Lab 10 已经做完刚好一个周了,现在来补充一下 Lab 10 的笔记。可能部分代码的思考心路历程和 Debug 历程有所遗忘了 QAQ,重点可能就写一下自己的代码思路吧。
Lab 10 mmap 不愧是最后的大 BOSS,把 syscall、trap、page fault、kalloc/kfree(实现 VMA 的分配类似)、fork、fs 这些 Xv6 的精华内容都集成在一起了,通过这个 Lab 也正好回顾温习了整个 Xv6 的漫漫学习历程,同时也不得不与陪伴了 2 个月的 Xv6 暂时 say goodbye 了🥺。
🌟笔者的 Xv6 代码实现以及学习用到的相关文档资料请参见:GitHub 传送门⭐。
Lab 10
mmap 在现代 Linux 内核中是一个很强大的 syscall,过去的半年的时间里也与 mmap 有过交集,mmap 可以显式分配 HugePage,在 CXL 3.0 中还可以实现多机的内存共享。
这个 Lab 在 Hint 中已经提示了需要提前学习 Virtual memory for applications 这一个 Lecture,由于我希望能尽快完成实验,遂决定先不看课程了,凭借着自己对 mmap 的理解来尝试写一个自己眼中的 mmap 吧。因此整个实验是建立在我自己对 mmap 的理解上实现的,可能部分代码实现或者变量定义不够巧妙,或者不是经典的实现办法,还请读者谅解。
整个 Lab 的实现思路就是按照 Hint 一步一步完成的,因此接下来的笔记讲解的分节也是根据 Hint 来逐渐完善和实现的。
核心数据结构
实现 mmap 的核心数据结构是 Linux 中的 vm_area_struct,下面是 CSAPP 的经典好图:
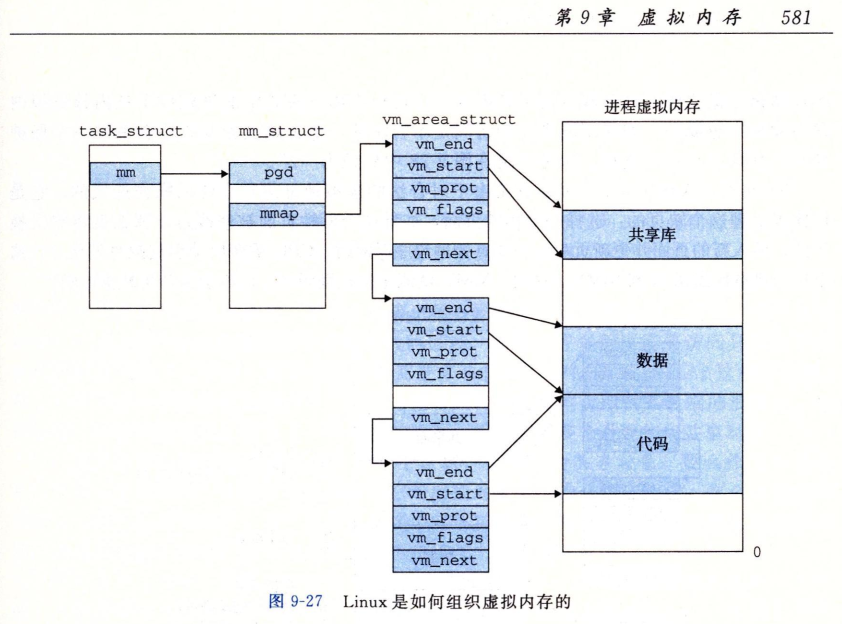
start 和 end 是一个左闭右开的区间,即 [start, end)
在 Linux 内核中,VMA 是通过红黑树以起始地址为关键字来实现快速增删改查的,在这个 Lab 实现中,我就用单链表来把 VMA 串一起就行了,因此 struct vma 的定义如下:
struct vma {
uint64 start;
uint64 end;
int prot;
int flags;
struct file *f;
uint64 offset;
struct vma *next;
};
我们把这个 VMA 以 struct vma *vma; 的形式嵌入到 struct proc 结构中。
在 Xv6 中,用户地址空间如下图所示,考虑将 unused 地址空间划给 mmap 使用,
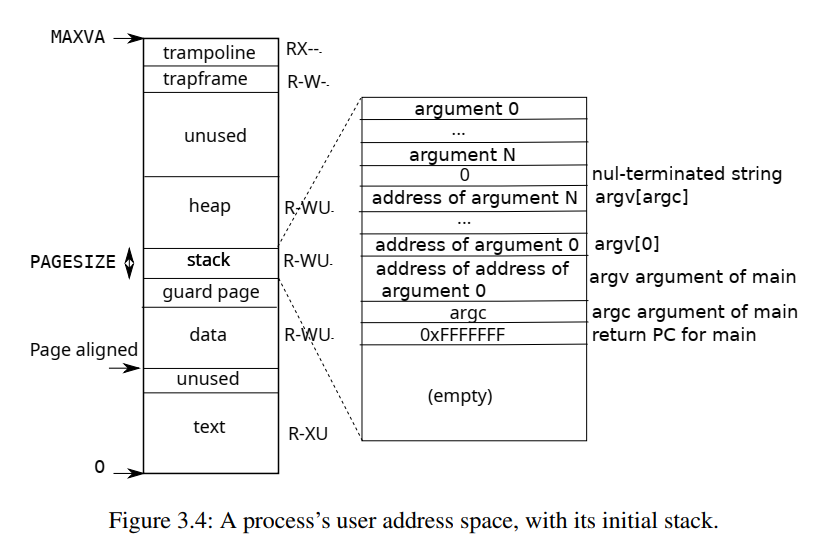
在我的实现中,我将 mmap 后的虚拟地址空间划定在 trapframe 之下(空一个页),即令 TRAPFRAME - PGSIZE 为 mmap 后的最高地址空间,mmap 的地址空间由此向下生长。
在 memlayout.h 中定义,
#define MAXVMEMMAP (TRAPFRAME - PGSIZE)
添加 syscall
在 usys.pl 中添加:
entry("mmap");
entry("munmap");
在 user.h 中添加:
void *mmap(void*, size_t, int, int, int, off_t);
int munmap(void*, size_t);
在 syscall.c 中,添加 prototype,
extern uint64 sys_mmap(void);
extern uint64 sys_munmap(void);
并完善 syscalls[] 函数指针数组:
// An array mapping syscall numbers from syscall.h
// to the function that handles the system call.
static uint64 (*syscalls[])(void) = {
[SYS_fork] sys_fork,
[SYS_exit] sys_exit,
[SYS_wait] sys_wait,
[SYS_pipe] sys_pipe,
[SYS_read] sys_read,
[SYS_kill] sys_kill,
[SYS_exec] sys_exec,
[SYS_fstat] sys_fstat,
[SYS_chdir] sys_chdir,
[SYS_dup] sys_dup,
[SYS_getpid] sys_getpid,
[SYS_sbrk] sys_sbrk,
[SYS_sleep] sys_sleep,
[SYS_uptime] sys_uptime,
[SYS_open] sys_open,
[SYS_write] sys_write,
[SYS_mknod] sys_mknod,
[SYS_unlink] sys_unlink,
[SYS_link] sys_link,
[SYS_mkdir] sys_mkdir,
[SYS_close] sys_close,
[SYS_mmap] sys_mmap,
[SYS_munmap] sys_munmap,
};
VMA 的分配与释放
需要自己实现一个 VMA 的分配与释放,这部分的实现和 kalloc/kfree 类似。
在 Hint 里已经提示了 A size of 16 should be sufficient,因此我们在 param.h 中定义,
#define NVMA 16 // maximum number of virtual memory areas
然后在 proc.c 中定义一个 VMA 对象的 pool,
struct {
struct vma _vma[NVMA];
struct vma *free_vma_list;
struct spinlock lock;
} vma;
然后编写 allocvma 和 freevma 的代码,
struct vma *
allocvma(void) {
struct vma *v;
acquire(&vma.lock);
v = vma.free_vma_list;
if (v)
vma.free_vma_list = v->next;
release(&vma.lock);
return v;
}
void
freevma(struct vma *v) {
acquire(&vma.lock);
v->next = vma.free_vma_list;
vma.free_vma_list = v;
release(&vma.lock);
}
实现 mmap 函数
切换到内核态后,需要先对用户传入的参数作校验。有几点需要注意:
- 用户可以 mmap 一个文件并写入,写入后使文件的 size 增大,因此 mmap 的范围可以超过当前文件的 size
- 如果文件没有写入权限,且是
MAP_SHARED,则不允许 - 如果文件没有写入权限,且是
MAP_PRIVATE,则允许
最后我们将这些参数转发到 mmap 主体逻辑实现。(Note:这么写是因为写到后面 fork 的时候才更改的代码结构,这样会更加方便代码复用,以及上面提到的注意点也是后来测试的时候才逐渐学习到的)
uint64
sys_mmap(void) {
// void *mmap(void *addr, size_t len, int prot, int flags,
// int fd, off_t offset);
// we assume both addr and offset are 0, so we won't use them
size_t len;
int prot, flags;
struct file *f;
struct proc *p = myproc();
argaddr(1, &len);
argint(2, &prot);
argint(3, &flags);
if (argfd(4, 0, &f) < 0) {
return -1;
}
if (flags == 0 || ((flags & MAP_PRIVATE) && (flags & MAP_SHARED))) {
return -1;
}
if (f->type != FD_INODE || f->ip->type != T_FILE
|| len == 0) { // len > f->ip->size is allowed
return -1;
}
if (((prot & PROT_READ) && !f->readable) ||
((prot & PROT_WRITE) && !f->writable && !(flags & MAP_PRIVATE))) {
return -1;
}
return mmap(p, 0, len, prot, flags, f, 0);
}
接下来是 mmap 的主体逻辑实现。当时比较纠结的地方在于,用户态传入的 len 如果不是 page-aligned 的该怎么处理才是正确的,尤其是 munmap 的时候,如果 munmap 的起始地址不是 page-aligend 的该怎么办?实际上在 man 2 munmap 可以看到,munmap 的 addr 必须是 page-aligned,但是 length 却可以不用。不过好在我查看了 mmaptest.c,测试时所有调用的起始地址和长度都是 page-aligned 的,实现的时候不用担心由于地址不对齐而产生 UB 行为(不知道该怎么实现才是正确的)。
在实现 mmap 的时候,首先新分配一个 VMA,填入相应的字段,然后把这段虚拟地址通过 mappages 映射到用户地址空间,注意,这里的页表权限仅仅设置 PTE_U,以方便后面通过 page-fault 来处理这些 mmap 后的页。最后通过 filedup 来增加文件指针引用,防止文件指针在 close 后被释放。
mmap 的主题逻辑实现代码如下:
uint64
mmap(struct proc *p, uint64 addr, size_t len, int prot, int flags,
struct file *f, off_t offset) {
struct vma *vma;
size_t len_aligned;
vma = allocvma();
if (vma == 0) {
return -1;
}
len_aligned = PGROUNDUP(len);
if (addr == 0) {
if (p->vma == 0) {
vma->end = MAXVMEMMAP;
} else {
vma->end = p->vma->start;
}
vma->start = vma->end - len_aligned;
} else {
vma->start = addr;
vma->end = addr + len_aligned;
}
vma->flags = flags;
vma->prot = prot;
vma->f = f;
vma->offset = offset;
for (addr = vma->start; addr < vma->end; addr += PGSIZE) {
if (mappages(p->pagetable, addr, PGSIZE, 0, PTE_U) != 0) {
freevma(vma);
return -1;
}
}
vma->next = p->vma;
p->vma = vma;
// duplicate the file descriptor so that
// the structure doesn't disappear when the file is closed
filedup(f);
return vma->start;
}
Page fault 处理
Page fault 这块的处理与 COW fork 有异曲同工之妙,这部分可以去参考一下之前 COW fork lab 的写法,代码结构也可以模仿一下。
在 trap 中,我们先进行一些条件判断这是不是一个合法的因为 mmap 而产生的 page fault,拿到这个 PA 对应的 PTE,然后循环遍历 proc 的 VMA 链表,找到对应的 vma,接下来的逻辑交给 do_mmap_page 来处理。
因此 usertrap 改动后的代码如下:
//
// handle an interrupt, exception, or system call from user space.
// called from trampoline.S
//
void
usertrap(void)
{
uint64 scause;
uint64 va, pa;
pte_t *pte;
struct vma *vma = 0, *iter;
int which_dev = 0, rc;
if((r_sstatus() & SSTATUS_SPP) != 0)
panic("usertrap: not from user mode");
// send interrupts and exceptions to kerneltrap(),
// since we're now in the kernel.
w_stvec((uint64)kernelvec);
struct proc *p = myproc();
// save user program counter.
p->trapframe->epc = r_sepc();
if((scause = r_scause()) == 8){
// system call
if(killed(p))
exit(-1);
// sepc points to the ecall instruction,
// but we want to return to the next instruction.
p->trapframe->epc += 4;
// an interrupt will change sepc, scause, and sstatus,
// so enable only now that we're done with those registers.
intr_on();
syscall();
} else if((which_dev = devintr()) != 0){
// ok
} else
if (scause == 12 || scause == 13 || scause == 15) {
// instruction/load/store/AMO page fault
va = r_stval();
if (va >= MAXVA)
goto KILL;
va = PGROUNDDOWN(va);
pte = walk(p->pagetable, va, 0);
if (!pte) // no page table entry for va
goto KILL;
pa = PTE2PA(*pte);
if (pa != 0) // page access permission denied
goto KILL;
for (iter = p->vma; iter; iter = iter->next) {
if (va >= iter->start && va < iter->end) {
vma = iter;
break;
}
}
if (!vma) // va is out of mmap-ed range
goto KILL;
rc = do_mmap_page(vma, va, pte);
if (rc != 0) {
printf("do_mmap_page failed: %d\n", rc);
goto KILL;
}
} else {
KILL:
printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);
printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
setkilled(p);
}
if(killed(p))
exit(-1);
// give up the CPU if this is a timer interrupt.
if(which_dev == 2)
yield();
usertrapret();
}
在 do_mmap_page 中,我们计算出正确的 offset,从文件里读取出这片页。注意:如果文件大小不够,剩余的长度部分需要 zero-fill。最后更改页表项,把这片页映射到页表里。实现代码如下:
int
do_mmap_page(struct vma *vma, uint64 addr, pte_t *pte) {
char *mem;
struct file *f;
off_t offset;
uint64 pte_flags;
int rc;
mem = kalloc();
if (mem == 0) {
return -1;
}
f = vma->f;
offset = vma->offset + (addr - vma->start);
ilock(f->ip);
if ((rc = readi(f->ip, 0, (uint64)mem, offset, PGSIZE)) < 0) {
iunlock(f->ip);
kfree(mem);
return -2;
}
iunlock(f->ip);
// zero-fill the rest of the page
if (rc < PGSIZE) {
memset(mem + rc, 0, PGSIZE - rc);
}
pte_flags = PTE_FLAGS(*pte);
pte_flags |= (vma->prot & PROT_RWX_MASK) << 1;
*pte = PA2PTE((uint64)mem) | pte_flags;
return 0;
}
实现 munmap 函数
先处理用户态传入的参数,这里就要求了 addr 必须是 page-aligned 了。然后转发到 munmap 逻辑处理,
uint64
sys_munmap(void) {
uint64 addr, start, end;
size_t len;
struct proc *p = myproc();
argaddr(0, &addr); // addr is page-aligned
argaddr(1, &len);
if (addr % PGSIZE) {
return -1;
}
start = addr;
end = PGROUNDUP(addr + len);
return munmap(p, start, end);
}
munmap 的主体逻辑实现就要复杂一些了,因为这里的一个难点涉及到单链表的一边遍历一边删除。Lab 文档已经保证了,unmap 的区间满足如下条件:
either unmap at the start, or at the end, or the whole region (but not punch a hole in the middle of a region)
翻译过来就是,只会 unmap 开头的一段区间或者结尾的一段区间,总之不会从区间中间打洞。
这部分需要循环遍历 VMA 单链表,计算出当前处理的地址区间 [l, r),如果是 MAP_SHARED,则调用 writeback 写回文件,接着调用 uvmunmap 解除映射,最后根据当前是哪一种情况(开头部分、结尾部分、整个区间)来修改 VMA。
代码实现如下:
uint64
munmap(struct proc *p, uint64 start, uint64 end) {
uint64 addr, l, r, flags;
struct vma *iter, *iter2, *prev = 0;
pte_t *pte;
for (iter = p->vma; iter;) {
l = max(start, iter->start);
r = min(end, iter->end);
if (l >= r) {
prev = iter;
iter = iter->next;
continue;
}
if (iter->flags & MAP_SHARED) {
begin_op();
for (addr = l; addr < r; addr += PGSIZE) {
pte = walk(p->pagetable, addr, 0);
flags = PTE_FLAGS(*pte);
if (flags & PTE_D) {
if (writeback(iter->f, iter->offset + addr - iter->start, addr, 1) < 0) {
end_op();
return -1;
}
}
}
end_op();
}
uvmunmap(p->pagetable, l, (r - l) / PGSIZE, 1);
if (l == iter->start && r == iter->end) {
fileclose(iter->f);
if (prev) {
prev->next = iter->next;
} else {
p->vma = iter->next;
}
iter2 = iter;
iter = iter->next;
freevma(iter2);
} else {
if (l == iter->start) {
iter->offset += r - l;
iter->start = r;
} else if (r == iter->end) {
iter->end = l;
} else {
panic("munmap: punch a hole in the middle of a region");
}
prev = iter;
iter = iter->next;
}
}
return 0;
}
文件写回 writeback 实现
这部分的实现可以参照 filewrite,但需要注意的是,在 mmap 的写回时不能更改 f->off。代码如下:
// Write back pages to file f.
// addr is a kernel address.
int
writeback(struct file *f, off_t off, uint64 addr, int nr_page) {
int r, ret = 0;
int n;
if(f->writable == 0 || f->type != FD_INODE)
return -1;
// write a few blocks at a time to avoid exceeding
// the maximum log transaction size, including
// i-node, indirect block, allocation blocks,
// and 2 blocks of slop for non-aligned writes.
// this really belongs lower down, since writei()
// might be writing a device like the console.
int max = ((MAXOPBLOCKS-1-1-2) / 2) * BSIZE;
int i = 0;
n = nr_page * PGSIZE;
while (i < n) {
int n1 = n - i;
if (n1 > max)
n1 = max;
begin_op();
ilock(f->ip);
if ((r = writei(f->ip, 1, addr + i, off, n1)) > 0)
off += r;
iunlock(f->ip);
end_op();
if(r != n1){
// error from writei
break;
}
i += r;
}
ret = (i == n ? n : -1);
return ret;
}
Exit 部分处理
有了我们之前的接口设计,exit 处理就非常简单了,只需要在 exit 中添加如下代码即可:
// unmap the process's mapped regions
if (p->vma)
munmap(p, p->vma->start, MAXVMEMMAP);
Fork 部分处理
在 fork 的时候,依次遍历父亲进程的 VMA 链表,将每一块区域都调用 mmap 到子进程中。这样就完了吗?不,由于 VMA 是每次插入链表的头部,链表尾部的映射地址最高,链表头部的映射地址最低(这条性质也是我们需要维护的,读者可以结合 mmap 思考为什么),因此我们应该反向遍历父亲进程的链表,这样才能让子进程完全模拟mmap 整个过程,映射后无论是地址空间还是 VMA 链表的顺序都会和父进程一致。但是由于我的实现采用了单链表设计,因此在这里映射完成后需要反转链表。
只需要将下面这部分代码插入 fork 代码即可:
// Map the same regions as the parent.
for (iter = p->vma; iter; iter = iter->next) {
if (mmap(np, iter->start, iter->end - iter->start,
iter->prot, iter->flags, iter->f, iter->offset) < 0) {
munmap(np, p->vma->start, MAXVMEMMAP);
freeproc(np);
release(&np->lock);
return -1;
}
}
// Reverse new process's vma list.
for (prev = 0, iter = np->vma; iter; iter = next) {
next = iter->next;
iter->next = prev;
prev = iter;
}
np->vma = prev;
至此,mmap lab 实现大功告成。
测试

完整代码
diff --git a/Makefile b/Makefile
index 8e74f52..8b658d3 100644
--- a/Makefile
+++ b/Makefile
@@ -188,6 +188,7 @@ UPROGS=\
$U/_grind\
$U/_wc\
$U/_zombie\
+ $U/_mmaptest\
diff --git a/kernel/defs.h b/kernel/defs.h
index 859fc41..9bb1c08 100644
--- a/kernel/defs.h
+++ b/kernel/defs.h
@@ -17,6 +17,9 @@ struct mbuf;
struct sock;
#endif
+#define max(a, b) ((a) > (b) ? (a) : (b))
+#define min(a, b) ((a) < (b) ? (a) : (b))
+
// bio.c
void binit(void);
struct buf* bread(uint, uint);
@@ -41,6 +44,7 @@ void fileinit(void);
int fileread(struct file*, uint64, int n);
int filestat(struct file*, uint64 addr);
int filewrite(struct file*, uint64, int n);
+int writeback(struct file*, off_t, uint64, int);
// fs.c
void fsinit(int);
@@ -103,6 +107,8 @@ void setkilled(struct proc*);
struct cpu* mycpu(void);
struct cpu* getmycpu(void);
struct proc* myproc();
+struct vma * allocvma(void);
+void freevma(struct vma *);
void procinit(void);
void scheduler(void) __attribute__((noreturn));
void sched(void);
@@ -187,6 +193,10 @@ uint64 walkaddr(pagetable_t, uint64);
int copyout(pagetable_t, uint64, char *, uint64);
int copyin(pagetable_t, char *, uint64, uint64);
int copyinstr(pagetable_t, char *, uint64, uint64);
+int do_mmap_page(struct vma*, uint64, pte_t*);
+uint64 mmap(struct proc*, uint64, size_t, int, int,
+ struct file*, off_t offset);
+uint64 munmap(struct proc*, uint64, uint64);
// plic.c
void plicinit(void);
diff --git a/kernel/fcntl.h b/kernel/fcntl.h
index 09f330a..353d3a4 100644
--- a/kernel/fcntl.h
+++ b/kernel/fcntl.h
@@ -9,6 +9,7 @@
#define PROT_READ 0x1
#define PROT_WRITE 0x2
#define PROT_EXEC 0x4
+#define PROT_RWX_MASK (PROT_READ | PROT_WRITE | PROT_EXEC)
#define MAP_SHARED 0x01
#define MAP_PRIVATE 0x02
diff --git a/kernel/file.c b/kernel/file.c
index 25fa226..240ed29 100644
--- a/kernel/file.c
+++ b/kernel/file.c
@@ -180,3 +180,45 @@ filewrite(struct file *f, uint64 addr, int n)
return ret;
}
+// Write back pages to file f.
+// addr is a kernel address.
+int
+writeback(struct file *f, off_t off, uint64 addr, int nr_page) {
+ int r, ret = 0;
+ int n;
+
+ if(f->writable == 0 || f->type != FD_INODE)
+ return -1;
+
+ // write a few blocks at a time to avoid exceeding
+ // the maximum log transaction size, including
+ // i-node, indirect block, allocation blocks,
+ // and 2 blocks of slop for non-aligned writes.
+ // this really belongs lower down, since writei()
+ // might be writing a device like the console.
+ int max = ((MAXOPBLOCKS-1-1-2) / 2) * BSIZE;
+ int i = 0;
+
+ n = nr_page * PGSIZE;
+ while (i < n) {
+ int n1 = n - i;
+ if (n1 > max)
+ n1 = max;
+
+ begin_op();
+ ilock(f->ip);
+ if ((r = writei(f->ip, 1, addr + i, off, n1)) > 0)
+ off += r;
+ iunlock(f->ip);
+ end_op();
+
+ if(r != n1){
+ // error from writei
+ break;
+ }
+ i += r;
+ }
+ ret = (i == n ? n : -1);
+
+ return ret;
+}
\ No newline at end of file
diff --git a/kernel/memlayout.h b/kernel/memlayout.h
index cac3cb1..8cc7d1c 100644
--- a/kernel/memlayout.h
+++ b/kernel/memlayout.h
@@ -62,3 +62,5 @@
// TRAPFRAME (p->trapframe, used by the trampoline)
// TRAMPOLINE (the same page as in the kernel)
#define TRAPFRAME (TRAMPOLINE - PGSIZE)
+
+#define MAXVMEMMAP (TRAPFRAME - PGSIZE)
\ No newline at end of file
diff --git a/kernel/param.h b/kernel/param.h
index 6624bff..3b99e82 100644
--- a/kernel/param.h
+++ b/kernel/param.h
@@ -1,5 +1,6 @@
#define NPROC 64 // maximum number of processes
#define NCPU 8 // maximum number of CPUs
+#define NVMA 16 // maximum number of virtual memory areas
#define NOFILE 16 // open files per process
#define NFILE 100 // open files per system
#define NINODE 50 // maximum number of active i-nodes
diff --git a/kernel/proc.c b/kernel/proc.c
index 58a8a0b..d4bd931 100644
--- a/kernel/proc.c
+++ b/kernel/proc.c
@@ -12,6 +12,12 @@ struct proc proc[NPROC];
struct proc *initproc;
+struct {
+ struct vma _vma[NVMA];
+ struct vma *free_vma_list;
+ struct spinlock lock;
+} vma;
+
int nextpid = 1;
struct spinlock pid_lock;
@@ -48,6 +54,7 @@ void
procinit(void)
{
struct proc *p;
+ int i;
initlock(&pid_lock, "nextpid");
initlock(&wait_lock, "wait_lock");
@@ -56,6 +63,12 @@ procinit(void)
p->state = UNUSED;
p->kstack = KSTACK((int) (p - proc));
}
+
+ initlock(&vma.lock, "vma");
+ for (i = 0; i < NVMA; ++i) {
+ vma._vma[i].next = vma.free_vma_list;
+ vma.free_vma_list = &vma._vma[i];
+ }
}
// Must be called with interrupts disabled,
@@ -102,6 +115,27 @@ allocpid()
return pid;
}
+struct vma *
+allocvma(void) {
+ struct vma *v;
+
+ acquire(&vma.lock);
+ v = vma.free_vma_list;
+ if (v)
+ vma.free_vma_list = v->next;
+ release(&vma.lock);
+
+ return v;
+}
+
+void
+freevma(struct vma *v) {
+ acquire(&vma.lock);
+ v->next = vma.free_vma_list;
+ vma.free_vma_list = v;
+ release(&vma.lock);
+}
+
// Look in the process table for an UNUSED proc.
// If found, initialize state required to run in the kernel,
// and return with p->lock held.
@@ -161,6 +195,7 @@ freeproc(struct proc *p)
if(p->pagetable)
proc_freepagetable(p->pagetable, p->sz);
p->pagetable = 0;
+ p->vma = 0;
p->sz = 0;
p->pid = 0;
p->parent = 0;
@@ -281,6 +316,7 @@ fork(void)
{
int i, pid;
struct proc *np;
+ struct vma *iter, *prev, *next;
struct proc *p = myproc();
// Allocate process.
@@ -296,6 +332,24 @@ fork(void)
}
np->sz = p->sz;
+ // Map the same regions as the parent.
+ for (iter = p->vma; iter; iter = iter->next) {
+ if (mmap(np, iter->start, iter->end - iter->start,
+ iter->prot, iter->flags, iter->f, iter->offset) < 0) {
+ munmap(np, p->vma->start, MAXVMEMMAP);
+ freeproc(np);
+ release(&np->lock);
+ return -1;
+ }
+ }
+ // Reverse new process's vma list.
+ for (prev = 0, iter = np->vma; iter; iter = next) {
+ next = iter->next;
+ iter->next = prev;
+ prev = iter;
+ }
+ np->vma = prev;
+
// copy saved user registers.
*(np->trapframe) = *(p->trapframe);
@@ -351,6 +405,10 @@ exit(int status)
if(p == initproc)
panic("init exiting");
+ // unmap the process's mapped regions
+ if (p->vma)
+ munmap(p, p->vma->start, MAXVMEMMAP);
+
// Close all open files.
for(int fd = 0; fd < NOFILE; fd++){
if(p->ofile[fd]){
diff --git a/kernel/proc.h b/kernel/proc.h
index d021857..133dfef 100644
--- a/kernel/proc.h
+++ b/kernel/proc.h
@@ -79,6 +79,16 @@ struct trapframe {
/* 280 */ uint64 t6;
};
+struct vma {
+ uint64 start;
+ uint64 end;
+ int prot;
+ int flags;
+ struct file *f;
+ uint64 offset;
+ struct vma *next;
+};
+
enum procstate { UNUSED, USED, SLEEPING, RUNNABLE, RUNNING, ZOMBIE };
// Per-process state
@@ -96,6 +106,7 @@ struct proc {
struct proc *parent; // Parent process
// these are private to the process, so p->lock need not be held.
+ struct vma *vma; // Virtual memory areas (for mmap)
uint64 kstack; // Virtual address of kernel stack
uint64 sz; // Size of process memory (bytes)
pagetable_t pagetable; // User page table
diff --git a/kernel/riscv.h b/kernel/riscv.h
index 20a01db..c7da5a0 100644
--- a/kernel/riscv.h
+++ b/kernel/riscv.h
@@ -343,6 +343,7 @@ typedef uint64 *pagetable_t; // 512 PTEs
#define PTE_W (1L << 2)
#define PTE_X (1L << 3)
#define PTE_U (1L << 4) // user can access
+#define PTE_D (1L << 7) // dirty
// shift a physical address to the right place for a PTE.
#define PA2PTE(pa) ((((uint64)pa) >> 12) << 10)
diff --git a/kernel/syscall.c b/kernel/syscall.c
index ed65409..4fb9baa 100644
--- a/kernel/syscall.c
+++ b/kernel/syscall.c
@@ -101,6 +101,8 @@ extern uint64 sys_unlink(void);
extern uint64 sys_link(void);
extern uint64 sys_mkdir(void);
extern uint64 sys_close(void);
+extern uint64 sys_mmap(void);
+extern uint64 sys_munmap(void);
// An array mapping syscall numbers from syscall.h
// to the function that handles the system call.
@@ -126,6 +128,8 @@ static uint64 (*syscalls[])(void) = {
[SYS_link] sys_link,
[SYS_mkdir] sys_mkdir,
[SYS_close] sys_close,
+[SYS_mmap] sys_mmap,
+[SYS_munmap] sys_munmap,
};
void
diff --git a/kernel/syscall.h b/kernel/syscall.h
index bc5f356..e7b18d6 100644
--- a/kernel/syscall.h
+++ b/kernel/syscall.h
@@ -20,3 +20,5 @@
#define SYS_link 19
#define SYS_mkdir 20
#define SYS_close 21
+#define SYS_mmap 22
+#define SYS_munmap 23
diff --git a/kernel/sysfile.c b/kernel/sysfile.c
index 16b668c..cb5c751 100644
--- a/kernel/sysfile.c
+++ b/kernel/sysfile.c
@@ -15,6 +15,7 @@
#include "sleeplock.h"
#include "file.h"
#include "fcntl.h"
+#include "memlayout.h"
// Fetch the nth word-sized system call argument as a file descriptor
// and return both the descriptor and the corresponding struct file.
@@ -503,3 +504,54 @@ sys_pipe(void)
}
return 0;
}
+
+uint64
+sys_mmap(void) {
+ // void *mmap(void *addr, size_t len, int prot, int flags,
+ // int fd, off_t offset);
+ // we assume both addr and offset are 0, so we won't use them
+ size_t len;
+ int prot, flags;
+ struct file *f;
+ struct proc *p = myproc();
+
+ argaddr(1, &len);
+ argint(2, &prot);
+ argint(3, &flags);
+ if (argfd(4, 0, &f) < 0) {
+ return -1;
+ }
+
+ if (flags == 0 || ((flags & MAP_PRIVATE) && (flags & MAP_SHARED))) {
+ return -1;
+ }
+
+ if (f->type != FD_INODE || f->ip->type != T_FILE
+ || len == 0) { // len > f->ip->size is allowed
+ return -1;
+ }
+
+ if (((prot & PROT_READ) && !f->readable) ||
+ ((prot & PROT_WRITE) && !f->writable && !(flags & MAP_PRIVATE))) {
+ return -1;
+ }
+
+ return mmap(p, 0, len, prot, flags, f, 0);
+}
+
+uint64
+sys_munmap(void) {
+ uint64 addr, start, end;
+ size_t len;
+ struct proc *p = myproc();
+
+ argaddr(0, &addr); // addr is page-aligned
+ argaddr(1, &len);
+ if (addr % PGSIZE) {
+ return -1;
+ }
+ start = addr;
+ end = PGROUNDUP(addr + len);
+
+ return munmap(p, start, end);
+}
\ No newline at end of file
diff --git a/kernel/trap.c b/kernel/trap.c
index 512c850..f555643 100644
--- a/kernel/trap.c
+++ b/kernel/trap.c
@@ -36,7 +36,11 @@ trapinithart(void)
void
usertrap(void)
{
- int which_dev = 0;
+ uint64 scause;
+ uint64 va, pa;
+ pte_t *pte;
+ struct vma *vma = 0, *iter;
+ int which_dev = 0, rc;
if((r_sstatus() & SSTATUS_SPP) != 0)
panic("usertrap: not from user mode");
@@ -50,7 +54,7 @@ usertrap(void)
// save user program counter.
p->trapframe->epc = r_sepc();
- if(r_scause() == 8){
+ if((scause = r_scause()) == 8){
// system call
if(killed(p))
@@ -67,7 +71,39 @@ usertrap(void)
syscall();
} else if((which_dev = devintr()) != 0){
// ok
+ } else
+ if (scause == 12 || scause == 13 || scause == 15) {
+ // instruction/load/store/AMO page fault
+
+ va = r_stval();
+ if (va >= MAXVA)
+ goto KILL;
+
+ va = PGROUNDDOWN(va);
+ pte = walk(p->pagetable, va, 0);
+ if (!pte) // no page table entry for va
+ goto KILL;
+
+ pa = PTE2PA(*pte);
+ if (pa != 0) // page access permission denied
+ goto KILL;
+
+ for (iter = p->vma; iter; iter = iter->next) {
+ if (va >= iter->start && va < iter->end) {
+ vma = iter;
+ break;
+ }
+ }
+ if (!vma) // va is out of mmap-ed range
+ goto KILL;
+
+ rc = do_mmap_page(vma, va, pte);
+ if (rc != 0) {
+ printf("do_mmap_page failed: %d\n", rc);
+ goto KILL;
+ }
} else {
+ KILL:
printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);
printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
setkilled(p);
diff --git a/kernel/vm.c b/kernel/vm.c
index 5c31e87..5682b4d 100644
--- a/kernel/vm.c
+++ b/kernel/vm.c
@@ -5,6 +5,11 @@
#include "riscv.h"
#include "defs.h"
#include "fs.h"
+#include "fcntl.h"
+#include "spinlock.h"
+#include "sleeplock.h"
+#include "proc.h"
+#include "file.h"
/*
* the kernel's page table.
@@ -188,11 +193,14 @@ uvmunmap(pagetable_t pagetable, uint64 va, uint64 npages, int do_free)
panic("uvmunmap: walk");
if((*pte & PTE_V) == 0)
panic("uvmunmap: not mapped");
+ // It's ok that PTE_FLAGS only has PTE_V, because the PTE
+ // hasn't been allocated a physical page yet.
if(PTE_FLAGS(*pte) == PTE_V)
panic("uvmunmap: not a leaf");
if(do_free){
uint64 pa = PTE2PA(*pte);
- kfree((void*)pa);
+ if (pa != 0)
+ kfree((void*)pa);
}
*pte = 0;
}
@@ -449,3 +457,139 @@ copyinstr(pagetable_t pagetable, char *dst, uint64 srcva, uint64 max)
return -1;
}
}
+
+int
+do_mmap_page(struct vma *vma, uint64 addr, pte_t *pte) {
+ char *mem;
+ struct file *f;
+ off_t offset;
+ uint64 pte_flags;
+ int rc;
+
+ mem = kalloc();
+ if (mem == 0) {
+ return -1;
+ }
+
+ f = vma->f;
+ offset = vma->offset + (addr - vma->start);
+ ilock(f->ip);
+ if ((rc = readi(f->ip, 0, (uint64)mem, offset, PGSIZE)) < 0) {
+ iunlock(f->ip);
+ kfree(mem);
+ return -2;
+ }
+ iunlock(f->ip);
+
+ // zero-fill the rest of the page
+ if (rc < PGSIZE) {
+ memset(mem + rc, 0, PGSIZE - rc);
+ }
+
+ pte_flags = PTE_FLAGS(*pte);
+ pte_flags |= (vma->prot & PROT_RWX_MASK) << 1;
+ *pte = PA2PTE((uint64)mem) | pte_flags;
+
+ return 0;
+}
+
+uint64
+mmap(struct proc *p, uint64 addr, size_t len, int prot, int flags,
+ struct file *f, off_t offset) {
+ struct vma *vma;
+ size_t len_aligned;
+
+ vma = allocvma();
+ if (vma == 0) {
+ return -1;
+ }
+
+ len_aligned = PGROUNDUP(len);
+ if (addr == 0) {
+ if (p->vma == 0) {
+ vma->end = MAXVMEMMAP;
+ } else {
+ vma->end = p->vma->start;
+ }
+ vma->start = vma->end - len_aligned;
+ } else {
+ vma->start = addr;
+ vma->end = addr + len_aligned;
+ }
+ vma->flags = flags;
+ vma->prot = prot;
+ vma->f = f;
+ vma->offset = offset;
+
+ for (addr = vma->start; addr < vma->end; addr += PGSIZE) {
+ if (mappages(p->pagetable, addr, PGSIZE, 0, PTE_U) != 0) {
+ freevma(vma);
+ return -1;
+ }
+ }
+
+ vma->next = p->vma;
+ p->vma = vma;
+
+ // duplicate the file descriptor so that
+ // the structure doesn't disappear when the file is closed
+ filedup(f);
+
+ return vma->start;
+}
+
+uint64
+munmap(struct proc *p, uint64 start, uint64 end) {
+ uint64 addr, l, r, flags;
+ struct vma *iter, *iter2, *prev = 0;
+ pte_t *pte;
+
+ for (iter = p->vma; iter;) {
+ l = max(start, iter->start);
+ r = min(end, iter->end);
+ if (l >= r) {
+ prev = iter;
+ iter = iter->next;
+ continue;
+ }
+ if (iter->flags & MAP_SHARED) {
+ begin_op();
+ for (addr = l; addr < r; addr += PGSIZE) {
+ pte = walk(p->pagetable, addr, 0);
+ flags = PTE_FLAGS(*pte);
+ if (flags & PTE_D) {
+ if (writeback(iter->f, iter->offset + addr - iter->start, addr, 1) < 0) {
+ end_op();
+ return -1;
+ }
+ }
+ }
+ end_op();
+ }
+ uvmunmap(p->pagetable, l, (r - l) / PGSIZE, 1);
+ if (l == iter->start && r == iter->end) {
+ fileclose(iter->f);
+ if (prev) {
+ prev->next = iter->next;
+ } else {
+ p->vma = iter->next;
+ }
+ iter2 = iter;
+ iter = iter->next;
+ freevma(iter2);
+ } else {
+ if (l == iter->start) {
+ iter->offset += r - l;
+ iter->start = r;
+ } else if (r == iter->end) {
+ iter->end = l;
+ } else {
+ panic("munmap: punch a hole in the middle of a region");
+ }
+ prev = iter;
+ iter = iter->next;
+ }
+ }
+
+ return 0;
+}
\ No newline at end of file
diff --git a/user/user.h b/user/user.h
index 2d6ace6..2fbcdd9 100644
--- a/user/user.h
+++ b/user/user.h
@@ -26,6 +26,8 @@ int getpid(void);
char* sbrk(int);
int sleep(int);
int uptime(void);
+void *mmap(void*, size_t, int, int, int, off_t);
+int munmap(void*, size_t);
#ifdef LAB_NET
int connect(uint32, uint16, uint16);
#endif
diff --git a/user/usys.pl b/user/usys.pl
index 01e426e..d23b9cc 100755
--- a/user/usys.pl
+++ b/user/usys.pl
@@ -36,3 +36,5 @@ entry("getpid");
entry("sbrk");
entry("sleep");
entry("uptime");
+entry("mmap");
+entry("munmap");
Xv6 Book Chapter
Xv6 金句摘录,以下仅记录 Xv6 book 中笔者觉得 make sense 或者有用或者自己不太熟悉的部分,其中 Chapter 10 是 Summary,只有一段话,这里就全部放出来了:
Xv6 Book Chapter 9
This is a common pattern: one lock for the set of items, plus one lock per item.
Freeing an object that is protected by a lock embedded in the object is a delicate business, since owning the lock is not enough to guarantee that freeing would be correct. The problem case arises when some other thread is waiting in acquire to use the object; freeing the object implicitly frees the embedded lock, which will cause the waiting thread to malfunction. One solution is to track how many references to the object exist, so that it is only freed when the last reference disappears.
For example, setkilled and killed (kernel/proc.c:607) lock around their simple uses of p->killed. If there were no lock, one thread could write p->killed at the same time that another thread reads it. This is a race, and the C language specification says that a race yields undefined behavior, which means the program may crash or yield incorrect results. The locks prevent the race and avoid the undefined behavior. (https://en.cppreference.com/w/c/language/memory_model)
There are two lessons here: a data object may be protected from concurrency in different ways at different points in its lifetime, and the protection may take the form of implicit structure rather than explicit locks.
It is a potential memory ordering problem (see Chapter 6), since without a memory barrier there’s no reason to expect one CPU to see another CPU’s writes.
It can be difficult to guess whether a given locking scheme might cause performance problems, or whether a new design is significantly better, so measurement on realistic workloads is often required.
Xv6 Book Chapter 10
This text introduced the main ideas in operating systems by studying one operating system, xv6, line by line. Some code lines embody the essence of the main ideas (e.g., context switching, user/kernel boundary, locks, etc.) and each line is important; other code lines provide an illustration of how to implement a particular operating system idea and could easily be done in different ways (e.g., a better algorithm for scheduling, better on-disk data structures to represent files, better logging to allow for concurrent transactions, etc.). All the ideas were illustrated in the context of one particular, very successful system call interface, the Unix interface, but those ideas carry over to the design of other operating systems.
总结
🌟笔者的 Xv6 代码实现以及学习用到的相关文档资料请参见:GitHub 传送门⭐。
2024 年 12 月 8 日,随着 mmap lab 通过,至此 Xv6 labs 2023 终于做完了🎉🎇🎈。整个 Xv6 断断续续花了两个多月的时间写完,让我对 OS 的实现有了更深刻、具体的一点点窥见。回望整个 Lab 历程,我先后完成了 CSAPP、CS144 和 MIT 6.1810,毋庸置疑这些国外经典课程都是非常优秀的,Lab 也都是经过精心构造设计的优质学习资源,但 Xv6 lab 是我个人完成度最高的 Lab。Xv6 lab 的文档非常 friendly,实验文档中有很多 Hint,基本上参照这些 Hint 就能独立完成 Lab,而 CSAPP、CS144 的一些 Labs 难度跃变很大,很多时候我都是需要先参考下前辈们的实现代码,才能自己构思实现,而 Xv6 lab 基本上可以完全闭卷写完(除了 net lab 我实在懒得去啃 Intel 的手册了)。同时 Lab 还有配套的 textbook,这也是我读完的算是第一本 English 的计算机教材吧,这个 textbook 的英语阅读难度也比较低,像我这种英语废物都能够比较舒适地阅读完。另外 Xv6 lab 还有整理好的课程内容全纪录,不想听还可以直接看文字版课程,总之这门课的资源简直不要太丰富(首尾呼应,新人入坑请见 Lab1 笔记)。

很棒!