Lab2 是学习和实现 syscall。
LEC 2 拾遗
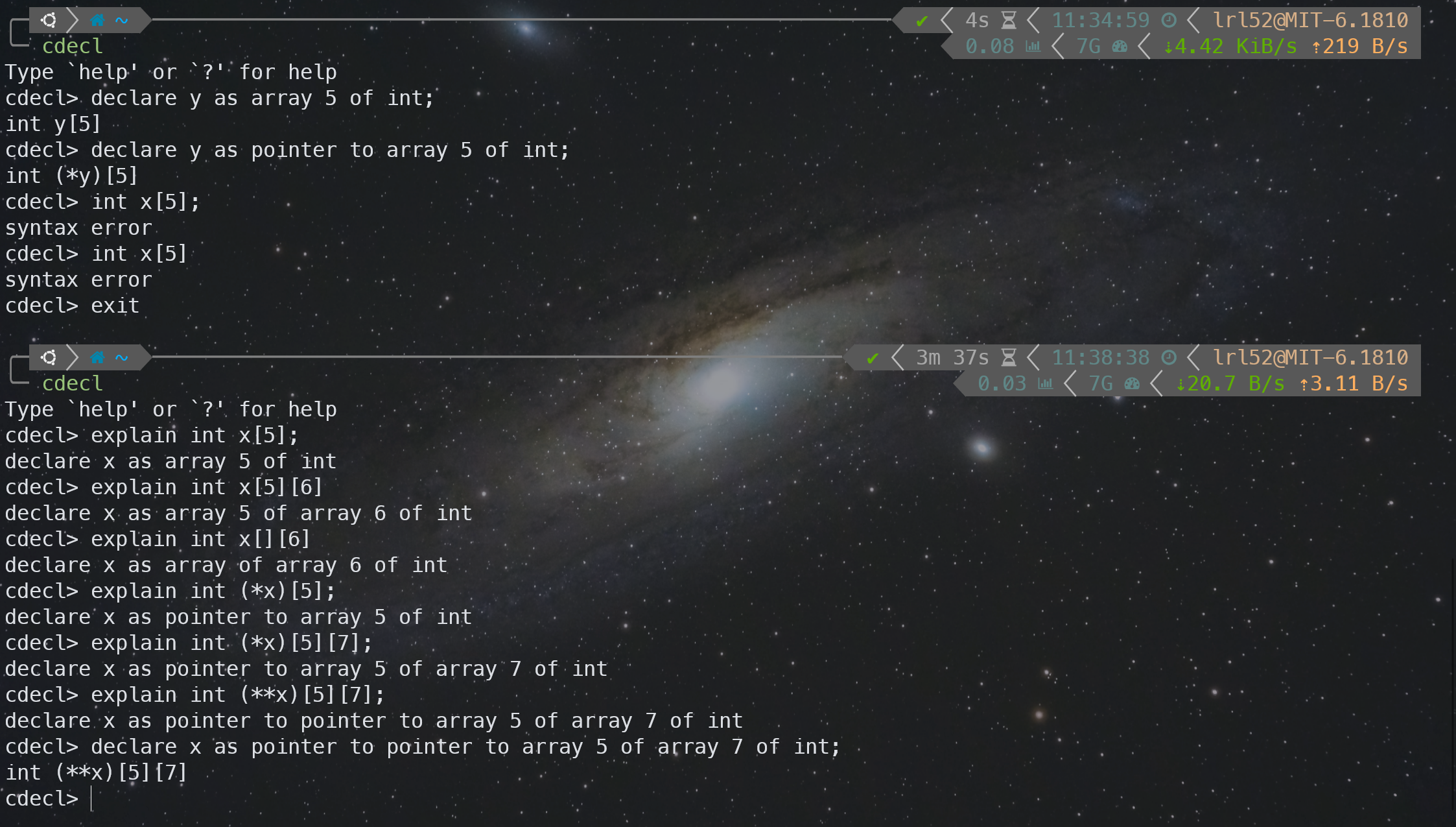
网上流传的视频都没有 LEC 2,我看了下 slides,LEC 2 主要是关于 C 语言的基础芝士。其中有一个比较有意思的内容:The Ksplice Pointer Challenge 指针挑战。
#include <stdio.h>
int main() {
int x[5];
printf("%p\n", x);
printf("%p\n", x+1);
printf("%p\n", &x);
printf("%p\n", &x+1);
return 0;
}
假设 x 数组被存储在 0x7fffdfbf7f00(64 位系统),上面这段程序的输出是什么?
前 3 个 printf 都没有什么难度,比较有意思的是最后一个 &x + 1。正确答案应该是 0x7fffdfbf7f14。
So what is the type of &x? 实际是 &x 是 pointer to array 5 of int。
有一个有趣的命令行工具cdecl可以带你了解和学习 C and C++ type declarations。
RISC-V Privileged Registers
这个 Lab 中会涉及到几个和 RISC-V 相关的特权寄存器。在完成 Lab 的过程中时不时需要翻看 riscv-privileged 手册学习,我把这个 Lab 涉及到的相关特权寄存器介绍放在这里。
RISC-V 手册中相关缩写:
- RISC-V hardware thread (hart)
- 三种 mode:
- Machine-mode (M-mode)
- Supervisor-mode (S-mode)
- User-mode (U-mode)
- MXLEN = SXLEN = UXLEN = 64,关于这部分可以查看
mstatus和misa寄存器相关位,具体可以参见手 3.1.6.3. Base ISA Control in mstatus Register 和 3.1.1. Machine ISA (misa) Register。 - 与 CSR 相关的缩写描述:
- Reserved Writes Preserve Values, Reads Ignore Values (WPRI)
- Write/Read Only Legal Values (WLRL)
- Write Any Values, Reads Legal Values (WARL)
sstatus

sstatus 是 RISC-V 架构中的一个特权寄存器,用于保存当前处理器的操作状态信息。
SPP(Supervisor Previous Privilege)
- 功能:
SPP用于指示在进入超级模式之前处理器执行的特权级别。 - 取值:
SPP = 0:陷入之前在用户模式(User Mode)执行。SPP = 1:陷入之前在超级模式(Supervisor Mode)执行。
- 陷入和返回:
- 当发生陷阱(trap)时,
SPP会被设置为0(如果陷阱来自用户模式)或者1(如果来自超级模式)。 - 当使用
SRET指令从陷阱处理程序返回时,如果SPP = 0,则返回到用户模式;如果SPP = 1,则返回到超级模式。返回之后,SPP被重置为0。
- 当发生陷阱(trap)时,
SIE(Supervisor Interrupt Enable)
- 功能:
SIE位用于控制超级模式下中断的使能或禁用。 - 取值:
SIE = 1:使能所有在超级模式下的中断。SIE = 0:禁止所有在超级模式下的中断。
- 说明:
- 当
SIE被清零时,在超级模式下不会处理任何中断。 - 在用户模式下运行时,
SIE位的值会被忽略,而超级模式级别的中断总是被使能。 - 超级模式下也可以通过单独禁用某些中断源来控制中断行为。
- 当
SPIE(Supervisor Previous Interrupt Enable)
- 功能:
SPIE位用于保存陷入超级模式之前是否启用了中断。 - 陷入和返回:
- 当发生陷入到超级模式时,
SPIE会被设置为当前SIE的值,而SIE被设置为0(即关闭中断)。 - 当执行
SRET指令返回时,SIE被设置为SPIE的值,然后SPIE被设置为1,表示在返回到之前的特权级别时中断被重新开启。
- 当发生陷入到超级模式时,
sepc

sepc 是 RISC-V 的一个特权寄存器,用于存储在发生异常时的程序计数器(PC)值。当 CPU 进入超级模式处理异常时,sepc 记录了引发异常的指令地址。它可以帮助调试,定位异常发生的具体代码位置。通过查找 sepc 的值来确定内核崩溃发生在汇编代码的哪一条指令。
scause

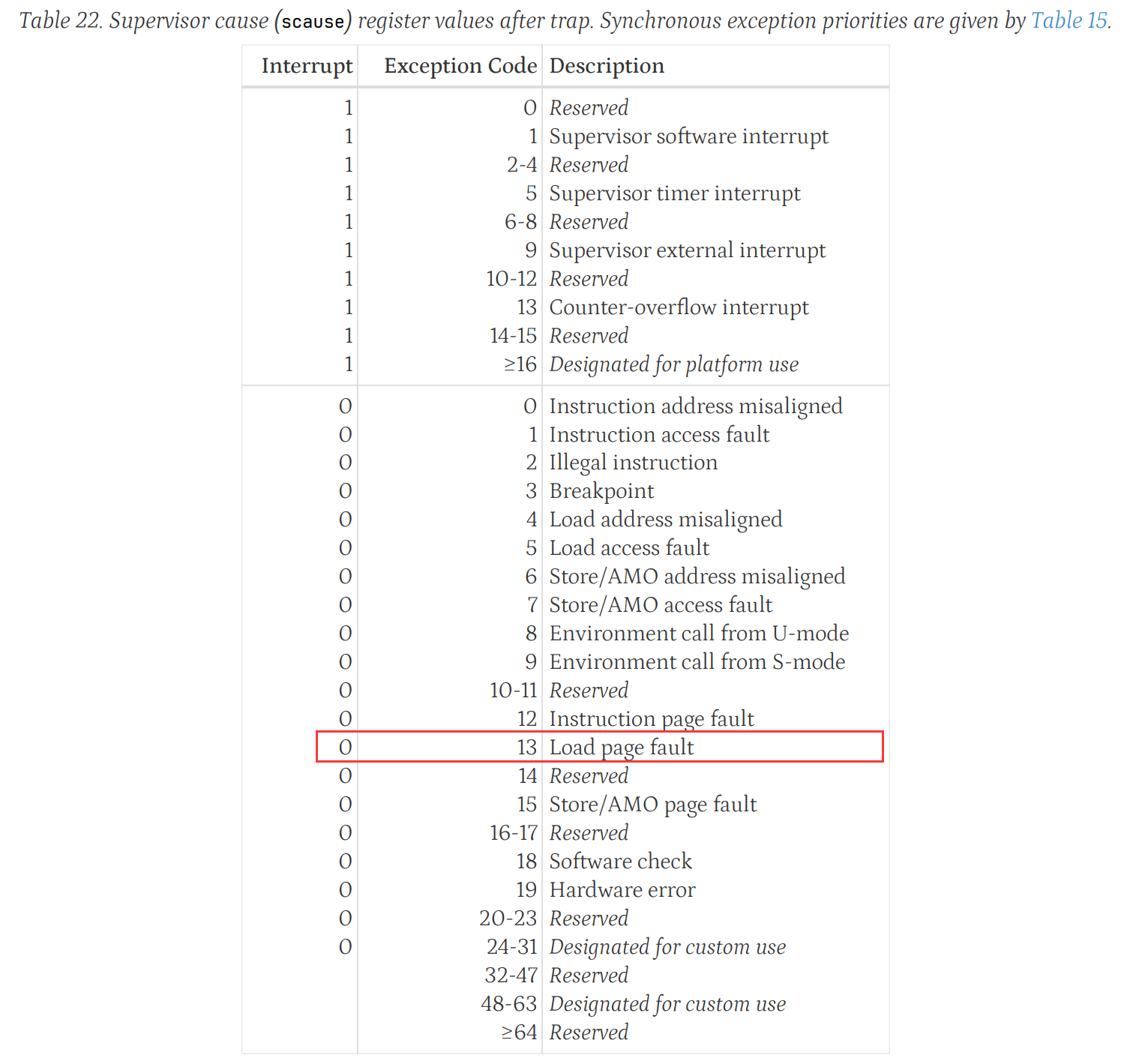
scause 是 RISC-V 的一个特权寄存器,用于存储引发异常或中断的原因。它的具体格式如下:
- 高位部分表示异常或中断的类型。
- 低位部分表示具体的异常原因编号。
对于页面故障来说,scause 的值可以帮助确定是由于非法地址访问、缺页中断等原因导致的。例如,当 scause 的值表示内存访问异常时,可以进一步确定具体是哪种类型的访问异常(如访问未映射的地址)。
stval

stval 用于在发生陷阱(trap)时存储与异常相关的特定信息,以便软件能够处理该异常。如果在指令提取、加载或存储过程中发生断点、地址未对齐、访问错误或页面错误异常时向 stval 写入非零值,则 stval 将包含错误的虚拟地址。
Lab 2
Using gdb
这里仅记录后半部分调试 panic 相关的部分,前半部分比较 trivial 就不再赘述了。
修改 kernel/syscall.c:137 以故意制造 BUG,
// num = p->trapframe->a7;
num = *(int *)1;
然后重新 make qemu 和 make qemu-gdb,可以看到 kernel 在进入 panic 之前输出了三个关键寄存器的值,
$ make qemu-gdb
*** Now run 'gdb' in another window.
qemu-system-riscv64 -machine virt -bios none -kernel kernel/kernel -m 128M -smp 3 -nographic -global virtio-mmio.force-legacy=false -drive file=fs.img,if=none,format=raw,id=x0 -device virtio-blk-device,drive=x0,bus=virtio-mmio-bus.0 -S -gdb tcp::26000
xv6 kernel is booting
hart 2 starting
hart 1 starting
scause 0x000000000000000d
sepc=0x0000000080002052 stval=0x0000000000000001
panic: kerneltrap
启动 GDB,b *0x0000000080002052,然后 c,再单步执行。我们可以查看 scause、sepc 和 stval 的值。
sepc正是我们打的 breakpoint,也是出 BUG 这行代码:num = *(int *)1;的 PCscause等于 13,查手册表格可以知道这次异常是由于 Load page fault 造成的stval等于 1,表示这次访问的错误的虚拟地址的值
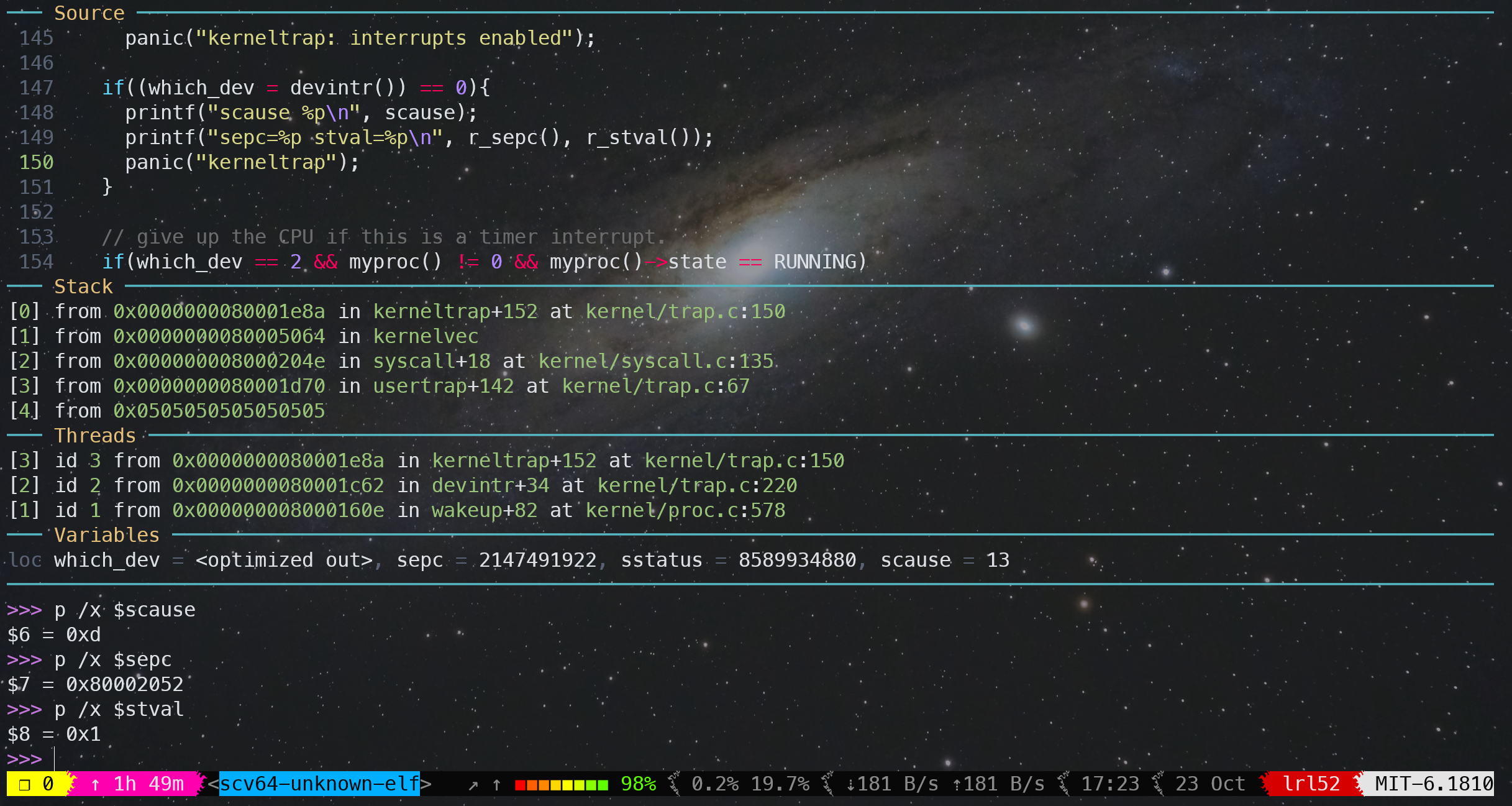
通过读懂以上信息,我们可以更方便调试和定位到代码的 BUG。
至于第 1 个进程的 name 和 pid,如下所示
>>> p p->name
$1 = "initcode\000\000\000\000\000\000\000"
>>> p p->pid
$2 = 1
System call tracing
添加一个 syscall trace,可以用于跟踪和调试系统调用。
首先,我们在 user/user.h 里添加 prototype,
diff --git a/user/user.h b/user/user.h
index 4d398d5..0bf4333 100644
--- a/user/user.h
+++ b/user/user.h
@@ -22,6 +22,7 @@ int getpid(void);
char* sbrk(int);
int sleep(int);
int uptime(void);
+int trace(int);
// ulib.c
int stat(const char*, struct stat*);
在 user/usys.pl 增添 entry,
diff --git a/user/usys.pl b/user/usys.pl
index 01e426e..9c97b05 100755
--- a/user/usys.pl
+++ b/user/usys.pl
@@ -36,3 +36,4 @@ entry("getpid");
entry("sbrk");
entry("sleep");
entry("uptime");
+entry("trace");
在 kernel/syscall.h 增加 syscall number,
diff --git a/kernel/syscall.h b/kernel/syscall.h
index bc5f356..cc112b9 100644
--- a/kernel/syscall.h
+++ b/kernel/syscall.h
@@ -20,3 +20,4 @@
#define SYS_link 19
#define SYS_mkdir 20
#define SYS_close 21
+#define SYS_trace 22
在 kernel/proc.h 里增添一个新字段,
diff --git a/kernel/proc.h b/kernel/proc.h
index d021857..5ce8a29 100644
--- a/kernel/proc.h
+++ b/kernel/proc.h
@@ -104,4 +104,5 @@ struct proc {
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
+ int trace_mask; // Trace mask
};
在 kernel/sysproc.c 里增添 sys_trace 并实现,
diff --git a/kernel/sysproc.c b/kernel/sysproc.c
index 3b4d5bd..a221c14 100644
--- a/kernel/sysproc.c
+++ b/kernel/sysproc.c
@@ -91,3 +91,15 @@ sys_uptime(void)
release(&tickslock);
return xticks;
}
+
+// trace system call
+// print out the pid, syscall name, and return value
+uint64
+sys_trace(void)
+{
+ int trace_mask;
+
+ argint(0, &trace_mask);
+ myproc()->trace_mask = trace_mask;
+ return 0;
+}
\ No newline at end of file
修改 fork() 实现将父进程的 mask 拷贝给子进程,
diff --git a/kernel/proc.c b/kernel/proc.c
index 58a8a0b..ab9974d 100644
--- a/kernel/proc.c
+++ b/kernel/proc.c
@@ -322,6 +322,9 @@ fork(void)
np->state = RUNNABLE;
release(&np->lock);
+ // copy trace_mask from parent to child
+ np->trace_mask = p->trace_mask;
+
return pid;
}
最后在 kernel/syscall.c 中输出 trace 信息,并增加 syscall_names 数组,
diff --git a/kernel/syscall.c b/kernel/syscall.c
index ed65409..73c65c3 100644
--- a/kernel/syscall.c
+++ b/kernel/syscall.c
@@ -101,6 +101,7 @@ extern uint64 sys_unlink(void);
extern uint64 sys_link(void);
extern uint64 sys_mkdir(void);
extern uint64 sys_close(void);
+extern uint64 sys_trace(void);
// An array mapping syscall numbers from syscall.h
// to the function that handles the system call.
@@ -126,6 +127,33 @@ static uint64 (*syscalls[])(void) = {
[SYS_link] sys_link,
[SYS_mkdir] sys_mkdir,
[SYS_close] sys_close,
+[SYS_trace] sys_trace,
+};
+
+// An array of syscall names, for debugging.
+static char *syscall_names[] = {
+ [SYS_fork] "fork",
+ [SYS_exit] "exit",
+ [SYS_wait] "wait",
+ [SYS_pipe] "pipe",
+ [SYS_read] "read",
+ [SYS_kill] "kill",
+ [SYS_exec] "exec",
+ [SYS_fstat] "fstat",
+ [SYS_chdir] "chdir",
+ [SYS_dup] "dup",
+ [SYS_getpid] "getpid",
+ [SYS_sbrk] "sbrk",
+ [SYS_sleep] "sleep",
+ [SYS_uptime] "uptime",
+ [SYS_open] "open",
+ [SYS_write] "write",
+ [SYS_mknod] "mknod",
+ [SYS_unlink] "unlink",
+ [SYS_link] "link",
+ [SYS_mkdir] "mkdir",
+ [SYS_close] "close",
+ [SYS_trace] "trace",
};
void
@@ -139,6 +167,12 @@ syscall(void)
// Use num to lookup the system call function for num, call it,
// and store its return value in p->trapframe->a0
p->trapframe->a0 = syscalls[num]();
+
+ // If the system call is traced, print out pid, syscall name,
+ // and return value
+ if (p->trace_mask & (1 << num)) {
+ printf("%d: syscall %s -> %d\n", p->pid, syscall_names[num], p->trapframe->a0);
+ }
} else {
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
Sysinfo
添加一个 syscall sysinfo,可以收集当前系统的运行状态信息,即剩余可用内存和当前进程数。
初次看完实验文档可能有点懵逼,这部分没有给 Hint,需要自己阅读 kalloc.c 以及 proc.c 的代码来理解 xv6 的内存块,以及 proc 数组。
xv6 会在 kinit() 中 freerange(pa_start, pa_end),在 kfree 的时候,把空闲内存块直接串到 kmem.freelist 里了,因此直接遍历 kmem.freelist 就能知道空闲内存。
xv6 中最多有 NPROC(64) 个进程,会在 procinit 中将 state 初始化为 UNUSED。xv6 的进程状态总共有 UNUSED, USED, SLEEPING, RUNNABLE, RUNNING, ZOMBIE 6 种。关于 nproc 的计算实验文档以及告诉我们了,数一下不是 UNUSED 状态的进程数即可。
实现代码如下:
diff --git a/Makefile b/Makefile
index ccf335b..0e12e1e 100644
--- a/Makefile
+++ b/Makefile
@@ -189,6 +189,7 @@ UPROGS=\
$U/_wc\
$U/_zombie\
$U/_trace\
+ $U/_sysinfotest\
diff --git a/kernel/defs.h b/kernel/defs.h
index a3c962b..3e2b171 100644
--- a/kernel/defs.h
+++ b/kernel/defs.h
@@ -63,6 +63,7 @@ void ramdiskrw(struct buf*);
void* kalloc(void);
void kfree(void *);
void kinit(void);
+uint64 calc_freemem(void);
// log.c
void initlog(int, struct superblock*);
@@ -106,6 +107,7 @@ void yield(void);
int either_copyout(int user_dst, uint64 dst, void *src, uint64 len);
int either_copyin(void *dst, int user_src, uint64 src, uint64 len);
void procdump(void);
+uint64 calc_nproc(void);
// swtch.S
void swtch(struct context*, struct context*);
diff --git a/kernel/kalloc.c b/kernel/kalloc.c
index 0699e7e..c26345d 100644
--- a/kernel/kalloc.c
+++ b/kernel/kalloc.c
@@ -80,3 +80,21 @@ kalloc(void)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
+
+// collect the amount of free memory in bytes
+uint64
+calc_freemem(void)
+{
+ struct run *r;
+ uint64 count = 0;
+
+ acquire(&kmem.lock);
+ r = kmem.freelist;
+ while(r) {
+ count += PGSIZE;
+ r = r->next;
+ }
+ release(&kmem.lock);
+
+ return count;
+}
\ No newline at end of file
diff --git a/kernel/proc.c b/kernel/proc.c
index ab9974d..34107fe 100644
--- a/kernel/proc.c
+++ b/kernel/proc.c
@@ -689,3 +689,19 @@ procdump(void)
printf("\n");
}
}
+
+
+// collect the number of processes (i.e., state
+// is not UNUSED)
+uint64
+calc_nproc(void)
+{
+ struct proc *p;
+ uint64 nproc = 0;
+
+ for (p = proc; p < &proc[NPROC]; ++p) {
+ if (p->state != UNUSED)
+ nproc++;
+ }
+ return nproc;
+}
\ No newline at end of file
diff --git a/kernel/syscall.c b/kernel/syscall.c
index 73c65c3..ec0cc23 100644
--- a/kernel/syscall.c
+++ b/kernel/syscall.c
@@ -102,6 +102,7 @@ extern uint64 sys_link(void);
extern uint64 sys_mkdir(void);
extern uint64 sys_close(void);
extern uint64 sys_trace(void);
+extern uint64 sys_sysinfo(void);
// An array mapping syscall numbers from syscall.h
// to the function that handles the system call.
@@ -128,6 +129,7 @@ static uint64 (*syscalls[])(void) = {
[SYS_mkdir] sys_mkdir,
[SYS_close] sys_close,
[SYS_trace] sys_trace,
+[SYS_sysinfo] sys_sysinfo,
};
// An array of syscall names, for debugging.
@@ -154,6 +156,7 @@ static char *syscall_names[] = {
[SYS_mkdir] "mkdir",
[SYS_close] "close",
[SYS_trace] "trace",
+ [SYS_sysinfo] "sysinfo",
};
void
diff --git a/kernel/syscall.h b/kernel/syscall.h
index cc112b9..0dfedc7 100644
--- a/kernel/syscall.h
+++ b/kernel/syscall.h
@@ -21,3 +21,4 @@
#define SYS_mkdir 20
#define SYS_close 21
#define SYS_trace 22
+#define SYS_sysinfo 23
diff --git a/kernel/sysproc.c b/kernel/sysproc.c
index a221c14..e717578 100644
--- a/kernel/sysproc.c
+++ b/kernel/sysproc.c
@@ -5,6 +5,7 @@
#include "memlayout.h"
#include "spinlock.h"
#include "proc.h"
+#include "sysinfo.h"
uint64
sys_exit(void)
@@ -102,4 +103,26 @@ sys_trace(void)
argint(0, &trace_mask);
myproc()->trace_mask = trace_mask;
return 0;
+}
+
+// collect information about the running system
+uint64
+sys_sysinfo(void)
+{
+ struct proc *p;
+ uint64 si; // user pointer to struct sysinfo
+ uint64 freemem, nproc;
+
+ p = myproc();
+ argaddr(0, &si);
+
+ freemem = calc_freemem();
+ nproc = calc_nproc();
+ if (copyout(p->pagetable, (uint64)(&((struct sysinfo*)si)->freemem),
+ (char *)&freemem, sizeof(freemem)) < 0)
+ return -1;
+ if (copyout(p->pagetable, (uint64)(&((struct sysinfo*)si)->nproc),
+ (char *)&nproc, sizeof(nproc)) < 0)
+ return -1;
+ return 0;
}
\ No newline at end of file
diff --git a/user/user.h b/user/user.h
index 0bf4333..14f69e5 100644
--- a/user/user.h
+++ b/user/user.h
@@ -1,4 +1,5 @@
struct stat;
+struct sysinfo;
// system calls
int fork(void);
@@ -23,6 +24,7 @@ char* sbrk(int);
int sleep(int);
int uptime(void);
int trace(int);
+int sysinfo(struct sysinfo*);
// ulib.c
int stat(const char*, struct stat*);
diff --git a/user/usys.pl b/user/usys.pl
index 9c97b05..bc109fd 100755
--- a/user/usys.pl
+++ b/user/usys.pl
@@ -37,3 +37,4 @@ entry("sbrk");
entry("sleep");
entry("uptime");
entry("trace");
+entry("sysinfo");
测试
Xv6 Book Chapter 2
Xv6 金句摘录,以下仅记录 Xv6 book 中笔者觉得 make sense 或者有用或者自己不太熟悉的部分:
RISC-V has three modes in which the CPU can execute instructions: machine mode, supervisor mode, and user mode.
It is important that the kernel control the entry point for transitions to supervisor mode.
关于宏内核与微内核,这部分的介绍详见 2.3 Kernel organization:
- 宏内核:One possibility is that the entire operating system resides in the kernel, so that the implementations of all system calls run in supervisor mode. This organization is called a monolithic kernel.
- Linux has a monolithic kernel, although some OS functions run as user-level servers (e.g., the windowing system)
- 微内核:To reduce the risk of mistakes in the kernel, OS designers can minimize the amount of operating system code that runs in supervisor mode, and execute the bulk of the operating system in user mode. This kernel organization is called a microkernel.
- OS services running as processes are called servers. To allow applications to interact with the file server, the kernel provides an inter-process communication(IPC) mechanism to send messages from one user-mode process to another.
Xv6 代码结构:

用户态内存布局:
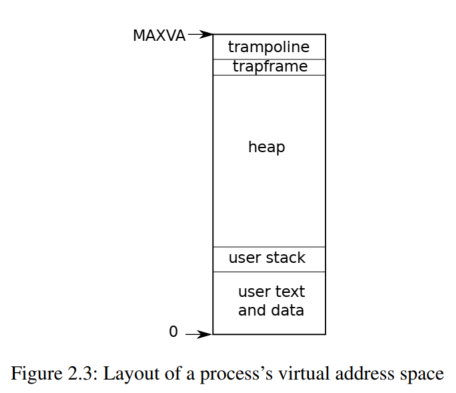
The RISC-V page table translates (or “maps”) a virtual address (the address that an RISC-V instruction manipulates) to a physical address (an address that the CPU chip sends to main memory) .
The hardware only uses the low 39 bits when looking up virtual addresses in page tables; and xv6 only uses 38 of those 39 bits. Thus, the maximum address is $2^{38}-1$ = 0x3fffffffff, which is MAXVA。(虚拟地址 38 位)
At the top of the address space xv6 reserves a page for a trampoline and a page mapping the process’s trapframe. Xv6 uses these two pages to transition into the kernel and back; the trampoline page contains the code to transition in and out of the kernel and mapping the trapframe。
Each process has two stacks: a user stack and a kernel stack (p->kstack).
In xv6, a process consists of one address space and one thread. In real operating systems a process may have more than one thread to take advantage of multiple CPUs
划重点🌟🌟🌟 2.6 Code: starting xv6, the first process and system call 这一节的内容每一句都非常重要,耐人寻味,需要对 ISA 有更深入的学习才能理解。这里不再展示了。
The kernel trap code saves user registers to the current process’s trap frame, where kernel code can find them. The kernel functions argint, argaddr, and argfd retrieve the n ’th system call argument from the trap frame as an integer, pointer, or a file descriptor.
The kernel maps each physical RAM address to the corresponding kernel virtual address(直接映射), so copyinstr can directly copy string bytes from pa0 to dst.
