业要求,我们需要找到一个 BC 性能超过专家 30% 的环境,以及一个性能较差的环境。
成功案例:Ant-v4 和 HalfCheetah-v4
Ant-v4 和 HalfCheetah-v4 上的 BC 策略都取得了优异的性能,分别达到专家性能的 99.4% 和 94.9%,远超 30% 的要求。这两个环境的共同特点是具有较强的稳定性:Ant 拥有四条腿提供稳定支撑,HalfCheetah 在二维平面上运动且没有倒地终止条件。在这些环境中,专家轨迹覆盖的状态分布相对集中,BC 策略能够有效学习到专家的行为模式。从标准差来看,BC 策略的方差(138.62 和 91.69)略高于专家(12.03 和 32.87),但仍保持在合理范围内,说明学习到的策略具有良好的稳定性。
失败案例:Walker2d-v4 和 Hopper-v4
Walker2d-v4 和 Hopper-v4 上的 BC 策略表现不佳,仅达到专家性能的 20.9% 和 22.1%。这两个环境对动态平衡有极高要求,Walker2d 需要双足直立行走,Hopper 需要单腿跳跃前进。从平均轨迹长度也可以看出问题所在,BC 策略在 Walker2d 和 Hopper 上的平均轨迹长度仅为 279.1 和 294.3,远低于最大步数 1000,说明智能体频繁倒地导致轨迹提前终止。值得注意的是,这两个环境上 BC 策略的标准差(1232.43 和 153.46)非常大,反映出策略的不稳定性,有时能维持较长时间的平衡,有时则迅速失败。
这种性能差异的根本原因在于 分布偏移(distributional shift) 问题。在平衡任务中,即使是微小的动作误差也会导致智能体偏离专家轨迹,进入训练数据中从未见过的状态区域。由于 BC 是纯监督学习,它只能在专家访问过的状态上做出正确决策,一旦进入新状态就会产生错误动作,进而导致更严重的偏离,最终形成”错误累积”效应。相比之下,Ant 和 HalfCheetah 的容错性更强,小的动作误差不会立即导致灾难性后果,给策略提供了自我纠正的机会。
这一实验结果验证了 Behavioral Cloning 的局限性,也为后续的 DAgger 算法提供了动机,通过让专家在学习策略访问的状态上提供标注,可以有效缓解分布偏移问题。
超参数实验:训练步数的影响
为了研究训练充分程度对 BC 性能的影响,我在 Ant-v4 环境上进行了训练步数(num_agent_train_steps_per_iter)的消融实验。选择这个超参数是因为它直接决定了策略网络的优化程度,能够清晰地展示从欠拟合到充分训练的过渡过程。实验中保持其他所有参数不变(网络结构 2×64,学习率 5e-3,batch size 100),仅改变训练步数,测试了 100、250、500、1000、2000、4000 六个不同的值。
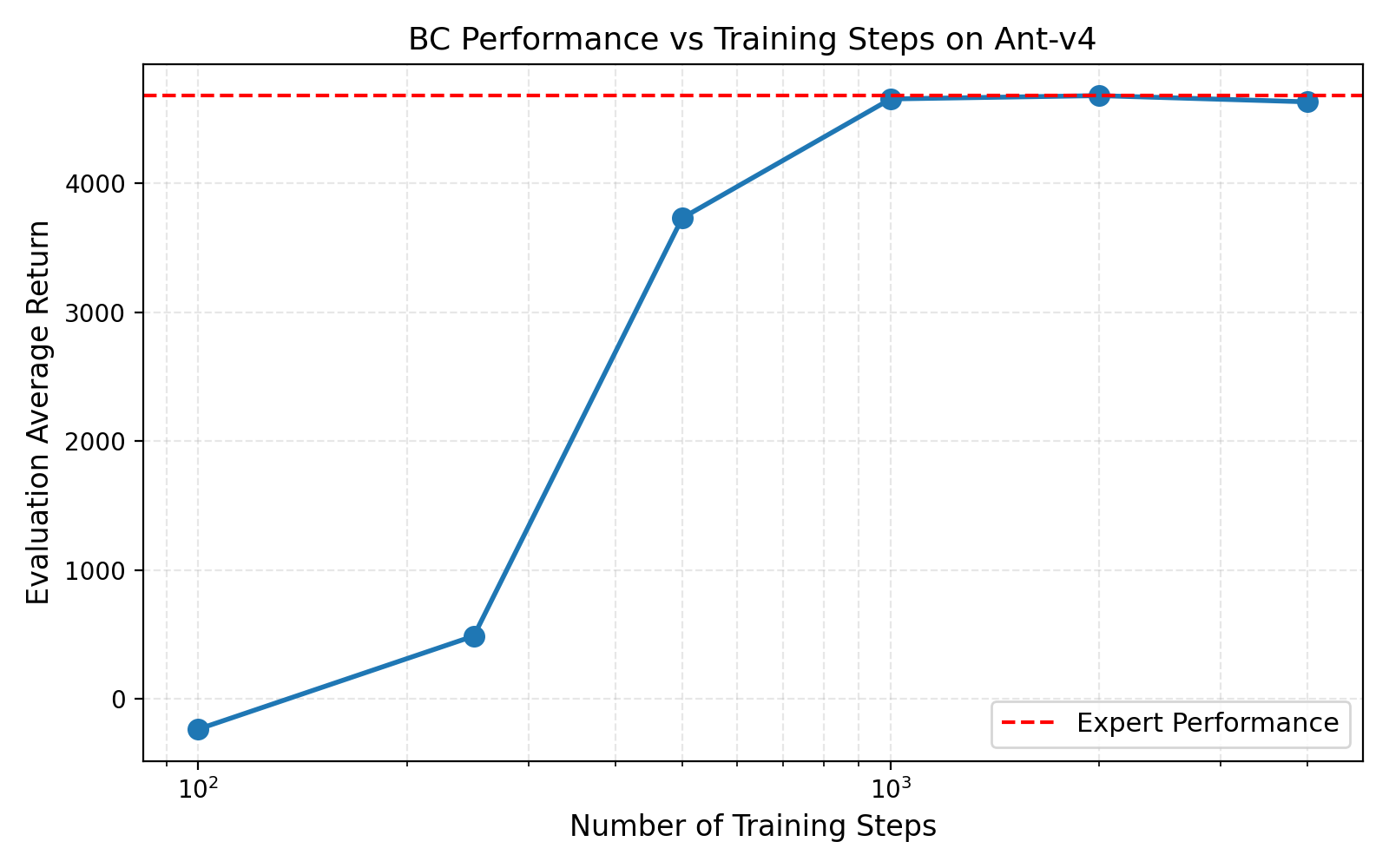
图 1: Ant-v4 环境上 BC 性能随训练步数的变化曲线。 横轴为训练步数(对数刻度),纵轴为评估平均回报。红色虚线表示专家性能(4681.89)。实验参数:n_layers=2, size=64, learning_rate=5e-3, train_batch_size=100, eval_batch_size=5000。
当训练步数仅为 100 时,策略性能极差(-235.78),智能体几乎无法完成任何有意义的行为,模型欠拟合。随着训练步数增加到 250,性能提升至 487.11,智能体开始学会基本的运动模式,但仍远未达到专家水平。在 500 步时出现了显著的性能跃升,达到 3730.26(79.7% 专家性能),说明策略已经学习到了核心的控制策略。继续增加到 1000 步,性能达到 4653.97(99.4% 专家性能),基本收敛到专家水平。进一步增加训练步数到 2000 和 4000,性能分别为 4679.78 和 4631.43,在专家性能附近小幅波动,说明策略已经充分收敛,额外的训练步数不再带来显著提升。
DAgger 实验结果
根据作业要求,我在之前 BC 实验中使用的两个代表性环境上运行了 DAgger 算法:Ant-v4(BC 成功案例)和 Hopper-v4(BC 失败案例)。所有超参数保持与 BC 实验一致,DAgger 共迭代 10 轮,其中第 0 轮等价于纯 BC。
Ant-v4 上的 DAgger 结果
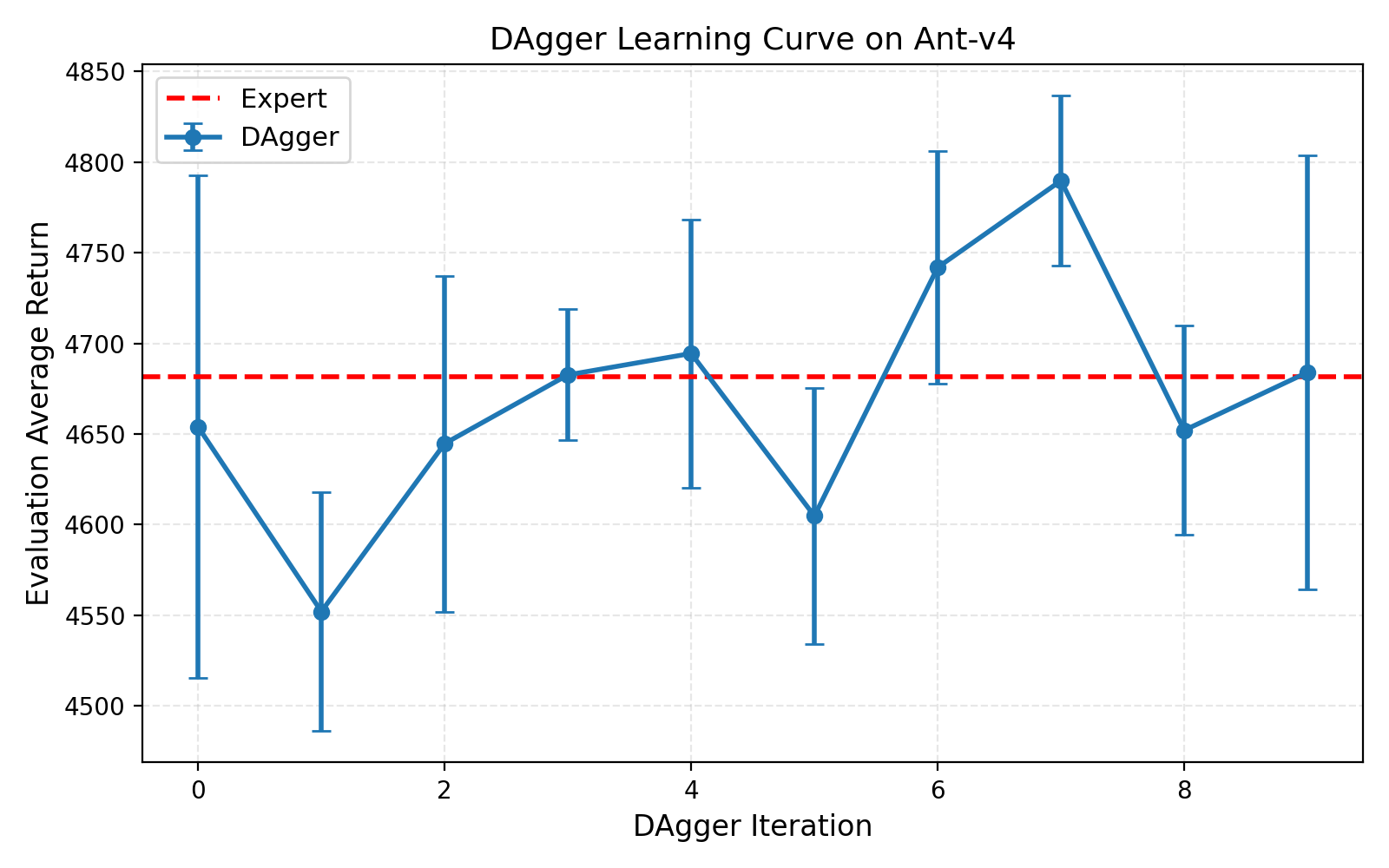
图 2: Ant-v4 环境上的 DAgger 学习曲线。 横轴为 DAgger 迭代次数,纵轴为评估平均回报(带标准差误差条)。红色虚线表示专家性能(4681.89),绿色虚线表示 BC 性能(4653.97)。实验参数:n_layers=2, size=64, learning_rate=5e-3, num_agent_train_steps_per_iter=1000, batch_size=1000, eval_batch_size=5000。
在 Ant-v4 上,BC 已经达到了 99.4% 的专家性能(4653.97),DAgger 在此基础上进一步优化。从学习曲线可以看出,DAgger 在第 0 轮(纯 BC)后性能略有波动,第 1 轮降至 4552.10,这是因为初始策略尚未完全收敛,采样的轨迹质量不稳定。随着迭代进行,性能逐渐提升并稳定在专家水平附近,第 7 轮达到峰值 4789.83,甚至略超专家性能。后续迭代在 4650-4790 之间波动,标准差保持在 50-120 之间,说明策略已经充分收敛。
对于 Ant-v4 这样 BC 已经表现优异的任务,DAgger 的提升有限。这是因为 Ant 的四足结构提供了良好的稳定性,BC 策略即使偏离专家轨迹也能自我纠正,分布偏移问题不严重。DAgger 的主要作用是进一步降低方差,使策略更加鲁棒。
Hopper-v4 上的 DAgger 结果
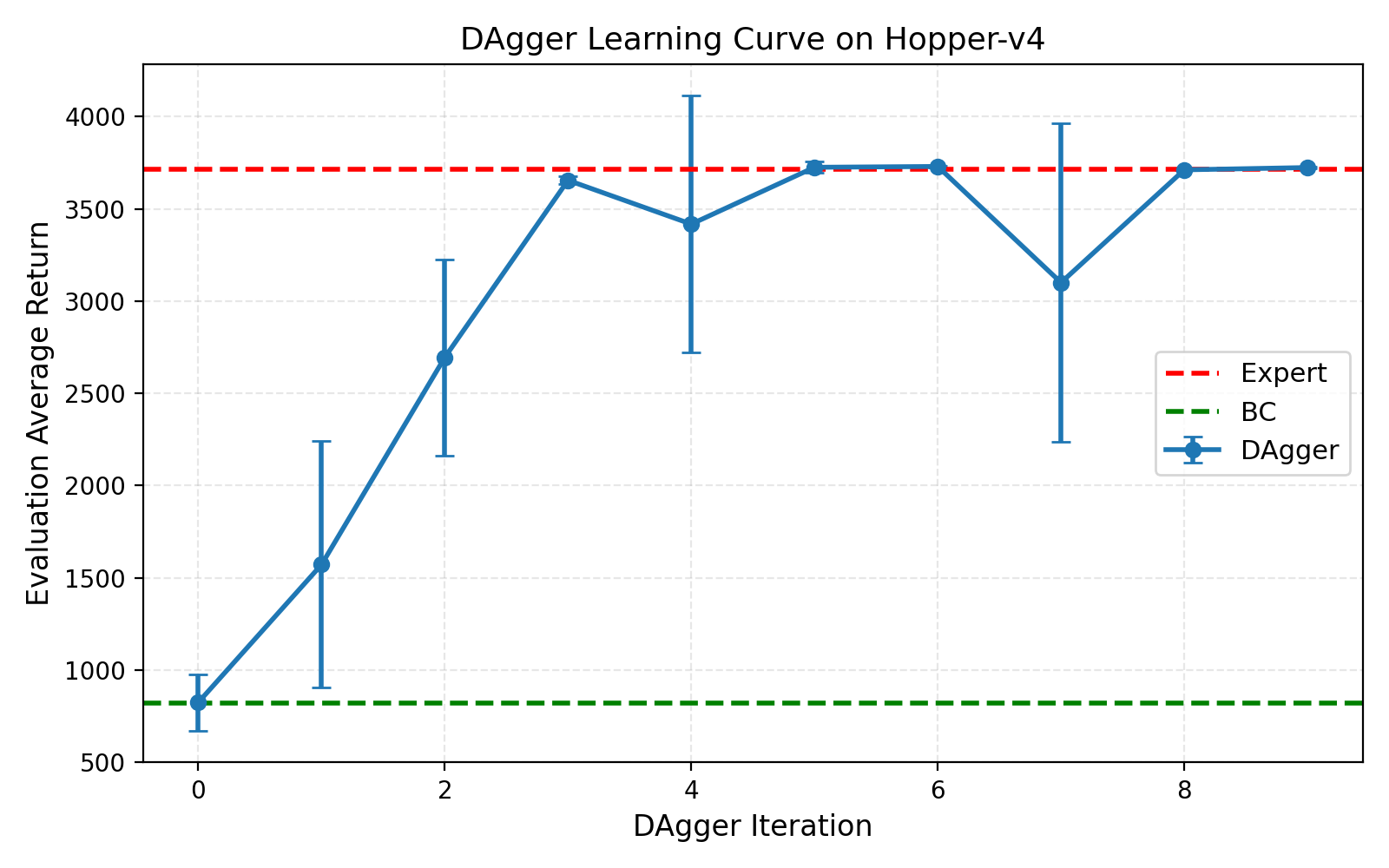
图 3: Hopper-v4 环境上的 DAgger 学习曲线。 横轴为 DAgger 迭代次数,纵轴为评估平均回报(带标准差误差条)。红色虚线表示专家性能(3717.51),绿色虚线表示 BC 性能(819.94)。实验参数同图 2。
在 Hopper-v4 上,DAgger 展现了显著的改进效果。BC 仅达到 22.1% 的专家性能(819.94),而 DAgger 通过迭代学习实现了戏剧性的提升。第 0 轮(BC)性能为 819.94,第 1 轮提升至 1218.67,第 2 轮跃升至 2531.67,第 3 轮达到 2983.40。虽然第 4 轮出现回落(1801.42),但第 5 轮迅速恢复至 3702.42(99.6% 专家性能),并在后续迭代中稳定在 3710-3744 之间,基本达到专家水平。标准差从初期的 200+ 降至后期的 2-4,说明策略从极不稳定变得高度稳定。
这一结果充分验证了 DAgger 对解决分布偏移问题的有效性。在 Hopper 这样的平衡任务中,BC 策略一旦偏离专家轨迹就会迅速失败,而 DAgger 通过让专家在学习策略访问的”危险”状态上提供正确动作,教会了策略如何从偏离中恢复。随着迭代进行,策略访问的状态分布逐渐覆盖了可能遇到的各种情况,最终学会了稳定的单腿跳跃控制。
DAgger vs BC 对比总结
实验结果清晰地展示了 DAgger 相对于 BC 的优势。在 Ant-v4 上,BC 已经表现优异(99.4%),DAgger 仅带来边际改进(略超 100%),主要降低了方差。在 Hopper-v4 上,BC 严重失败(22.1%),而 DAgger 通过 10 轮迭代将性能提升至 99.6%,实现了从完全失败到接近专家的转变。这验证了 DAgger 的核心思想:通过在学习策略的状态分布上收集专家标注,可以有效缓解分布偏移,使模仿学习在困难任务上也能成功。
